
3 LDA-math-MCMC 和 Gibbs Sampling
3.1 随机模拟
随机模拟(或者统计模拟)方法有一个很酷的别名是蒙特卡罗方法(Monte Carlo Simulation)。这个方法的发展始于20世纪40年代,和原子弹制造的曼哈顿计划密切相关,当时的几个大牛,包括乌拉姆、冯.诺依曼、费米、费曼、Nicholas Metropolis, 在美国洛斯阿拉莫斯国家实验室研究裂变物质的中子连锁反应的时候,开始使用统计模拟的方法,并在最早的计算机上进行编程实现。
 随机模拟与计算机
随机模拟与计算机
现代的统计模拟方法最早由数学家乌拉姆提出,被Metropolis命名为蒙特卡罗方法,蒙特卡罗是著名的赌场,赌博总是和统计密切关联的,所以这个命名风趣而贴切,很快被大家广泛接受。被不过据说费米之前就已经在实验中使用了,但是没有发表。说起蒙特卡罗方法的源头,可以追溯到18世纪,布丰当年用于计算$\pi$的著名的投针实验就是蒙特卡罗模拟实验。统计采样的方法其实数学家们很早就知道,但是在计算机出现以前,随机数生成的成本很高,所以该方法也没有实用价值。随着计算机技术在二十世纪后半叶的迅猛发展,随机模拟技术很快进入实用阶段。对那些用确定算法不可行或不可能解决的问题,蒙特卡罗方法常常为人们带来希望。
 蒙特卡罗方法
蒙特卡罗方法
统计模拟中有一个重要的问题就是给定一个概率分布$p(x)$,我们如何在计算机中生成它的样本。一般而言均匀分布 $Uniform(0,1)$的样本是相对容易生成的。 通过线性同余发生器可以生成伪随机数,我们用确定性算法生成$[0,1]$之间的伪随机数序列后,这些序列的各种统计指标和均匀分布 $Uniform(0,1)$ 的理论计算结果非常接近。这样的伪随机序列就有比较好的统计性质,可以被当成真实的随机数使用。
生成一个概率分布的样本
而我们常见的概率分布,无论是连续的还是离散的分布,都可以基于$Uniform(0,1)$ 的样本生成。例如正态分布可以通过著名的 Box-Muller 变换得到
[Box-Muller 变换] 如果随机变量 $U_1, U_2$ 独立且$U_1, U_2 \sim Uniform[0,1]$,
\begin{align*}
Z_0 & = \sqrt{-2\ln U_1} cos(2\pi U_2) \\
Z_1 & = \sqrt{-2\ln U_1} sin(2\pi U_2)
\end{align*}
则 $Z_0,Z_1$ 独立且服从标准正态分布。
其它几个著名的连续分布,包括指数分布、Gamma 分布、t 分布、F 分布、Beta 分布、Dirichlet 分布等等,也都可以通过类似的数学变换得到;离散的分布通过均匀分布更加容易生成。更多的统计分布如何通过均匀分布的变换生成出来,大家可以参考统计计算的书,其中 Sheldon M. Ross 的《统计模拟》是写得非常通俗易懂的一本。
不过我们并不是总是这么幸运的,当$p(x)$的形式很复杂,或者 $p(\mathbf{x})$ 是个高维的分布的时候,样本的生成就可能很困难了。 譬如有如下的情况
- $\displaystyle p(x) = \frac{\tilde{p}(x)}{\int \tilde{p}(x) dx}$,而 $\tilde{p}(x)$ 我们是可以计算的,但是底下的积分式无法显式计算。
- $p(x,y)$ 是一个二维的分布函数,这个函数本身计算很困难,但是条件分布 $p(x|y),p(y|x)$的计算相对简单;如果 $p(\mathbf{x})$ 是高维的,这种情形就更加明显。
