
PRML读书会第十四章 Combining Models
主讲人 网神
(新浪微博: @豆角茄子麻酱凉面)
网神(66707180) 18:57:18
大家好,今天我们讲一下第14章combining models,这一章是联合模型,通过将多个模型以某种形式结合起来,可以获得比单个模型更好的预测效果。包括这几部分:
committees, 训练多个不同的模型,取其平均值作为最终预测值。
boosting: 是committees的特殊形式,顺序训练L个模型,每个模型的训练依赖前一个模型的训练结果。
决策树:不同模型负责输入变量的不同区间的预测,每个样本选择一个模型来预测,选择过程就像在树结构中从顶到叶子的遍历。
conditional mixture model条件混合模型:引入概率机制来选择不同模型对某个样本做预测,相比决策树的硬性选择,要有很多优势。
本章主要介绍了这几种混合模型。讲之前,先明确一下混合模型与Bayesian model averaging的区别,贝叶斯模型平均是这样的:假设有H个不同模型h,每个模型的先验概率是p(h),一个数据集的分布是: 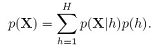
整个数据集X是由一个模型生成的,关于h的概率仅仅表示是由哪个模型来生成的 这件事的不确定性。而本章要讲的混合模型是数据集中,不同的数据点可能由不同模型生成。看后面讲到的内容就明白了。
首先看committes,committes是一大类,包括boosting,首先将最简单的形式,就是讲多个模型的预测的平均值作为最后的预测。主要讲这么做的合理性,为什么这么做会提高预测性能。从频率角度的概念,bias-variance trade-off可以解释,这个理论在3.5节讲过,我们把这个经典的图copy过来:
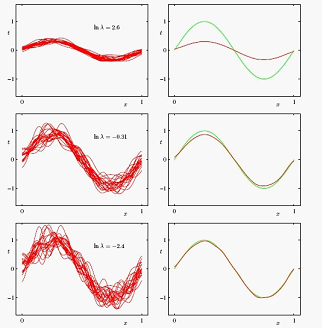
这个图大家都记得吧,左边一列是对多组数据分别训练得到一个模型,对应一条sin曲线,看左下角这个图,正则参数lamda取得比较小,得到一个bias很小,variance很大的一个模型 。每条线的variance都很大,这样模型预测的错误就比较大,但是把这么多条曲线取一个平均值,得到右下角图上的红色线,红色线跟真实sin曲线也就是蓝色线 基本拟合。所以用平均之后模型来预测,variance准确率就提高了很多,这是直观上来看,接下里从数学公式推导看下:
有一个数据集,用bootstrap方法构造M个不同的训练集bootstrap方法就是从数据集中随机选N个放到训练集中,做M次,就得到M个训练集,M个训练集训练的到M个模型,用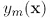 表示,那么用committees方法,对于某个x,最终预测值是:
表示,那么用committees方法,对于某个x,最终预测值是:
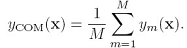
我们来看这个预测值是如何比单个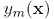 预测值准确的,假设准确的预测模型是h(x),那么训练得到的y(x)跟h(x)的关系是:
预测值准确的,假设准确的预测模型是h(x),那么训练得到的y(x)跟h(x)的关系是:
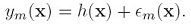
后面那一项是模型的error
ZealotMaster(850458544) 19:24:34
能使error趋近于0嘛?
