
大概一年前,我在AINLP的公众号对话接口里基于腾讯800万大的词向量配置了一个相似词查询的接口:
腾讯词向量和相似词、相似度、词语游戏系列
相似词查询:玩转腾讯 AI Lab 中文词向量
玩转腾讯词向量:词语相似度计算和在线查询
腾讯词向量实战:通过Annoy进行索引和快速查询
玩转腾讯词向量:Game of Words(词语的加减游戏)
词向量游戏:梅西-阿根廷+葡萄牙=?
通过这个接口,可以直接输入“相似词 自然语言处理"查询“自然语言处理”的相近词:

不过我们也发现,有不少用户直接输入"近义词 词语", "同义词 词语" 查询相似词,严格的说,基于词向量的相似词不能代表语言学意义上的近义词、同义词,但是可以匹配上一些近义词、同义词,甚至反义词,所以可以作为一个参考,由人来自己选择其中的近义词、同义词或者反义词,例如:

最近,这个功能又升级了,基于自动语言识别以及更多语言的词向量,不仅仅可以查询中文,还可以查询英文、日文等其他语言,基本上,主流的语言查询都覆盖了,感兴趣的朋友可以试试,例如:
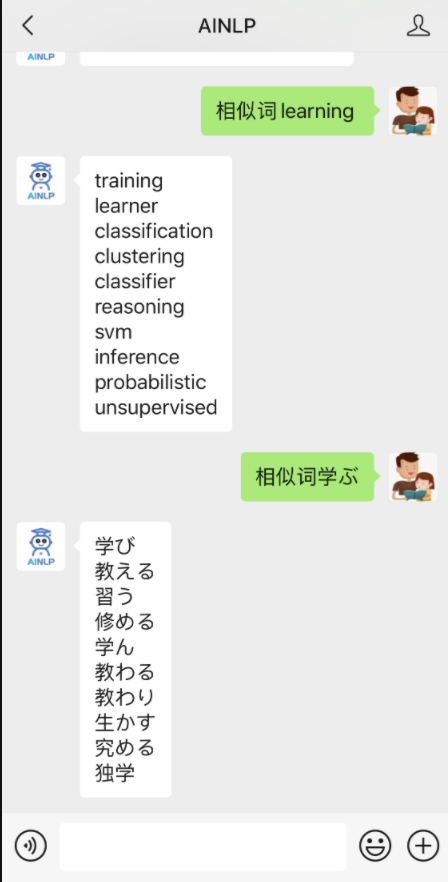
这些模型里,除了中文模型继续沿用腾讯词向量外,其他的是我很早之前基于维基百科的语料训练的,现在利用起来作为其他语言的查询支持,不过,因为绝大多数语言我都不懂,所以也可能会有错误。至于词向量模型,现在的选择远比当时丰富,如果是需要中文词向量,可以选择腾讯800万词向量,现在地址有所变化:
Tencent AI Lab Embedding Corpus for Chinese Words and Phrases(https://ai.tencent.com/ailab/nlp/zh/embedding.html)
或者参考:
上百种预训练中文词向量:Chinese-Word-Vectors
如果需要多种语言的,可以参考:
Pre-trained word vectors of 30+ languages(https://github.com/Kyubyong/wordvectors)
最后推荐一个Awsome系列,这里面有很多关于词嵌入模型的相关学习资源:
https://github.com/Hironsan/awesome-embedding-models