
内容来源:ChatGPT 及大模型专题研讨会
分享嘉宾:达观数据董事长兼CEO 陈运文博士
分享主题:《探索大语言模型垂直化训练技术和应用》
转载自CSDN稿件
本文整理自 3月11日 《ChatGPT 及大规模专题研讨会》上,达观数据董事长兼CEO 陈运文博士关于《探索大语言模型垂直化训练技术和应用》的分享,将介绍达观数据在大语言模型应用中的探索与思考。
此次分享的主要内容分为 6 块,分别是:
- 参数规模和数据规模的探索
- 垂直领域适应预训练
- 微调技术探索
- 提示工程和垂直优化
- 模型训练加速思路
- 模型功能的垂直效能增强
在探索大语言模型应用过程中,将团队的思考列为了四点:
- 整体来看,尽管模型的参数规模越大越好,但可探索性价比更高的参数规模方案
- 训练数据尽管越多越好,但针对垂直场景可探索更高效和有针对性的数据提炼方法
- 为强化垂直方向的效果,可在模型预训练和微调技术上探索一些好的思路
- 为更贴合垂直场景的产品应用,探索模型的功能增强、以及 prompt 等方向的产品创新

陈运文,达观数据董事长兼CEO,复旦大学博士,计算机技术专家,国际计算机学会(ACM)和电子电器工程师学会(IEEE)会员
参数规模和数据规模的探索
一、缩放法则 (Scaling Laws)众所周知,大模型的算力非常惊人。在 2020 年,从 OpenAI 在语言模型方面的研究可以看到,语言模型的效果与参数量、数据量、计算量基本呈平滑的幂定律——缩放法则 (Scaling Laws) 。随着模型的参数量(Parameters)、参与训练的数据量(Tokens)以及训练过程累积的计算量(FLOPS)的指数性增大, 模型在测试集上的 Loss 就线性降低,也就意味着模型的效果越好。
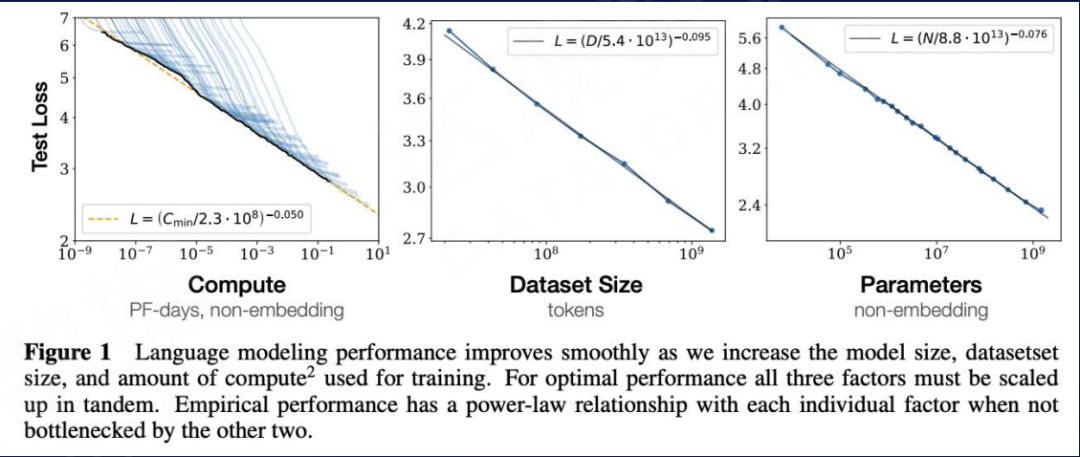 Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
如下图所示,在运算量的增加过程中,参数规模的增加可以起到更关键的作用。在给定的计算量且参数规模较小时, 增大模型参数量对于模型效果的贡献,远优于增加数据量和训练步数。这也作为后续推出的 GPT-3(175B) 和其他千亿级别模型奠定了理论基础。
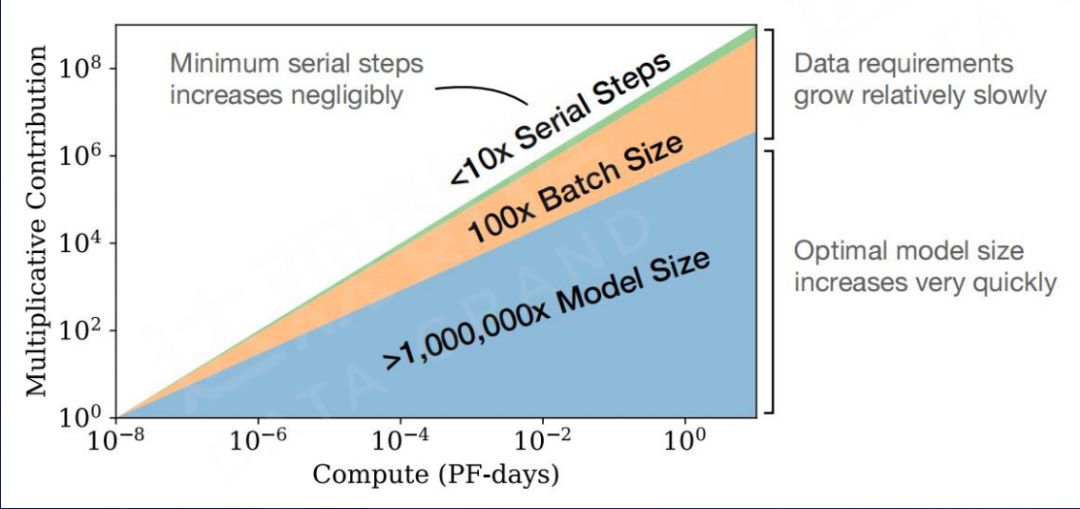
Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
二、Compute-Optimal 在 2022 年,DeepMind 在 ScalingLaw 里又做了进一步分析。研究通过定量的实验验证,语言模型训练数据大小,应该和模型参数量大小等比放大。可以看到,在计算总量不变的情况下,模型训练的效果在参数量和训练数据量当中有个最优平衡点,曲线下面的最低点是在参数规模和训练数据量当中有个非常好的折中点。
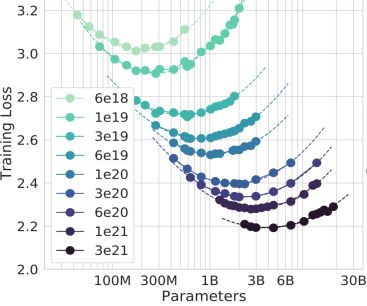
Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
进一步研究表明,像 GPT-3(175B) 这么大规模的参数里,用这三种计算方式进行拟合的话,会发现 GPT-3 并没有充分得到训练。
因此,我们需要考虑真正落地应用在垂直领域时,千亿级别参数规模的庞大模型所消耗的巨大成本,以避免参数的浪费。
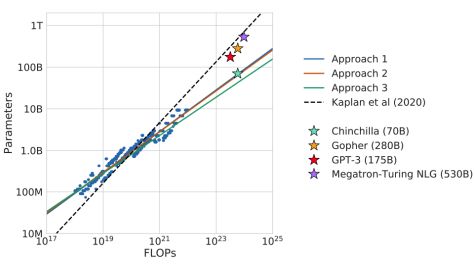
Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
三、Open and Efficient

Touvron H, Lavril T, Izacard G, et al. LLaMA: Open and Efficient Foundation Language Models[J]. arXiv preprint arXiv:2302.13971, 2023.
Meta 受到 DeepMind 理论的启发,在 2023 年推出了百亿模型 LLaMA,经过 1.4 万亿 Token(近 4.7 倍于 GPT-3 )的训练数据,在很多下游实验任务当中效果明显好于 GPT3 千亿规模的参数。因此,即便你的参数规模可能没那么大,增加训练 Token 量依然能够看到效果。
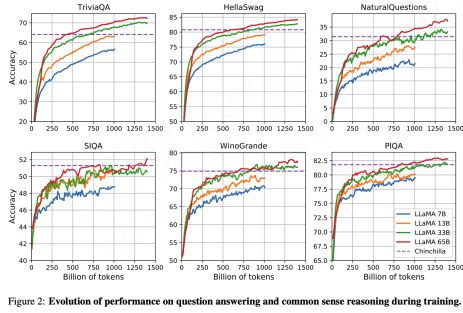
Touvron H, Lavril T, Izacard G, et al. LLaMA: Open and Efficient Foundation Language Models[J]. arXiv preprint arXiv:2302.13971, 2023.