此时就需要使用一些更加复杂的随机模拟的方法来生成样本。而本节中将要重点介绍的 MCMC(Markov Chain Monte Carlo) 和 Gibbs Sampling算法就是最常用的一种,这两个方法在现代贝叶斯分析中被广泛使用。要了解这两个算法,我们首先要对马氏链的平稳分布的性质有基本的认识。
3.2 马氏链及其平稳分布
马氏链的数学定义很简单
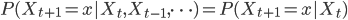
也就是状态转移的概率只依赖于前一个状态。
我们先来看马氏链的一个具体的例子。社会学家经常把人按其经济状况分成3类:下层(lower-class)、中层(middle-class)、上层(upper-class),我们用1,2,3 分别代表这三个阶层。社会学家们发现决定一个人的收入阶层的最重要的因素就是其父母的收入阶层。如果一个人的收入属于下层类别,那么他的孩子属于下层收入的概率是 0.65, 属于中层收入的概率是 0.28, 属于上层收入的概率是 0.07。事实上,从父代到子代,收入阶层的变化的转移概率如下
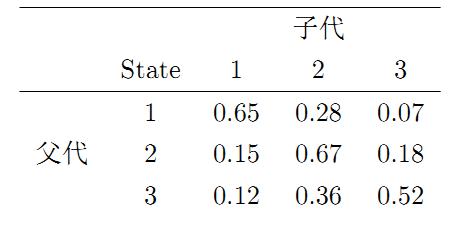
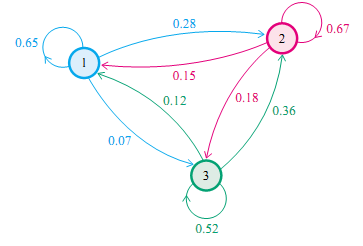
使用矩阵的表示方式,转移概率矩阵记为
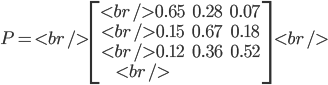
假设当前这一代人处在下层、中层、上层的人的比例是概率分布向量 $\pi_0=[\pi_0(1), \pi_0(2), \pi_0(3)]$,那么他们的子女的分布比例将是 $\pi_1=\pi_0P$, 他们的孙子代的分布比例将是 $\pi_2 = \pi_1P=\pi_0P^2$, ......, 第$n$代子孙的收入分布比例将是 $\pi_n = \pi_{n-1}P = \pi_0P^n$。
假设初始概率分布为$\pi_0 = [0.21,0.68,0.11] $,则我们可以计算前$n$代人的分布状况如下
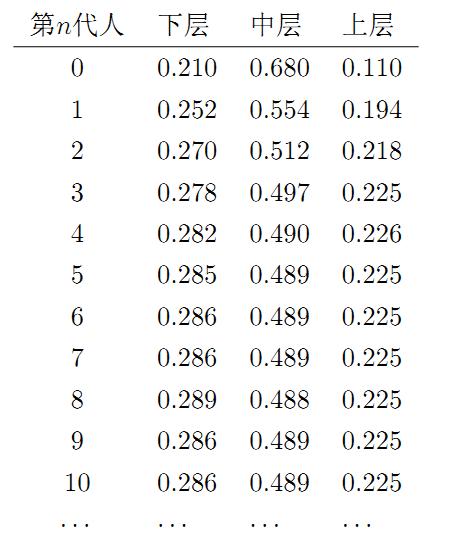
我们发现从第7代人开始,这个分布就稳定不变了,这个是偶然的吗?我们换一个初始概率分布$\pi_0 = [0.75,0.15,0.1]$ 试试看,继续计算前$n$代人的分布状况如下
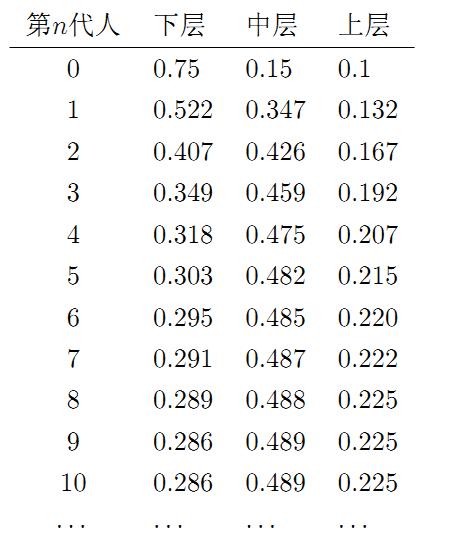
我们发现,到第9代人的时候, 分布又收敛了。最为奇特的是,两次给定不同的初始概率分布,最终都收敛到概率分布 $\pi=[0.286, 0.489, 0.225]$,也就是说收敛的行为和初始概率分布 $\pi_0$ 无关。这说明这个收敛行为主要是由概率转移矩阵$P$决定的。我们计算一下 $P^n$
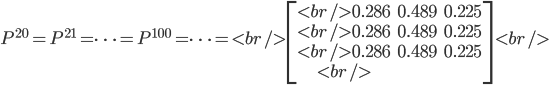
我们发现,当 $n$ 足够大的时候,这个$P^n$矩阵的每一行都是稳定地收敛到$\pi=[0.286, 0.489, 0.225]$ 这个概率分布。自然的,这个收敛现象并非是我们这个马氏链独有的,而是绝大多数马氏链的共同行为,关于马氏链的收敛我们有如下漂亮的定理:
马氏链定理: 如果一个非周期马氏链具有转移概率矩阵$P$,且它的任何两个状态是连通的,那么 $\displaystyle \lim_{n\rightarrow\infty}P_{ij}^n$ 存在且与$i$无关,记 $\displaystyle \lim_{n\rightarrow\infty}P_{ij}^n = \pi(j)$, 我们有
