
今天我们谈一谈统计机器翻译与语音识别的关系。吴军在《数学之美系列八:贾里尼克的故事和现代语言处理》中提到:
“七十年代的IBM 有点像九十年代的微软和今天的Google, 给予杰出科学家作任何有兴趣研究的自由。在那种宽松的环境里,贾里尼克等人提出了统计语音识别的框架结构。在贾里尼克以前,科学家们把语音识别问题当作人工智能问题和模式匹配问题。而贾里尼克把它当成通信问题,并用两个隐含马尔可夫模型(声学模型和语言模型)把语音识别概括得清清楚楚。这个框架结构对至今的语音和语言处理有着深远的影响,它从根本上使得语音识别有实用的可能。贾里尼克本人后来也因此当选美国工程院院士。”
贾里尼克用在语音识别上的这个框架,其影响之一就是统计机器翻译。众所周知,Brown90提出的基于信源信道模型的统计机器翻译框架,其基本思想是把机器翻译看成是一个信息传输的过程,用一种信源信道模型对机器翻译进行解释,可以看出,这个框架基本上是学习和借鉴了贾里尼克将语音识别看成通信问题的思想。以下我们具体看看Brown90中所探讨的基本问题。
在Brown90中,机器翻译的问题视作如下的过程:已知目标语言中的一个句子T,寻找翻译机(translator)在产生T时所使用的句子S,因此,选择的句子S应能尽可能的使Pr(S|T)最大。利用贝叶斯定理,可以写成:
在这个等式中,右边的分母Pr(T)并不依赖于S,因此,这个问题也等价于选择合适的S使Pr(S)Pr(T|S)最大,其中Pr(S)被称为源语言S的语言模型概率(语言模型),Pr(T|S)被称为给定S后到T的翻译概率(翻译模型),如下图所示:
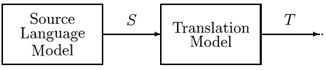
相应的,实际的翻译过程由解码器(Decoder)来执行,如下图所示:

其目标是给定目标语言句子T的情况下,选择一个源语言句子S,使:
这个公式,也被称为统计机器翻译的基本公式。如果了解语音识别,应该知道语音识别的基本公式:
其也是由贝叶斯公式推导而来。另外统计机器翻译被分解为三大问题:
1、语言模型Pr(S)的参数估计;
2、翻译模型Pr(T|S)的参数估计;
3、搜索(解码)问题:寻找最优的译文;
这三大问题也一一对应着语音识别中的语言模型,声学模型和解码问题。事实上,Brown90在具体描述这三大问题时,每一部分都与语音识别息息相关,如直接采语音识别中广泛使用的n-gram语言模型,在进行翻译模型参数估计时使用语音识别中采用的EM算法,而其搜索算法则采用语音识别中的“stack search”算法。
毫不夸张的说,Brown90中的统计机器翻译方法完全脱胎于语音识别的基本框架,语音识别这个保姆在早期统计机器翻译诞生和成长的过程中给予了SMT无微不至的关怀和照顾。
之所以有这层亲密的关系,我们可以大制了解一下Brown本人的工作环境,事实上当时他就工作在贾里尼克所在的IBM语音识别实验室里,这个实验室的研究阵容被吴军称之为空前绝后,而Brown90中的作者阵容自然也无比强大了,这个我们下一篇文章里再聊。
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/statistical-machine-translation-and-speech-recognition-of-smt-classic-brown90/