

在NLP领域中,文本分类舆情分析等任务相较于文本抽取,和摘要等任务更容易获得大量标注数据。因此在文本分类领域中深度学习相较于传统方法更容易获得比较好的效果。正是有了文本分类模型的快速演进,海量的法律文书可以通过智能化处理来极大地提高效率。我们今天就来分析一下当前state of art的文本分类模型以及他们在法律文书智能化中的应用。文本分类领域走过路过不可错过的深度学习模型主要有FastText,TextCNN,HAN,DPCNN。本文试图在实践之后总结一下这些这些分类模型的理论框架,把这些模型相互联系起来,让大家在选择模型与调参的时候能有一些直觉与灵感。在深度学习这个实践为王的领域常有人质疑理论理论无用,我个人的感受是理论首先在根据数据特征筛选模型的时候非常有用,其次在调参的过程中也能大幅提升效率,更重要的是调不出结果的时候,往往脑海里的那一句“这个模型不应该是这样的结果”,以及“这不科学”提供了坚持方向信心。
一、文本分类模型详解
1. FastText
其中FastText结构特别简单,对于速度要求特别高场合适用,他把一篇文章中所有的词向量(还可以加上N-gram向量)直接相加求均值,然后过一个单层神经网络来得出最后的分类结果。很显然,这样的做法对于复杂的文本分类任务来说丢失了太多的信息。FastText的一种简单的增强模型是DAN,改变在于在词向量平均完成后多叠了几层全连接神经网络。对应地,FastText也可以看成是DAN全连接神经网络层数为1的的一种特例。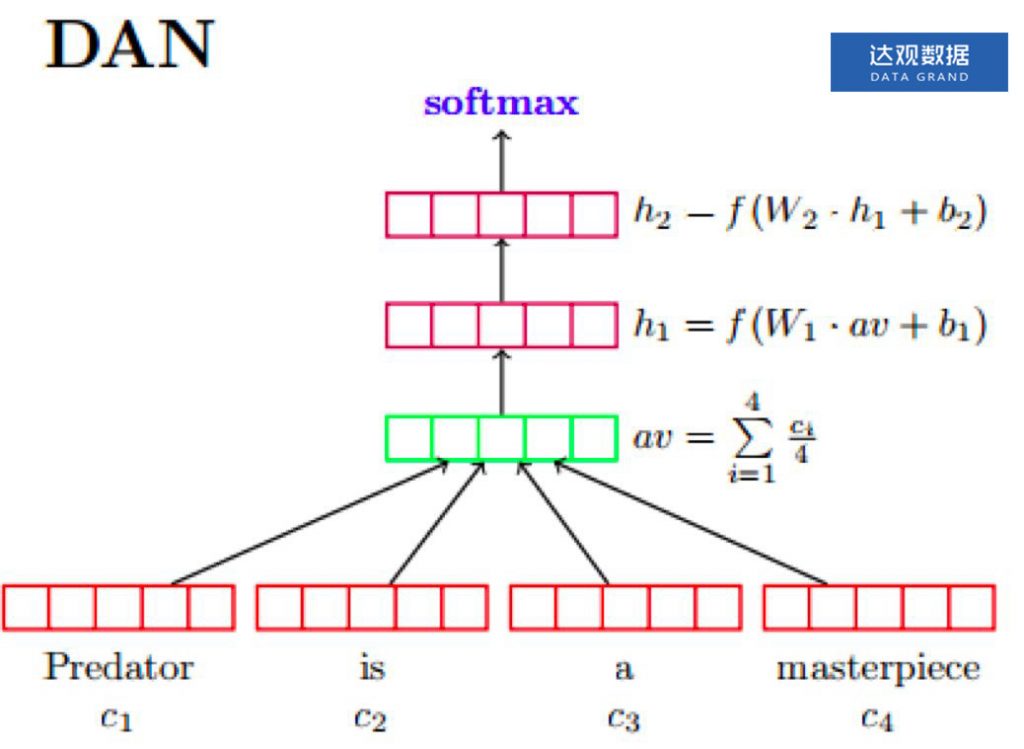
