
2. LDA-math-认识Beta/Dirichlet分布(2)
2.2 Beta-Binomial 共轭
魔鬼的第二个题目,数学上形式化一下,就是
- $X_1,X_2,\cdots,X_n {\stackrel{\mathrm{iid}}{\sim}}Uniform(0,1)$,对应的顺序统计量是 $X_{(1)},X_{(2)},\cdots, X_{(n)}$, 我们要猜测 $p=X_{(k)}$;
- $Y_1,Y_2,\cdots,Y_m {\stackrel{\mathrm{iid}}{\sim}}Uniform(0,1)$, $Y_i$中有$m_1$个比$p$小,$m_2$个比$p$大;
- 问 $P(p|Y_1,Y_2,\cdots,Y_m)$ 的分布是什么。
由于$p=X_{(k)}$在 $X_1,X_2,\cdots,X_n $中是第$k$大的,利用$Y_i$的信息,我们容易推理得到 $p=X_{(k)}$ 在$X_1,X_2,\cdots,X_n,Y_1,Y_2,\cdots,Y_m {\stackrel{\mathrm{iid}}{\sim}} Uniform(0,1)$ 这$(m+n)$个独立随机变量中是第 $k+m_1$大的,于是按照上一个小节的推理,此时$p=X_{(k)}$ 的概率密度函数是 $Beta(p|k+m_1,n-k+1+m_2)$。按照贝叶斯推理的逻辑,我们把以上过程整理如下:
- $p=X_{(k)}$是我们要猜测的参数,我们推导出 $p$ 的分布为 $f(p) = Beta(p|k,n-k+1)$,称为 $p$ 的先验分布;
- 数据$Y_i$中有$m_1$个比$p$小,$m_2$个比$p$大,$Y_i$相当于是做了$m$次贝努利实验,所以$m_1$ 服从二项分布 $B(m,p)$;
- 在给定了来自数据提供的$(m_1,m_2)$的知识后,$p$ 的后验分布变为 $f(p|m_1,m_2)=Beta(p|k+m_1,n-k+1+m_2)$
 贝努利实验
贝努利实验
我们知道贝叶斯参数估计的基本过程是
先验分布 + 数据的知识 = 后验分布
以上贝叶斯分析过程的简单直观的表述就是

其中 $(m_1,m_2)$ 对应的是二项分布$B(m_1+m_2,p)$的计数。更一般的,对于非负实数$\alpha,\beta$,我们有如下关系
\begin{equation}
Beta(p|\alpha,\beta) + Count(m_1,m_2) = Beta(p|\alpha+m_1,\beta+m_2)
\end{equation}
这个式子实际上描述的就是 Beta-Binomial 共轭,此处共轭的意思就是,数据符合二项分布的时候,参数的先验分布和后验分布都能保持Beta 分布的形式,这种形式不变的好处是,我们能够在先验分布中赋予参数很明确的物理意义,这个物理意义可以延续到后验分布中进行解释,同时从先验变换到后验过程中从数据中补充的知识也容易有物理解释。