网神(66707180) 19:25:13
模型越好越趋近于0,但很难等于0,这里committes方法就比单个模型更趋近于0
ZealotMaster(850458544) 19:25:28
求证明
网神(66707180) 19:25:39
正在证明,平均平方和错误如下:
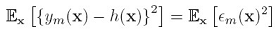
也就是单个模型的期望error是:
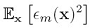
如果用M个模型分别做预测,其平均错误是:
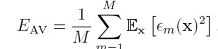
而如果用committes的结果来做预测,其期望错误是:
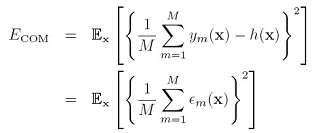
这个 跑到了平方的里面,如果假设不同模型的error都是0均值,并且互不相关,也就是:
跑到了平方的里面,如果假设不同模型的error都是0均值,并且互不相关,也就是:
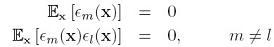
就可以得到:
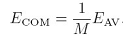
在不同模型error互不相关的假设的下,committes错误是单个模型error的1/M,但实际上,不同模型的error通常是相关的,因此error不会减少这么多,但肯定是小于单个模型的error,接下来讲boosting,可以不考虑那个假设,取得实质的提高.boosting应该是有不同的变种,其中最出名的就是AdaBoost, adaptive boosting. 它可以将多个弱分类器结合,取得很好的预测效果,所谓弱分类器就是,只要比随即预测强一点,大概就是只要准确率超50%就行吧,这是我的理解。
boosting的思想是依次预测每个分类器,每个分类器训练时,对每个数据点加一个权重。训练完一个分类器模型,该模型分错的,再下一个模型训练时,增大权重;分对的,减少权重,具体的算法如下,我把整个算法帖出来,再逐步解释:

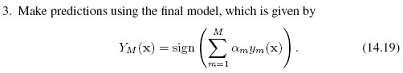
大家看下面这个图比较形象:
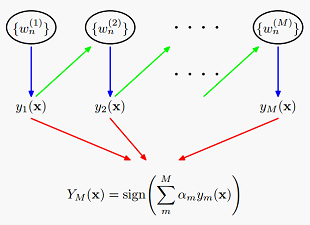
第一步,初始化每个数据点的权重为1/N.接下来依次训练M个分类器,每个分类器训练时,最小化加权的错误函数(14.15),错误函数看上面贴的算法,从这个错误函数可以看出,权重相同时,尽量让更多的x分类正确,权重不同时,优先让权重大的x分类正确,训练完一个模型后,式(14.16)计算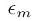 ,既分类错误的样本的加权比例. 然后式(14.17)计算:
,既分类错误的样本的加权比例. 然后式(14.17)计算:
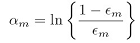
只要分类器准确率大于50%,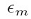 就小于0.5,
就小于0.5, 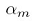 就大于0。而且
就大于0。而且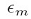 越小(既对应的分类器准确率越高),
越小(既对应的分类器准确率越高),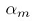 就越大,然后用
就越大,然后用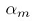 更新每个数据点的权重,即式(14.18):
更新每个数据点的权重,即式(14.18):
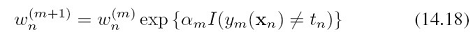
可以看出,对于分类错误的数据点,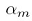 大于0,所以exp(a)就大于1,所以权重变大。但是从这个式子看不出,对于分类正确的样本,权重变小。这个式子表明,分类正确的样本,其权重不变 ,因为exp(0)=1.这是个疑问。如此循环,训练完所有模型,最后用式(14.19)做预测:
大于0,所以exp(a)就大于1,所以权重变大。但是从这个式子看不出,对于分类正确的样本,权重变小。这个式子表明,分类正确的样本,其权重不变 ,因为exp(0)=1.这是个疑问。如此循环,训练完所有模型,最后用式(14.19)做预测:
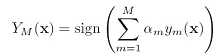
从上面过程可以看出,如果训练集合中某个样本在逐步训练每个模型时,一直被分错,他的权重就会一直变大,最后对应的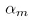 也越来越大,下面看一个图例:
也越来越大,下面看一个图例:
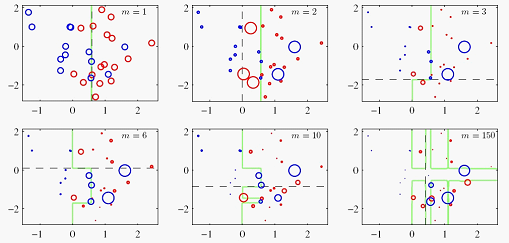
图中有蓝红两类样本 ,分类器是单个的平行于轴线的阈值 ,第一个分类器(m=1)把大部分点分对了,但有2个蓝点,3个红点不对,m=2时,这几个错的就变大了,圈越大,对应其权重越大 ,后面的分类器似乎是专门为了这个几个错分点而在努力工作,经过150个分类器,右下角那个图的分割线已经很乱了,看不出到底对不对 ,应该是都已经分对了吧。
网神(66707180) 19:59:59
@ZealotMaster 不知道是否明白点了,大家有啥问题?