我不喜欢这类电影,但是喜欢这一个。我喜欢这类电影,但是不喜欢这一个。
这样的两句句子经过词向量平均以后已经送入单层神经网络的时候已经完全一模一样了,分类器不可能分辨出这两句话的区别,只有添加n-gram特征以后才可能有区别。因此,在实际应用的时候需要对你的数据有足够的了解。
2. TextCNN
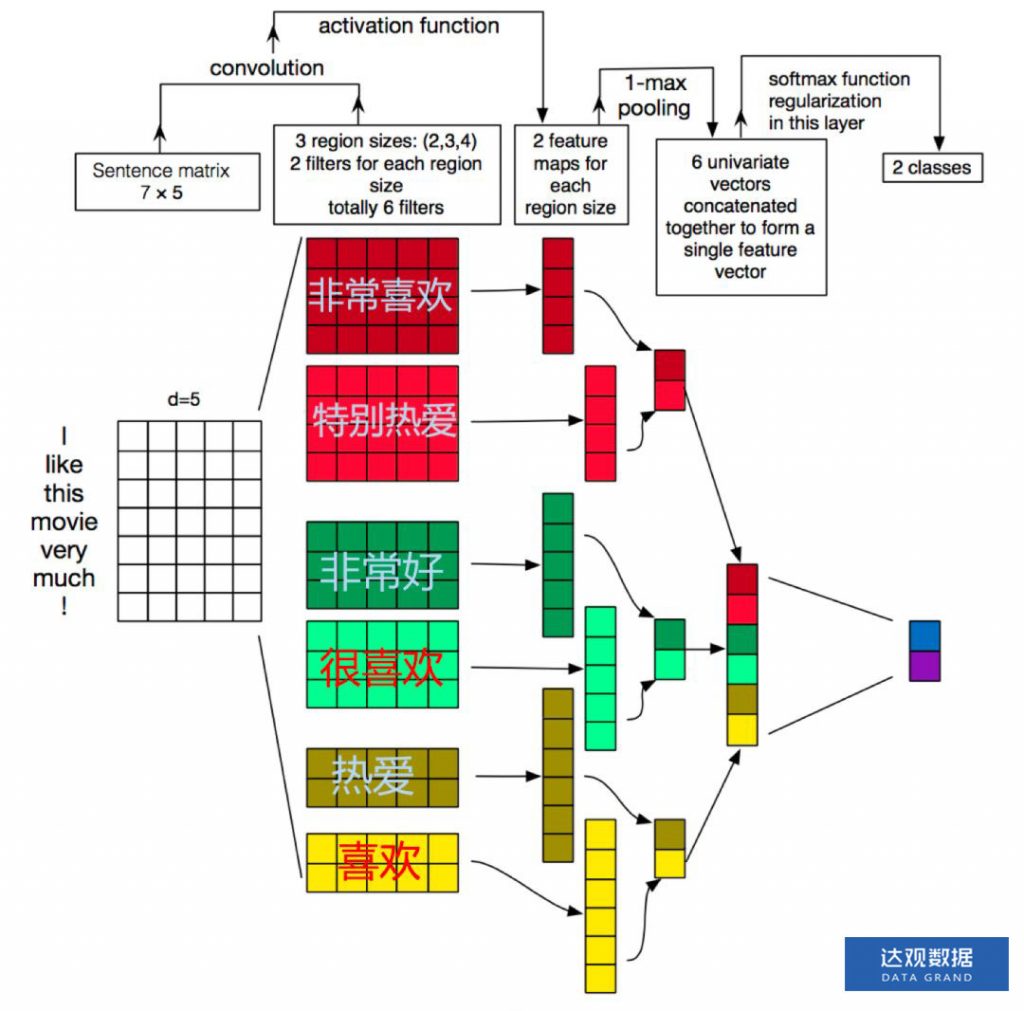
TextCNN相较于fastText模型的结构会复杂一些,在2014年提出,他使用了卷积 + 最大池化这两个在图像领域非常成功的好基友组合。我们先看一下他的结构。如下图所示,示意图中第一层输入为7*5的词向量矩阵,其中词向量维度为5,句子长度为7,然后第二层使用了3组宽度分别为2、3、4的卷积核,图中每种宽度的卷积核使用了两个。其中每个卷积核在整个句子长度上滑动,得到n个激活值,图中卷积核滑动的过程中没有使用padding,因此宽度为4的卷积核在长度为7的句子上滑动得到4个特征值。然后出场的就是卷积的好基友全局池化了,每一个卷积核输出的特征值列向量通过在整个句子长度上取最大值得到了6个特征值组成的feature map来供后级分类器作为分类的依据。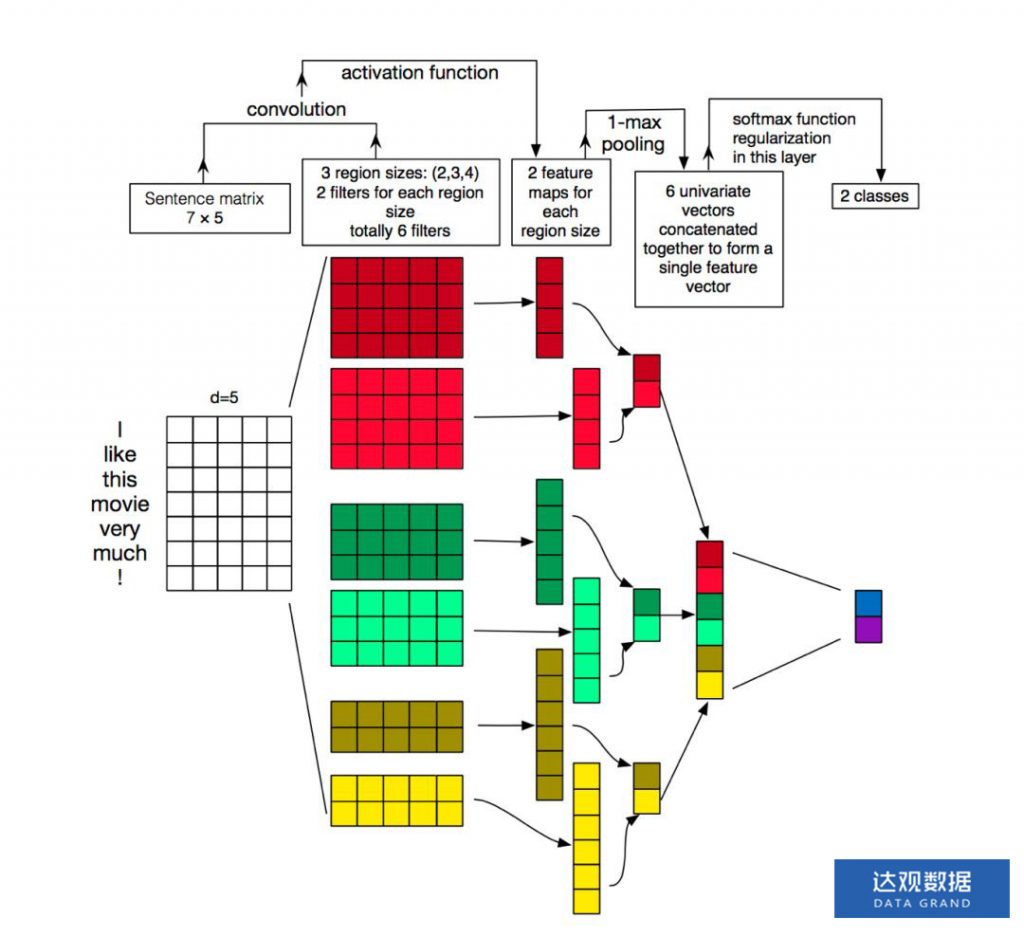
3. HAN(Hierarchy Attention Network)
相较于TextCNN,HAN最大的进步在于完全保留了文章的结构信息,并且特别难能可贵的是,基于attention结构有很强的解释性。他的结构如下图所示: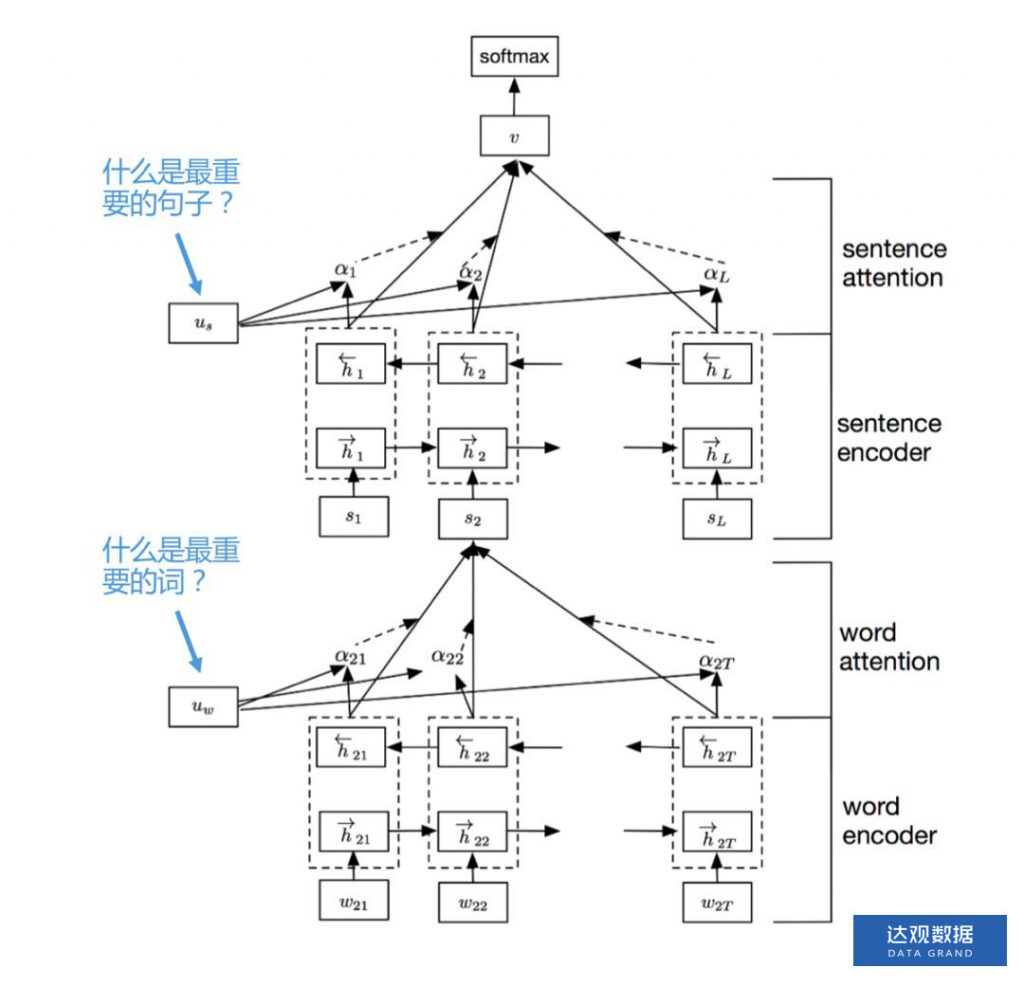


