简介
机器学习工具包(PyTorch/TensorFlow)一般都具有自动微分(Automatic Differentiation)机制,微分求解方法包括手动求解法(Manual Differentiation)、数值微分法(Numerical Differentiation)、符号微法(Symbolic Differentiation)、自动微分法(Automatic Differentiation),具体的详细介绍可以参见自动微分(Automatic Differentiation)简介,这里主要说一下自动微分法的实现。
自动微分法实现
github地址:https://github.com/tiandiweizun/autodiff
git上有不少自动微分的实现,如autograd等,这里还有一个特别简单的AutodiffEngine更适合作为教程,但AutodiffEngine是静态图,整个过程对于初学者还是有点复杂的,主要是不直观,于是动手autodiff写了一个简单的动态图的求导,里面的大部分算子的实现还是参照AutodiffEngine的。
设计:其实主要是2个类,一个类Tensor用于保存数据,另一个类OP支持forward和backward,然后各种具体的运算类,如加减乘除等继承OP,然后实现具体的forward和backward过程
过程:分为forward和backward两个过程,forward从前往后计算得到最终的输出,并返回新的tensor(如下图中的v1),新的tensor保存通过哪些子tensor(v-1),哪个具体的算子(ln)计算得到的(计算图),backward按照计算图计算梯度,并赋值给对应的子tensor(v-1)

实现:
先贴一点代码
class Tensor:
def __init__(self, data, from_tensors=None, op=None, grad=None):
self.data = data # 数据
self.from_tensors = from_tensors # 是从什么Tensor得到的,保存计算图的历史
self.op = op # 操作符运算
# 梯度
if grad:
self.grad = grad
else:
self.grad = numpy.zeros(self.data.shape) if isinstance(self.data, numpy.ndarray) else 0
def __add__(self, other):
# 先判断other是否是常数,然后再调用
return add.forward([self, other]) if isinstance(other, Tensor) else add_with_const.forward([self, other])
def backward(self, grad=None):
# 判断y的梯度是否存在,如果不存在初始化和y.data一样类型的1的数据
if grad is None:
self.grad = grad = numpy.ones(self.data.shape) if isinstance(self.data, numpy.ndarray) else 1
# 如果op不存在,则说明该Tensor为根节点,其from_tensors也必然不存在,否则计算梯度
if self.op:
grad = self.op.backward(self.from_tensors, grad)
if self.from_tensors:
for i in range(len(grad)):
tensor = self.from_tensors[i]
# 把梯度加给对应的子Tensor,因为该Tensor可能参与多个运算
tensor.grad += grad[i]
# 子Tensor进行后向过程
tensor.backward(grad[i])
# 清空梯度,训练的时候,每个batch应该清空梯度
def zero_gard(self):
self.grad = numpy.zeros(self.data.shape) if isinstance(self.data, numpy.ndarray) else 0
class OP:
def forward(self, from_tensors):
pass
def backward(self, from_tensors, grad):
pass
class Add(OP):
def forward(self, from_tensors):
return Tensor(from_tensors[0].data + from_tensors[1].data, from_tensors, self)
def backward(self, from_tensors, grad):
return [grad, grad]
add = Add()
这里以加法为例,讲一下具体的实现。
Tensor类有四个属性,分别用于保存数据、子Tensor、操作符、梯度,OP类有两个方法,分别是forward和backword,其中Add类继承OP,实现了具体的forward和backword过程,然后Tensor重载了加法运算,如果是两个Tensor相加,则调用Add内部的forward。
x1_val = 2 * np.ones(3) x2_val = 3 * np.ones(3) x1 = Tensor(x1_val) x2 = Tensor(x2_val) # x1+x2 调用了Add的forward方法,并用[5,5,5]、x1与x2、加法操作构造新的Tensor,然后赋值给y y = x1 + x2 assert np.array_equal(y.data, x1_val + x2_val)
backward过程先是计算梯度,然后把梯度赋值给各个子Tensor
# 判断梯度是否存在,此时不存在则初始化为[1,1,1] # 调用Add的backward计算得到梯度[[1,1,1],[1,1,1]] # 把梯度累加给对应的子Tensor,并调用x1和x2的backward # 由于此时梯度存在,则不需要初始化 # 由于x1和x2无op和from_tensors,停止并退出 y.backward() assert np.array_equal(x1.grad, np.ones_like(x1_val)) assert np.array_equal(x2.grad, np.ones_like(x2_val))
add_with_const和其他运算符参见代码
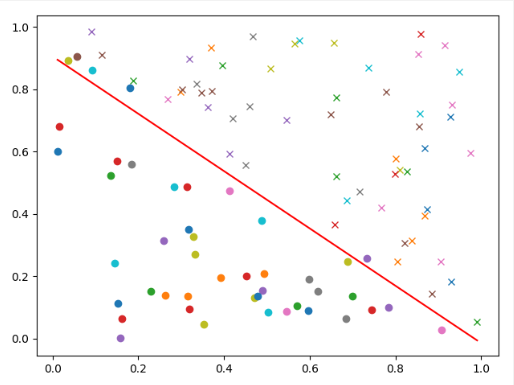
利用现有的自动求导来训练一个线性回归模型,绝大部分代码来自于AutodiffEngine里面的lr_autodiff.py,其中gen_2d_data方法用于生成数据,每个样例有3维,其中第一维是bias,test_accuracy判断sigmoid(w*x)是否大于0.5来决定分类的类别,并与 y进行对比计算准确率。
我这里仅修改了auto_diff_lr方法,去掉了静态图里面的逻辑,并换成Tensor来封装。
下图为训练日志和训练结果