ZealotMaster(850458544) 20:00:14
嗯,清晰一些了,这个也涉及over fitting嘛?感觉m=150好乱……
苦瓜炒鸡蛋(852383636) 20:02:23
是过拟合
网神(66707180) 20:02:25
不同的分割线,也就是不同的模型,是主要针对不同的点的,针对哪些点,由模型组合时的系数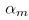 来影响。
来影响。
苦瓜炒鸡蛋(852383636) 20:04:50
这是韩家炜 那个数据挖掘书的那一段:
 网神(66707180) 20:04:56
网神(66707180) 20:04:56
嗯,这章后面也讲到了boosting对某些错分的样本反应太大,一些异常点会对模型造成很大的影响。
================================================================
接下来讲boosting的错误函数,我们仔细看下对boosting错误函数的分析,boosting最初用统计学习理论来分析器泛化错误的边界bound,但后来发现这个bound太松,没有意义。实际性能比这个理论边界好得多,后来用指数错误函数来表示。从优化指数损失函数来解释adaboost比较直观,每次固定其他分类器和系数将常量分出来,能推出单分类器的损失函数及系数,再根据常量的形式能得出下一步数据权重的更新方式。指数错误函数如下:
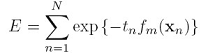
其中N是N个样本点,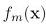 是多个线性分类器的线性组合:
是多个线性分类器的线性组合:
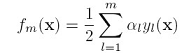
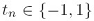 是分类的目标值。我们的目标是训练系数
是分类的目标值。我们的目标是训练系数 和分类器
和分类器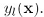 的参数,使E最小。
的参数,使E最小。
最小化E的方法,是先只针对一个分类器进行最小化,而固定其他分类器的参数,例如我们固定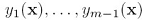 和其系数
和其系数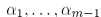 ,只针对
,只针对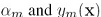 做优化,这样错误函数E可以改写为:
做优化,这样错误函数E可以改写为:
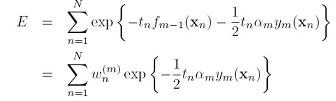
也就是把固定的分类器的部分都当做一个常量: ,只保留
,只保留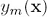 相关的部分。我们用
相关的部分。我们用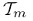 表示
表示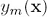 分对的数据集,
分对的数据集,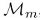 表示分错的数据集,E又可以写成如下形式:
表示分错的数据集,E又可以写成如下形式:
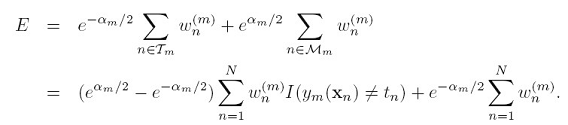 上式中,因为将数据分成两部分,也就确定了
上式中,因为将数据分成两部分,也就确定了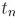 个
个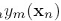 是否相等,所以消去了这两个变量
是否相等,所以消去了这两个变量
看起来清爽点了:
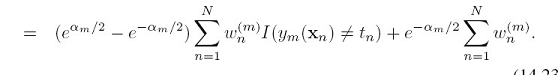
这里面后一项是常量,前一项就跟前面boosting的算法里所用的错误函数: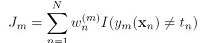 形式一样了。
形式一样了。
上面是将: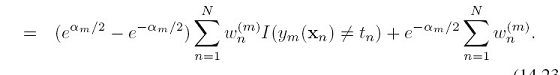 对
对 做最小化得出的结论,即指数错误函数就是boosting里求单个模型时所用的错误函数.类似,也可以得到指数错误函数里的
做最小化得出的结论,即指数错误函数就是boosting里求单个模型时所用的错误函数.类似,也可以得到指数错误函数里的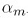 就是boosting里的
就是boosting里的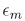 ,确定了
,确定了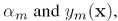 根据
根据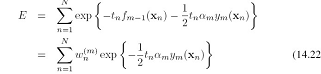 以及
以及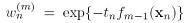
可以得到,更新w的方法:
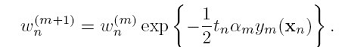