4 DPCNN
上面的几个模型,论神经网络的层数,都不深,大致就只有2~3层左右。大家都知道何凯明大神的ResNet是CV中的里程碑,15年参加ImageNet的时候top-5误差率相较于上一年的冠军GoogleNet直接降低了将近一半,证明了网络的深度是非常重要的。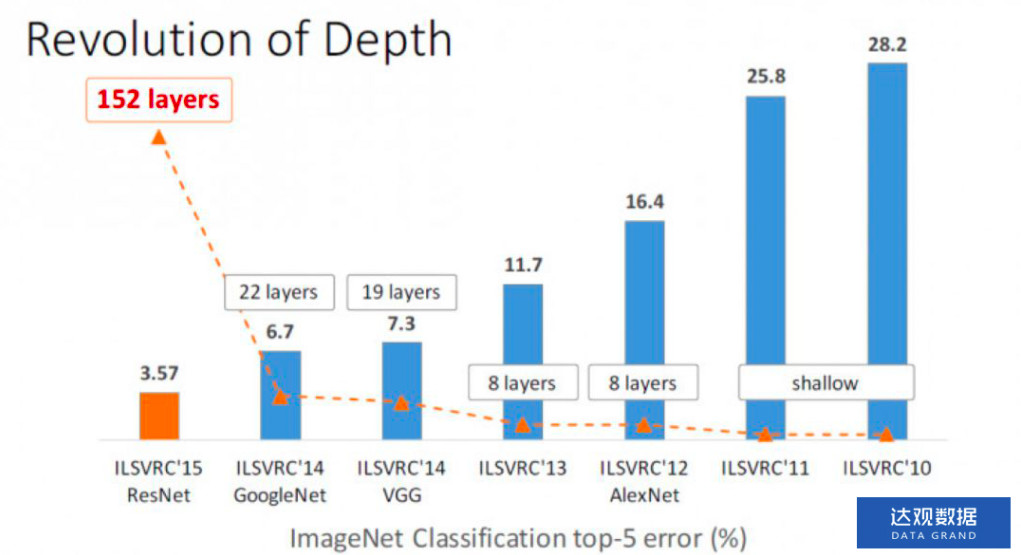
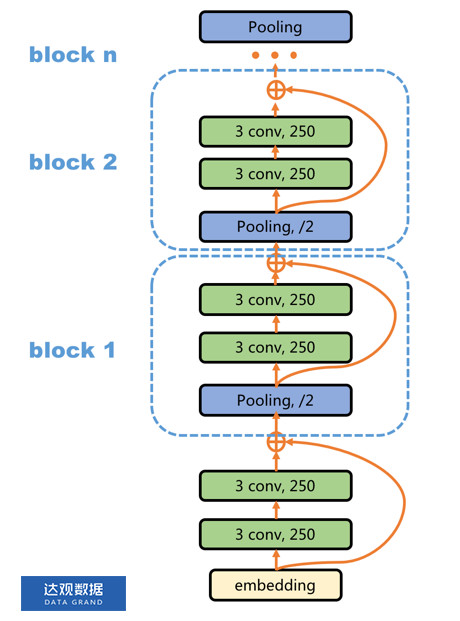
我们实际测试中在非线性度要求比较高的分类任务中DPCNN会比HAN精度高,并且由于他是基于CNN的,训练速度比基于GRU的HAN也要快很多。
二、法律文书智能化应用
达观数据在法律文书智能化处理中也应用了上面的几个模型,并在此基础上做法律行业针对性的优化。在刚刚结束的“法研杯”法律人工智能大赛中达观数据代表队取得了单项三等奖的成绩。以裁判文书智能化处理为例,达观数据可以通过上述的文本分类器根据一段犯罪事实来向法律工作者推荐与描述的犯罪事实相关的罪名,法律条文,甚至是刑期的预测等。下面以裁判文书网的一篇裁判文书为例,我们截取其中的犯罪事实部分文字,输入模型。模型会根据输入的文字判断此段分类事实对应的罪名,并且高亮出犯罪事实中的关键内容。截取裁判文书网中的犯罪事实部分:
“公诉机关指控:2017年6月30日22时左右,被告人耿艳峰醉酒驾驶冀T×××××号比亚迪小型轿车沿东孙庄村东水泥路由西向东行驶,行至事发处,与对向被告人孙汉斌无证醉酒驾驶无牌二轮摩托车发生碰撞。造成两车不同程度损坏,孙汉斌受伤的道路交通事故。经衡水市公安局物证鉴定所检验:耿艳峰血液酒精含量为283.11mg/lOOmL;孙汉斌血液酒精含量为95.75mg/mL。经武强县交通警察大队认定:耿艳峰、孙汉斌均负此事故的同等责任。”