而我们从以上过程可以看到,Beta 分布中的参数$\alpha,\beta$都可以理解为物理计数,这两个参数经常被称为伪计数(pseudo-count)。基于以上逻辑,我们也可以把$Beta(p|\alpha,\beta)$写成下式来理解
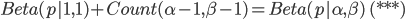
其中 $Beta(p|1,1)$ 恰好就是均匀分布Uniform(0,1)。
对于(***) 式,我们其实也可以纯粹从贝叶斯的角度来进行推导和理解。 假设有一个不均匀的硬币抛出正面的概率为$p$,抛$m$次后出现正面和反面的次数分别是$m_1,m_2$,那么按传统的频率学派观点,$p$的估计值应该为 $\hat{p}=\frac{m_1}{m}$。而从贝叶斯学派的观点来看,开始对硬币不均匀性一无所知,所以应该假设$p\sim Uniform(0,1)$, 于是有了二项分布的计数$(m_1,m_2)$
之后,按照贝叶斯公式如下计算$p$ 的后验分布
\begin{align*}
P(p|m_1,m_2) & = \frac{P(p)\cdot P(m_1,m_2|p)}{P(m_1,m_2)} \\
& = \frac{1\cdot P(m_1,m_2|p)}{\int_0^1 P(m_1,m_2|t)dt} \\
& = \frac{\binom{m}{m_1}p^{m_1}(1-p)^{m_2}}{\int_0^1 \binom{m}{m_1}t^{m_1}(1-t)^{m_2}dt} \\
& = \frac{p^{m_1}(1-p)^{m_2}}{\int_0^1 t^{m_1}(1-t)^{m_2}dt}
\end{align*}
计算得到的后验分布正好是 $Beta(p|m_1+1,m_2+1)$。
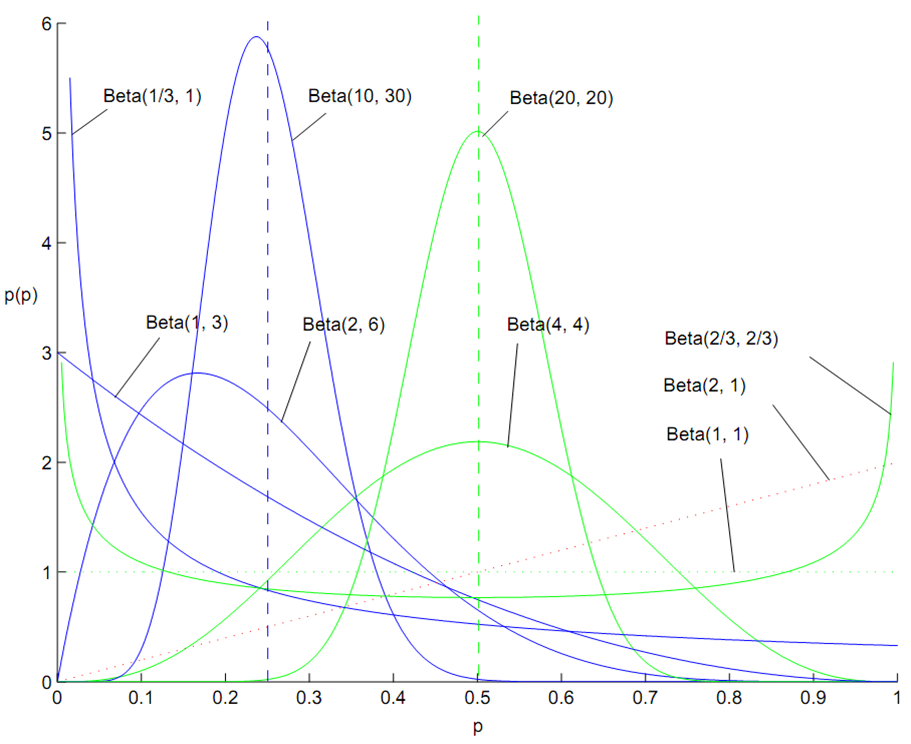
百变星君Beta分布
Beta 分布的概率密度我们把它画成图,会发现它是个百变星君,它可以是凹的、凸的、单调上升的、单调下降的;可以是曲线也可以是直线,而均匀分布也是特殊的Beta分布。由于Beta 分布能够拟合如此之多的形状,因此它在统计数据拟合中被广泛使用。
在上一个小节中,我们从二项分布推导Gamma 分布的时候,使用了如下的等式
\begin{equation}
\label{binomial-beta2}
P(C \le k) = \frac{n!}{k!(n-k-1)!} \int_p^1 t^k(1-t)^{n-k-1} dt, \quad C\sim B(n,p)
\end{equation}
现在大家可以看到,左边是二项分布的概率累积,右边实际上是$Beta(t|k+1,n-k)$ 分布的概率积分。这个式子在上一小节中并没有给出证明,下面我们利用和魔鬼的游戏类似的概率物理过程进行证明。
我们可以如下构造二项分布,取随机变量 $X_1, X_2, \cdots, X_n {\stackrel{\mathrm{iid}}{\sim}}Uniform(0,1)$,一个成功的贝努利实验就是 $X_i<p$,否则表示失败,于是成功的概率为$p$。$C$用于计数成功的次数,于是$C\sim B(n,p)$。