又因为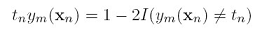 有:
有: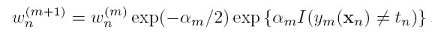 这又跟boosting里更新数据点权重的方法以一致。
这又跟boosting里更新数据点权重的方法以一致。
总之,就是想说明,用指数错误函数可以描述boosting的error分析,接下来看看指数错误函数的性质,再贴一下指数错误函数的形式:
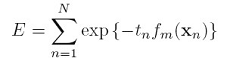
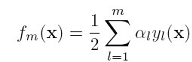
其期望error是:
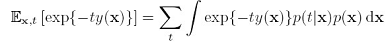
然后最所有的y(x)做variational minimization,得到: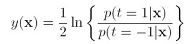
这是half the log-odds ,看下指数错误函数的图形:

绿色的线是指数错误函数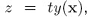 可以看到,对于分错的情况,既z<0时,绿色的线呈指数趋势上升,所以异常点会对训练结果的影响很大。图中红色的线是corss-entropy 错误,是逻辑分类中用的错误函数,对分错的情况,随错误变大,其函数值基本是线性增加的,蓝色线是svm用的错误函数,叫hinge 函数。
可以看到,对于分错的情况,既z<0时,绿色的线呈指数趋势上升,所以异常点会对训练结果的影响很大。图中红色的线是corss-entropy 错误,是逻辑分类中用的错误函数,对分错的情况,随错误变大,其函数值基本是线性增加的,蓝色线是svm用的错误函数,叫hinge 函数。
================================================================
大家有没有要讨论的?公式比较多,需要推导一下才能理解。接下来讲决策树和条件混合模型。决策树概念比较简单,容易想象是什么样子的,可以认为决策树是多个模型,每个模型负责x的一个区间的预测,通过树形结构来寻找某个x属于哪个区间,从而得到预测值。
决策树有多个算法比较出名,ID3, C4.5, CART,书上以CART为例讲的。
CART叫classification and regression trees先看一个图示:
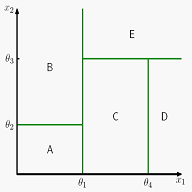
这个二维输入空间,被划分成5个区间,每个区间的类别分别是A-E,它的决策树如下,很简单明了:
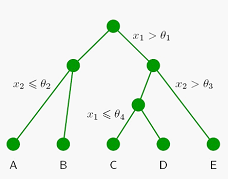
决策树在一些领域应用比较多,最主要的原因是,他有很好的可解释性。那如何训练得到一个合适的决策树呢?也就是如何决定需要哪些节点,节点上选择什么变量作为判断依据,以及判断的阈值是多大。
首先错误函数是残差的平方和,而树的结构则用贪心策略来演化。
开始只有一个节点,也就是根节点,对应整个输入空间,然后将空间划分为2,在多个划分选择之中,选择使残差最小的那个划分,书上提到这个区间划分以及划分点阈值的选择,是用穷举的方法。然后对不同的叶子节点再分别划分子区间。这样树不停长大,何时停止增加节点呢?简单的方法是当残差小于某个值的时候。但经验发现经常再往多做一些划分后,残差又可以大幅降低
所以通常的做法是,先构造一个足够大的树,使叶子节点多到某个数量,然后再剪枝,合并的原则是使叶子尽量减少,同时残差又不要增大。
也就是最小化这个值: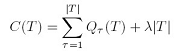 其中:
其中: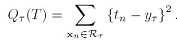
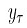 是某个叶子负责的那个区间里的所有数据点的预测值的平均值:
是某个叶子负责的那个区间里的所有数据点的预测值的平均值: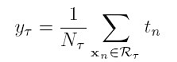
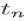 是某个数据点的预测值,
是某个数据点的预测值,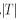 是叶子的总数,
是叶子的总数,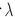 控制残差和叶子数的trade-off,这是剪枝的依据。
控制残差和叶子数的trade-off,这是剪枝的依据。
以上是针对回归说的,对于分类,剪枝依据仍然是:

只是Q(T)不再是残差的平方和,而是cross-entropy或Gini index
交叉熵的计算是:
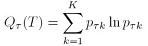
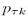 是第
是第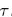 个叶子,也就是第
个叶子,也就是第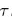 个区间里的数据点,被赋予类别k的比例。
个区间里的数据点,被赋予类别k的比例。