得到结果:
三、总结
目前state of the art的深度学习文本发分类模型在十万~百万级以上的数据上已经能取得相当不错的效果,并且也有一些可解释性非常强的模型可用。要在实际业务中把文本分类模型用好,除了像文中深入分析理论以外,在大量的业务实践中总结经验也是必不可少的。达观在裁判文书处理等实际任务上实测输出结果也非常不错,并且达观的深度学习文本分类技术也会在各个业务应用中不断优化升级,希望能为法律行业的智能化以及效率优化作出一些贡献。
参考文献:
1.Joulin, Armand, et al. "Bag of Tricks forEfficient Text Classification." Proceedings of the 15th Conferenceof the European Chapter of the Association for Computational Linguistics:Volume 2, Short Papers. Vol. 2. 2017.2.Iyyer, Mohit, et al. "Deep unorderedcomposition rivals syntactic methods for text classification." Proceedingsof the 53rd Annual Meeting of the Association for Computational Linguistics andthe 7th International Joint Conference on Natural Language Processing (Volume1: Long Papers). Vol. 1. 2015.3.Kim, Yoon. "Convolutional Neural Networksfor Sentence Classification." Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing (EMNLP). 2014.4.Yang, Zichao, et al. "Hierarchicalattention networks for document classification." Proceedings of the2016 Conference of the North American Chapter of the Association forComputational Linguistics: Human Language Technologies. 2016.5.Johnson, Rie, and Tong Zhang. "Deeppyramid convolutional neural networks for text categorization." Proceedingsof the 55th Annual Meeting of the Association for Computational Linguistics(Volume 1: Long Papers). Vol. 1. 2017.