- $ \displaystyle \lim_{n \rightarrow \infty} P^n =\begin{bmatrix}
\pi(1) & \pi(2) & \cdots & \pi(j) & \cdots \\
\pi(1) & \pi(2) & \cdots & \pi(j) & \cdots \\
\cdots & \cdots & \cdots & \cdots & \cdots \\
\pi(1) & \pi(2) & \cdots & \pi(j) & \cdots \\
\cdots & \cdots & \cdots & \cdots & \cdots \\
\end{bmatrix} $
- $ \displaystyle \pi(j) = \sum_{i=0}^{\infty}\pi(i)P_{ij} $
- $\pi$ 是方程 $\pi P = \pi$ 的唯一非负解
其中,
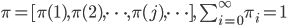
$\pi$称为马氏链的平稳分布。
这个马氏链的收敛定理非常重要,所有的 MCMC(Markov Chain Monte Carlo) 方法都是以这个定理作为理论基础的。 定理的证明相对复杂,一般的随机过程课本中也不给证明,所以我们就不用纠结它的证明了,直接用这个定理的结论就好了。我们对这个定理的内容做一些解释说明:
- 该定理中马氏链的状态不要求有限,可以是有无穷多个的;
- 定理中的“非周期“这个概念我们不打算解释了,因为我们遇到的绝大多数马氏链都是非周期的;
- 两个状态$i,j$是连通并非指$i$ 可以直接一步转移到$j$($P_{ij} > 0$),而是指 $i$ 可以通过有限的$n$步转移到达$j$($P_{ij}^n > 0$)。马氏链的任何两个状态是连通的含义是指存在一个$n$, 使得矩阵$P^n$ 中的任何一个元素的数值都大于零。
- 我们用 $X_i$ 表示在马氏链上跳转第$i$步后所处的状态,如果 $\displaystyle \lim_{n\rightarrow\infty}P_{ij}^n = \pi(j)$ 存在,很容易证明以上定理的第二个结论。由于
\begin{align*}
P(X_{n+1}=j) & = \sum_{i=0}^\infty P(X_n=i) P(X_{n+1}=j|X_n=i) \\
& = \sum_{i=0}^\infty P(X_n=i) P_{ij}
\end{align*}
上式两边取极限就得到 $ \displaystyle \pi(j) = \sum_{i=0}^{\infty}\pi(i)P_{ij}$
从初始概率分布 $\pi_0$ 出发,我们在马氏链上做状态转移,记$X_i$的概率分布为$\pi_i$, 则有
\begin{align*}
X_0 & \sim \pi_0(x) \\
X_i & \sim \pi_i(x), \quad\quad \pi_i(x) = \pi_{i-1}(x)P = \pi_0(x)P^n
\end{align*}
由马氏链收敛的定理, 概率分布$\pi_i(x)$将收敛到平稳分布 $\pi(x)$。假设到第$n$步的时候马氏链收敛,则有
\begin{align*}
X_0 & \sim \pi_0(x) \\
X_1 & \sim \pi_1(x) \\
& \cdots \\
X_n & \sim \pi_n(x)=\pi(x) \\