Gini index计算是:
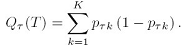
决策树的优点是直观,可解释性好。缺点是每个节点对输入空间的划分都是根据某个维度来划分的,在坐标空间里看,就是平行于某个轴来划分的,其次,决策树的划分是硬性的,在回归问题里,硬性划分更明显。
================================================================
决策树就讲这么多,接下来是conditional mixture models条件混合模型。条件混合模型,我的理解是,将不同的模型依概率来结合,这部分讲了线性回归的条件混合,逻辑回归的条件混合,和更一般性的混合方法mixture of experts,首先看线性回归的混合。
第9章讲过高斯混合模型,其模型是这样的: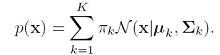
这是用多个高斯密度分布来拟合输入空间,就像这种x的分布:
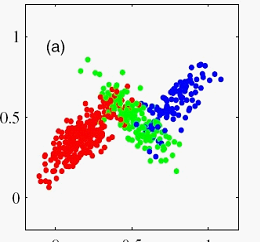
线性回归混合的实现,可以把这个高斯混合分布扩展成条件高斯分布,模型如下:

这里面,有K个线性回归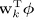 ,其权重参数是
,其权重参数是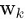 ,将多个线性回归的预测值确定的概率联合起来,得到最终预测值的概率分布。模型中的参数
,将多个线性回归的预测值确定的概率联合起来,得到最终预测值的概率分布。模型中的参数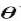 包括
包括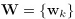
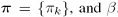 三部分,接下来看如何训练得到这些参数,总体思路是用第9章介绍的EM算法,引入一个隐藏变量
三部分,接下来看如何训练得到这些参数,总体思路是用第9章介绍的EM算法,引入一个隐藏变量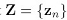 ,每个训练样本点对应一个
,每个训练样本点对应一个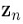 ,
,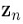 是一个K维的二元向量,
是一个K维的二元向量,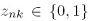 ,如果第k个模型负责生成第n个数据点,则
,如果第k个模型负责生成第n个数据点,则 等于1,否则等于0,这样,我们可以写出log似然函数:
等于1,否则等于0,这样,我们可以写出log似然函数:
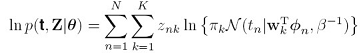
然后用EM算法结合最大似然估计来求各个参数,EM算法首先选择所有参数的初始值,假设是
在E步根据这些参数值,可以得到模型k相对于数据点n的后验概率:

书上提高一个词,这个后验概率又叫做responsibilities,大概是这个数据点n由模型k 负责生成的概率吧,有了这个responsibilities,就可以计算似然函数的期望值了,如下: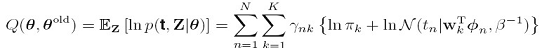
在EM的M步,我们令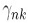 为固定值,最大化这个期望值
为固定值,最大化这个期望值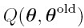 ,从而求得新的参数
,从而求得新的参数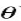
首先看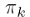 ,
,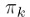 是各个模型的混合权重系数,满足
是各个模型的混合权重系数,满足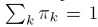 ,用拉格朗日乘子法,可以求得:
,用拉格朗日乘子法,可以求得:
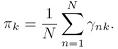
接下来求线性回归的参数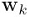 ,将似然函数期望值的式子里的高斯分布展开,可以得到如下式子:
,将似然函数期望值的式子里的高斯分布展开,可以得到如下式子:
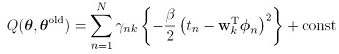
要求第k个模型的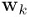 ,其他模型的W都对其没有影响,可以统统归做后面的const,这是因为log似然函数,每个模型之间是相加的关系,一求导数,其他模型的项就都消去了。上面的式子是一个加权的最小平方损失函数,每个数据点对应一个权重