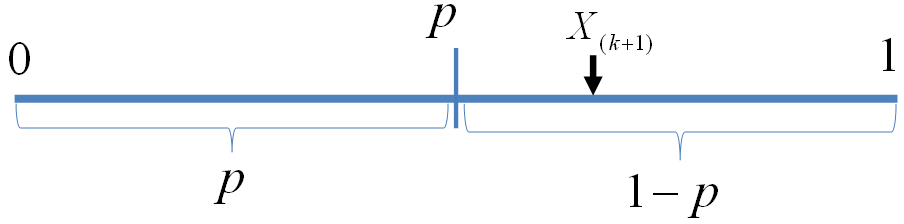
贝努利实验最多成功$k$次
显然我们有如下式子成立
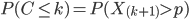
此处$X_{(k+1)}$是顺序统计量,为第$k+1$大的数。等式左边表示贝努利实验成功次数最多$k$次,右边表示第 $k+1$ 大的数必然对应于失败的贝努利实验,从而失败次数最少是$n-k$次,所以左右两边是等价的。由于$X_{(k+1)} \sim Beta(t|k+1, n-k)$, 于是
\begin{align*}
P(C \le k) & = P(X_{(k+1)} > p) \\
&= \int_p^1 Beta(t|k+1, n-k)dt \\
&= \frac{n!}{k!(n-k-1)!} \int_p^1 t^k(1-t)^{n-k-1} dt
\end{align*}
最后我们再回到魔鬼的游戏,如果你按出的5个随机数字中,魔鬼告诉你有2个小于它手中第7大的数,那么你应该
按照如下概率分布的峰值做猜测是最好的

很幸运的,你这次猜中了,魔鬼开始甩赖了:这个游戏对你来说太简单了,我要加大点难度,我们重新来一次,我按魔盒20下生成20个随机数,你同时给我猜第7大和第13大的数是什么,这时候应该如何猜测呢?
由于p=X(k)在 X1,X2,⋯,Xn中是第k大的,利用Yi的信息,我们容易推理得到 p=X(k) 在X1,X2,⋯,Xn,Y1,Y2,⋯,Ym∼iidUniform(0,1) 这(m+n)个独立随机变量中是第 k+m1大的,于是按照上一个小节的推理,此时p=X(k) 的概率密度函数是 Beta(p|k+m1,n−k+1+m2)
一共有m+n个变量,为什么到beta函数以后,变成了m+n+1个变量。概率密度函数应该是Beta(p|k+m1,n−k+m2) 而不是Beta(p|k+m1,n−k+1+m2)
[回复]
Arthur 回复:
8 1 月, 2015 at 17:33
这个没啥问题吧?本来n个数的时候,k + (n-k+1) 就应该是 n+1,本来就多1
[回复]
按照贝叶斯公式计算p的后验分布P(p|m1,m1)那个推导过程,从推导第一行到第二行过程中,P(p)为什么是1?感觉自己脑回路遇到坑了,对于某一个p值,P(p)不是应该等于无穷小么(因为只是一个点)?麻烦指教~
[回复]
C Why 回复:
9 1 月, 2019 at 00:57
P(p)不是概率,而是uniform分布的概率密度函数,在[0,1]上恒等于1.
[回复]
第一个利用思维转换直接得到概率的可以这么想:X,Y都随机出来后,恶魔告诉你Y中有m个小于第k个,问你第k个是什么,实际上等价于问X,Y排序后的第m + k个是什么?(虽然你得到的信息不一样多,但是对局计算这个概率来说这部分是多余的)
[回复]