X_{n+1} & \sim \pi(x) \\
X_{n+2}& \sim \pi(x) \\
& \cdots
\end{align*}
所以 $X_n,X_{n+1},X_{n+2},\cdots \sim \pi(x)$ 都是同分布的随机变量,当然他们并不独立。如果我们从一个具体的初始状态 $x_0$ 开始,沿着马氏链按照概率转移矩阵做跳转,那么我们得到一个转移序列 $x_0, x_1, x_2, \cdots x_n, x_{n+1}\cdots,$ 由于马氏链的收敛行为, $x_n, x_{n+1},\cdots$ 都将是平稳分布 $\pi(x)$ 的样本。
老师讲得太明白了,比上研究生时机器学习的老师讲得还透彻明白。谢谢了。同时有两个小小的miss说一下,请老师参考。(1)底下的积分式无法显示计算,是不是应该是显式?(2)πi(x)=π0(x)pi,请参考。
[回复]
rickjin 回复:
13 1 月, 2013 at 18:53
谢谢指正,确实是敲错了 🙂
[回复]
第一次学 以前都没学 能遇到这么好的tutorial真是太好了
[回复]
文中的表,“下层 中层 上层” 应该是 “上层 中层 下层”。
[回复]
rickjin 回复:
15 1 月, 2013 at 14:05
谢谢, 我有空的时候对图片做修改
[回复]
个人认为从ergodic(geometry ergodic)到存在stationary distribution再到law of large numbers的推理思路貌似更易懂些。可以看范剑青《nonlinear time series》的第二章,虽然此书与MCMC无关,不过其讲解Markov chain的部分还是很可取的。
[回复]
rickjin 回复:
15 1 月, 2013 at 13:51
谢谢你的建议,你的建议很专业。 这个介绍的定位是专业科普,我预设的读者是互联网行业做数据处理的程序员,程序员的数学基础大都很一般,所以我尽量避开过多的数学概念,用相对通俗简单的方式做讲解。
[回复]
讲得非常好。通谷易懂。谢谢分享~
[回复]
老师讲的很好,我写了段matlab代码,通过Q,求出pi。我这样写有没有问题,帮我看看,
Q = [0.65 0.28 0.07;0.15 0.67 0.18;0.12 0.36 0.52];
ITERARTION = 100000;
walkStates=zeros(ITERARTION,1);
pre_state = 2;
for i = 1:ITERARTION
u = rand;
if u <= Q(pre_state,1)
state = 1;
elseif u <= Q(pre_state,1) + Q(pre_state,2)
state = 2;
else
state = 3;
end
walkStates(i) = pre_state;
pre_state = state;
end
begin = 90000;
pi = [length(find(walkStates(begin:ITERARTION,:)==1))/(ITERARTION-begin),length(find(walkStates(begin:ITERARTION,:)==2))/(ITERARTION-begin),length(find(walkStates(begin:ITERARTION,:)==3))/(ITERARTION-begin)]
[回复]
讲得确实好,佩服得五体投地啊,数学方面的东西也讲得很好,比如gamma函数这些!!!!