,其他模型的W都对其没有影响,可以统统归做后面的const,这是因为log似然函数,每个模型之间是相加的关系,一求导数,其他模型的项就都消去了。上面的式子是一个加权的最小平方损失函数,每个数据点对应一个权重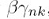 ,这个权重可以看做是数据点的有效精度,将这个式子对
,这个权重可以看做是数据点的有效精度,将这个式子对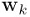 求导,可以得到:
求导,可以得到:
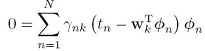
最后求得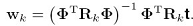
其中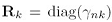 ,同样,对
,同样,对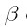 求导,得到:
求导,得到: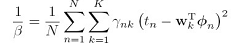
这样的到了所有的参数的新值,再重复E步和M步,迭代求得满意的最终的参数值。
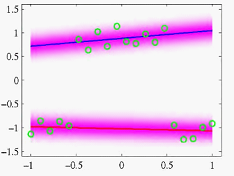
接下来看一个线性回归混合模型EM求参数的图示,两条直线对应两个线性回归模型用EM方法迭代求参数,两条直线最终拟合两部分数据点,中间和右边分别是经过了30轮和50轮迭代,下面那一排,表示每一轮里,每个数据点对应的responsibilities,也就是类k对于数据点n的后验概率:

最终求得的混合模型图示:
接下来讲逻辑回归混合模型,逻辑回归模型本身就定义了一个目标值的概率,所以可以直接用逻辑回归本身作为概率混合模型的组件,其模型如下:
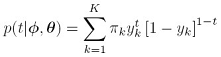
其中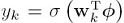 ,这里面的参数
,这里面的参数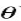 包括
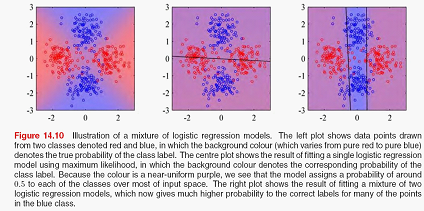
包括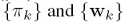 两部分。求参数的方法也是用EM,这里就不细讲了,要提一下的是在M步,似然函数不是一个closed-form的形式,不能直接求导来的出参数,需要用IRLS(iterative reweighted least squares)等迭代方法来求,下图是一个逻辑回归混合模型的训练的图示,左图是两个类别的数据,蓝色和红色表示实际的分布,中间图是用一个逻辑回归来拟合的模型,右图是用两个逻辑回归混合模型拟合的图形:
两部分。求参数的方法也是用EM,这里就不细讲了,要提一下的是在M步,似然函数不是一个closed-form的形式,不能直接求导来的出参数,需要用IRLS(iterative reweighted least squares)等迭代方法来求,下图是一个逻辑回归混合模型的训练的图示,左图是两个类别的数据,蓝色和红色表示实际的分布,中间图是用一个逻辑回归来拟合的模型,右图是用两个逻辑回归混合模型拟合的图形:
接下来讲mixtures of experts,mixture of experts是更一般化的混合模型,前面讲的两个混合模型,其混合系数是固定值,我们可以让混合系数是输入x的函数即:
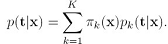
系数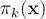 叫做gating函数,组成模型
叫做gating函数,组成模型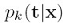 叫做experts,,每个experts可以对输入空间的不同区域建模,对不同区域的输入进行预测,而gating函数则决定一个experts该负责哪个区域。
叫做experts,,每个experts可以对输入空间的不同区域建模,对不同区域的输入进行预测,而gating函数则决定一个experts该负责哪个区域。
gating函数满足 ,因此可以用softmax函数来作为gating函数,如果expert函数也是线性函数,则整个模型就可以用EM算法来确定。在M步,可能需要用IRLS,来迭代求解,这个模型仍然有局限性,更一般化的模型是hierarchical mixture of experts
,因此可以用softmax函数来作为gating函数,如果expert函数也是线性函数,则整个模型就可以用EM算法来确定。在M步,可能需要用IRLS,来迭代求解,这个模型仍然有局限性,更一般化的模型是hierarchical mixture of experts
也就是混合模型的每个组件又可以是一个混合模型。好了就讲这么多吧,书上第14章的内容都讲完了。
注:PRML读书会系列文章由 @Nietzsche_复杂网络机器学习 同学授权发布,转载请注明原作者和相关的主讲人,谢谢。
PRML读书会讲稿PDF版本以及更多资源下载地址:http://vdisk.weibo.com/u/1841149974
本文链接地址:https://www.52nlp.cn/prml读书会第十四章-combining-models
http://credit-n.ru/zaymyi-next.html