
首先需要说明的是,本节不是这个系列的翻译,而是作为前向算法这一章的补充,希望能从实践的角度来说明前向算法。除了用程序来解读hmm的前向算法外,还希望将原文所举例子的问题拿出来和大家探讨。
文中所举的程序来自于UMDHMM这个C语言版本的HMM工具包,具体见《几种不同程序语言的HMM版本》。先说明一下UMDHMM这个包的基本情况,在linux环境下,进入umdhmm-v1.02目录,“make all”之后会产生4个可执行文件,分别是:
genseq: 利用一个给定的隐马尔科夫模型产生一个符号序列(Generates a symbol sequence using the specified model sequence using the specified model)
testfor: 利用前向算法计算log Prob(观察序列| HMM模型)(Computes log Prob(observation|model) using the Forward algorithm.)
testvit: 对于给定的观察符号序列及HMM,利用Viterbi 算法生成最可能的隐藏状态序列(Generates the most like state sequence for a given symbol sequence, given the HMM, using Viterbi)
esthmm: 对于给定的观察符号序列,利用BaumWelch算法学习隐马尔科夫模型HMM(Estimates the HMM from a given symbol sequence using BaumWelch)。
这些可执行文件需要读入有固定格式的HMM文件及观察符号序列文件,格式要求及举例如下:
HMM 文件格式:
--------------------------------------------------------------------
M= number of symbols
N= number of states
A:
a11 a12 ... a1N
a21 a22 ... a2N
. . . .
. . . .
. . . .
aN1 aN2 ... aNN
B:
b11 b12 ... b1M
b21 b22 ... b2M
. . . .
. . . .
. . . .
bN1 bN2 ... bNM
pi:
pi1 pi2 ... piN
--------------------------------------------------------------------
HMM文件举例:
--------------------------------------------------------------------
M= 2
N= 3
A:
0.333 0.333 0.333
0.333 0.333 0.333
0.333 0.333 0.333
B:
0.5 0.5
0.75 0.25
0.25 0.75
pi:
0.333 0.333 0.333
--------------------------------------------------------------------
观察序列文件格式:
--------------------------------------------------------------------
T=seqence length
o1 o2 o3 . . . oT
--------------------------------------------------------------------
观察序列文件举例:
--------------------------------------------------------------------
T= 10
1 1 1 1 2 1 2 2 2 2
--------------------------------------------------------------------
对于前向算法的测试程序testfor来说,运行:
testfor model.hmm(HMM文件) obs.seq(观察序列文件)
就可以得到观察序列的概率结果的对数值,这里我们在testfor.c的第58行对数结果的输出下再加一行输出:
fprintf(stdout, "prob(O| model) = %f\n", proba);
就可以输出运用前向算法计算观察序列所得到的概率值。至此,所有的准备工作已结束,接下来,我们将进入具体的程序解读。
首先,需要定义HMM的数据结构,也就是HMM的五个基本要素,在UMDHMM中是如下定义的(在hmm.h中):
typedef struct
{
int N; /* 隐藏状态数目;Q={1,2,...,N} */
int M; /* 观察符号数目; V={1,2,...,M}*/
double **A; /* 状态转移矩阵A[1..N][1..N]. a[i][j] 是从t时刻状态i到t+1时刻状态j的转移概率 */
double **B; /* 混淆矩阵B[1..N][1..M]. b[j][k]在状态j时观察到符合k的概率。*/
double *pi; /* 初始向量pi[1..N],pi[i] 是初始状态概率分布 */
} HMM;
前向算法程序示例如下(在forward.c中):
/*
函数参数说明:
*phmm:已知的HMM模型;T:观察符号序列长度;
*O:观察序列;**alpha:局部概率;*pprob:最终的观察概率
*/
void Forward(HMM *phmm, int T, int *O, double **alpha, double *pprob)
{
int i, j; /* 状态索引 */
int t; /* 时间索引 */
double sum; /*求局部概率时的中间值 */
/* 1. 初始化:计算t=1时刻所有状态的局部概率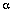 : */
: */
for (i = 1; i <= phmm->N; i++)
alpha[1][i] = phmm->pi[i]* phmm->B[i][O[1]];
/* 2. 归纳:递归计算每个时间点,t=2,... ,T时的局部概率 */
for (t = 1; t < T; t++)
{
for (j = 1; j <= phmm->N; j++)
{
sum = 0.0;
for (i = 1; i <= phmm->N; i++)
sum += alpha[t][i]* (phmm->A[i][j]);
alpha[t+1][j] = sum*(phmm->B[j][O[t+1]]);
}
}
/* 3. 终止:观察序列的概率等于T时刻所有局部概率之和*/
*pprob = 0.0;
for (i = 1; i <= phmm->N; i++)
*pprob += alpha[T][i];
}
下一节我将用这个程序来验证英文原文中所举前向算法演示例子的问题。
未完待续:前向算法5
本翻译系列原文请参考:http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/hmm-learn-best-practices-five-forward-algorithm-4
一直对HMM的前向算法不是很清楚,今天看了有点感觉了,希望再看时能弄清楚,有什么问题再向你请教。很不错的一个网站,可见主人的努力。
[回复]
admin 回复:
16 9 月, 2009 at 19:48
谢谢,欢迎常来看看!