关于作者曾彦能:达观数据NLP算法工程师,负责达观数据NLP深度学习算法的研究、优化,以及在文本挖掘系统中的具体应用。对文本分类,序列标注模型有深入的研究。曾作为主要成员之一代表达观数据参加2018中国"法研杯" 法律智能挑战赛获得单项三等奖。
http://credit-n.ru/zaymyi-next.html
请问,为什么现在很多关于文本分类介绍的文章里,都没有介绍RCNN呢。在我之前的实验里,RCNN可以和HAN达到类似的结果,甚至会比HAN略好一点。是因为这个模型有一些其他的缺点吗?
[回复]
recommender 回复:
13 10 月, 2018 at 18:39
我个人认为从大体结构和思路上RCNN与TextCNN比较类似,RCNN的特征提取换成了双向RNN的输出再拼接原始词向量输入,最后仍然使用一个全局max-pooling。我个人认为这个结构在一些对于文档结构特征有要求的数据集上会不如HAN。不同数据集上的测试结果也可能会略有不同,并且在实际应用模型的时候,可能不会完全按照原始的模型来做,有时候实现细节,数据预处理等对于模型的影响也是非常大的。在文本较长,结构可能会对结果有影响的情况下,我自己会更加倾向于去先在HAN基础上做优化。你可以观察到在很多比赛中,名列前茅的模型都是融合了不只一个模型的结构去做的。我在看模型的时候会更加关注模型的思想和架构。
[回复]
请问作者,用不同的颜色高亮词语是怎么自动实现的呢?
[回复]