[回复]
文章最后写到“从一个具体的初始状态 x0 开始,沿着马氏链按照概率转移矩阵做跳转”,这里不明白,初始概率分布向量\pi_0依照概率转移矩阵的演变可以理解,一个具体的初始状态怎么演变呢?
[回复]
对马氏链证明的第四条中的公式,写下自己的理解(因为直接看我没看懂,搞了两个小时,也不确定对不对,格式不是重点,勉强看吧):
看不懂的公式是:
P(Xn+1=j) = ∑i=0 ∞ P(Xn=i) P(Xn+1=j|Xn=i)
= ∑i=0 ∞ P(Xn=i) Pij
两边取极限得:
π(j)= ∑i=0 ∞ π(i)Pij
---------------------------------------------------------
我的理解:
P不是之前的转移矩阵P了,而是概率**(我不知道应该用什么词代替**才合适)所以下面我标记为Pr
这次咱们慢点变:
Pr(Xn+1=j) = ∑i=0 ∞ Pr(Xn+1=j, Xn=i) # 这叫边缘分布,请维基,维基的介绍很好懂
= ∑i=0 ∞ Pr(Xn=i) Pr(Xn+1=j|Xn=i) # 这叫贝叶斯变换,同样请看维基的介绍
= ∑i=0 ∞ Pr(Xn=i) Pij
# Pij^n(在维基上)的定义就是Pr(Xk+n=j|Xn=i),由此变换得来
所以得到了:
Pr(Xn+1=j) = ∑i=0 ∞ Pr(Xn=i) Pij
# 也就是到了文中所讲:“上式两边取极限”的地方。
然而怎么取极限?我感觉Pr(Xn+1=j)是没法取极限的
所以(我猜)应该是要再来一次贝叶斯:
让 Pr(Xn+1=j) = Pr(Xn+1=j, Xn=i) / Pr(Xn=i|Xn+1=j)
# (用到的是贝叶斯公式其中之一:P(A)=P(A∩B)/P(B|A) )
再让 Pr(Xn=i) = Pr(Xn+1=j, Xn=i) / Pr(Xn+1=j|Xn=i)
所以就得到
Pr(Xn+1=j, Xn=i) / Pr(Xn=i|Xn+1=j) = ∑i=0 ∞ (Pr(Xn+1=j, Xn=i) / Pr(Xn+1=j|Xn=i)) Pij
把分子Pr(Xn+1=j, Xn=i)约掉后得到:
1 / Pr(Xn=i|Xn+1=j) = ∑i=0 ∞ (1 / Pr(Xn+1=j|Xn=i)) Pij
然后就真的可以取极限了,因为我们已经知道 lim n→∞ Pij^n = π(j)
那么就有了:
lim n→∞(1 / Pr(Xn=i|Xn+1=j)) = lim n→∞(∑i=0 ∞ (1 / Pr(Xn+1=j|Xn=i)) Pij)
1/π(i) = ∑i=0 ∞ (1 / π(j)) Pij
倒一下分子分母就有了: π(j) = ∑i=0 ∞ π(i) Pij
好像没有什么问题,叵费叵费︿( ̄︶ ̄)︿,貌似两个小时没有白费。
好吧我就是一个数学基础不怎么好的(准)程序员。对于这个“很容易证明以上定理的第二个结论。”(不是讽刺作者),写下自己的理解,欢迎批评指正。
[回复]
对马氏链证明的第四条中的公式,写下自己的理解(因为直接看我没看懂,搞了两个小时,也不确定对不对,格式不是重点,勉强看吧):
看不懂的公式是:
P(Xn+1=j) = ∑i=0 ∞ P(Xn=i) P(Xn+1=j|Xn=i)
= ∑i=0 ∞ P(Xn=i) Pij
两边取极限得:
π(j)= ∑i=0 ∞ π(i)Pij
---------------------------------------------------------
我的理解:
P不是之前的转移矩阵P了,而是概率**(我不知道应该用什么词代替**才合适)所以下面我标记为Pr
这次咱们慢点变:
Pr(Xn+1=j) = ∑i=0 ∞ Pr(Xn+1=j, Xn=i) # 这叫边缘分布,请维基,维基的介绍很好懂
= ∑i=0 ∞ Pr(Xn=i) Pr(Xn+1=j|Xn=i) # 这叫贝叶斯变换,同样请看维基的介绍
= ∑i=0 ∞ Pr(Xn=i) Pij
# Pij^n(在维基上)的定义就是Pr(Xk+n=j|Xn=i),由此变换得来
所以得到了:
Pr(Xn+1=j) = ∑i=0 ∞ Pr(Xn=i) Pij
# 也就是到了文中所讲:“上式两边取极限”的地方。
然而怎么取极限?我感觉Pr(Xn+1=j)是没法取极限的
所以(我猜)应该是要再来一次贝叶斯:
让 Pr(Xn+1=j) = Pr(Xn+1=j, Xn=i) / Pr(Xn=i|Xn+1=j)
# (用到的是贝叶斯公式其中之一:P(A)=P(A∩B)/P(B|A) )
再让 Pr(Xn=i) = Pr(Xn+1=j, Xn=i) / Pr(Xn+1=j|Xn=i)
所以就得到
Pr(Xn+1=j, Xn=i) / Pr(Xn=i|Xn+1=j) = ∑i=0 ∞ (Pr(Xn+1=j, Xn=i) / Pr(Xn+1=j|Xn=i)) Pij
把分子Pr(Xn+1=j, Xn=i)约掉后得到:
1 / Pr(Xn=i|Xn+1=j) = ∑i=0 ∞ (1 / Pr(Xn+1=j|Xn=i)) Pij
然后就真的可以取极限了,因为我们已经知道 lim n→∞ Pij^n = π(j)
那么就有了:
lim n→∞(1 / Pr(Xn=i|Xn+1=j)) = lim n→∞(∑i=0 ∞ (1 / Pr(Xn+1=j|Xn=i)) Pij)
1/π(i) = ∑i=0 ∞ (1 / π(j)) Pij
倒一下分子分母就有了: π(j) = ∑i=0 ∞ π(i) Pij
好像没有什么问题,叵费叵费︿( ̄︶ ̄)︿,貌似两个小时没有白费。
好吧我就是一个数学基础不怎么好的(准)程序员。对于这个“很容易证明以上定理的第二个结论。”(不是讽刺作者),写下自己的理解,欢迎批评指正。
[回复]
对马氏链证明的第四条中的公式,写下自己的理解(因为直接看我没看懂,搞了两个小时,也不确定对不对,格式不是重点,勉强看吧):
看不懂的公式是:
P(Xn+1=j) = ∑i=0 ∞ P(Xn=i) P(Xn+1=j|Xn=i)
= ∑i=0 ∞ P(Xn=i) Pij
两边取极限得:
π(j)= ∑i=0 ∞ π(i)Pij
---------------------------------------------------------
我的理解:
P不是之前的转移矩阵P了,而是概率**(我不知道应该用什么词代替**才合适)所以下面我标记为Pr
这次咱们慢点变:
Pr(Xn+1=j) = ∑i=0 ∞ Pr(Xn+1=j, Xn=i) # 这叫边缘分布,请维基,维基的介绍很好懂
= ∑i=0 ∞ Pr(Xn=i) Pr(Xn+1=j|Xn=i) # 这叫贝叶斯变换,同样请看维基的介绍
= ∑i=0 ∞ Pr(Xn=i) Pij
# Pij^n(在维基上)的定义就是Pr(Xk+n=j|Xn=i),由此变换得来
所以得到了:
Pr(Xn+1=j) = ∑i=0 ∞ Pr(Xn=i) Pij
# 也就是到了文中所讲:“上式两边取极限”的地方。
[回复]
为啥子偏偏要写成Pij呢,写Pij容易让人误解,Pij是一个值,P是一个状态转移矩阵,难道是我理解有问题么
[回复]