[回复]
在VC中编译umdhmm,发现提示错误,getopt 这个函数没有定义,在linux如何编译通过?
[回复]
52nlp 回复:
8 5 月, 2010 at 22:59
GNU getopt在MS VC中是不能直接用的,要是想使用的话,考虑Stackoverflow中这个问题的答案:
http://stackoverflow.com/questions/543570/getopt-in-vc
在linux环境下,进入umdhmm-v1.02目录,直接“make all”就可以编译通过了。
[回复]
ironbridge 回复:
9 5 月, 2010 at 10:17
谢谢 回复, 解决方法和你的提示一样的,XGetopt_demo里的getopt函数就很好用。
[回复]
52nlp 回复:
9 5 月, 2010 at 15:09
不客气,刚好我也知道以后能用XGetopt了。
[...] 仍然需要说明的是,本节不是这个系列的翻译,而是作为维特比算法这一章的补充,将UMDHMM这个C语言版本的HMM工具包中的维特比算法程序展示给大家,并运行包中所附带的例子。关于UMDHMM这个工具包的介绍,大家可以参考前向算法4中的介绍。 [...]
我现在想要主修硕士,请问各位对于NATURAL PLANGUAGE PROCESSING,还有什么algorithm 可以拿来应用吗?
[回复]
52nlp 回复:
3 11 月, 2010 at 20:52
机器学习中的很多算法都可以应用,主要要看你做什么什么子方向。
[回复]
对于同一条观察序列,前向算法和后向算法得到的P值相同吗?谢谢!
[回复]
52nlp 回复:
18 3 月, 2011 at 21:23
抱歉,不太清楚!估计近似相等,可以利用开源的HMM工具验证一下。
[回复]
对多序列做HMM模型参数估计时,alpha和beta都用scale定标,不会溢出,但是在迭代估计时,Pk因子会非常小,常常溢出,请问老师用什么技术可以解决。我参考的论文是Lawrence大师1982的“A Tutorial on Hidden Markov Model and Selected Applications in Speech Recognition”,谢谢老师~!
[回复]
52nlp 回复:
12 11 月, 2011 at 08:27
抱歉迟复,这方面我没有啥经验。
[回复]
当我在cygwin下试图使用make all的时候,出现错误信息:
make: 'all' is up to date
这是什么意思呢?
[回复]
Kelp 回复:
21 11 月, 2011 at 19:50
"make clear"
[回复]
52nlp 回复:
26 11 月, 2011 at 09:58
自己动手,丰衣足食!
[回复]
不知道这穷举法和深度优先搜索有啥关系,而向前向后算法是不是就是广度优先搜索呢,感觉向前向后算法的时间复杂度也不大明白哈
[回复]
请问,为什么在linux下解压文件到根目录下,make all 显示all is up to date.
[回复]
52nlp 回复:
27 4 月, 2015 at 10:50
抱歉,好久没碰这块儿,建议你先make clean一下然后再make & make all试试
[回复]
楼主好人T_T,终于弄懂了
[回复]
佩服加感谢
[回复]