在训练过程中,无论是 65B、33B、17B,甚至 7B 的小模型,在训练数据接近超过万亿 Token 之后,下游任务的效果仍在提升,也就是说这些参数的潜力可以通过更多 Token 训练进一步激发出来。故此可推测,百亿模型的潜力仍有待深入挖掘,尤其在算力资源受限的情况下,存在性价比更高的优化空间。
四、数据规模存在瓶颈 :开放数据即将耗尽

Villalobos P, Sevilla J, Heim L, et al. Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning[J]. arXiv preprint arXiv:2211.04325, 2022.
在我们做更大参数规模的模型训练时,数据已经逐步开始显现出力不从心的地方。上图是结合历史数据增长率和数据使用率做出的推测,有研究预计互联网上可用的数据资源很有可能会被耗尽。
- 高质量的语言数据按照目前的发展速度,预计 2026 年可能就要耗尽;
- 低质量的语言数据(如日常聊天等)到 2025 年就耗尽;
- 多模态的数据(比如视觉图像)到 2060 年要耗尽;
五、通用大模型的预训练数据集研究 大规模语言模型的预训练数据规模不断增加,但即使使用的是开放数据,也少有团队公开所使用的数据集和其包含的详细信息。通过 Pile 数据集提供的为数不多的 “Datasheet for Datasets” 信息可以看到,Wiki 百科、书籍、学术期刊等高质量语料数据起到关键性作用。
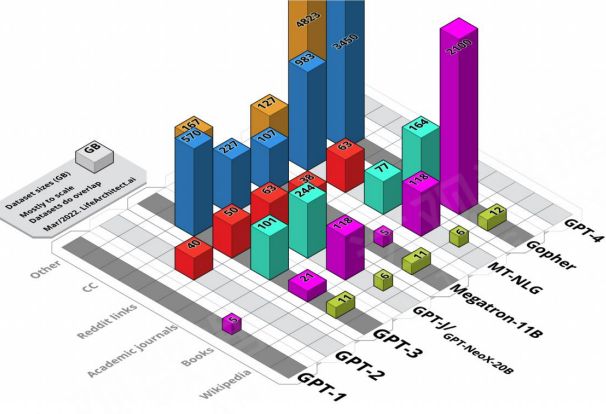
大模型预训练数据可视化
Alan D. Thompson. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B, Megatron-11B, MT-NLG, and Gopher. https://lifearchitect.ai/whats-in-my-ai. 2022
六、通用预训练之对数据多样性的分析 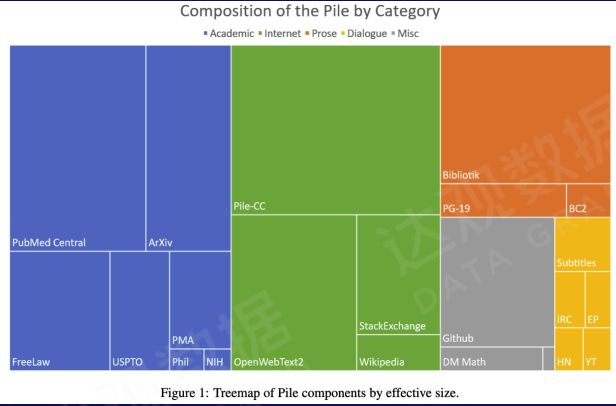
The Pile v1数据集的构成(800GB)
Gao L, Biderman S, Black S, et al. The pile: An 800gb dataset of diverse text for language modeling[J]. arXiv preprint arXiv:2101.00027, 2020.
在通用预训练过程中,不同类型的文本代表不同的能力。如绿色的文本是训练通用的知识。像学术文本(蓝色),包括一些出版物(橙色)等等,一部分是训练专业领域的知识,另一部分是训练一些带有情感的讲故事和创造性文艺创作的能力。对话文本(黄色)虽然规模不大,但是它对提升对话能力非常有帮助。除此之外,还有训练 COT 能力的代码、数学题等,这些数据规模参差不齐,但多样性的数据对提升语言大模型的综合性能起到非常重要的作用。
七、多语种和能力迁移
Blevins T, Zettlemoyer L. Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 3563-3574.
今天我们看到多语种数据训练和能力迁移非常有异议。研究表明,大规模单语种(英语)预训练中,即使混入的不足 0.1% 其他语种,也会让模型拥有显著的跨语种能力。语言之间存在某种共性,且底层的知识和认知能力是跨语言的,因此混合训练可以起到一定的增强作用。

单语种中其他语种 token 数量与占比
Blevins T, Zettlemoyer L. Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 3563-3574.
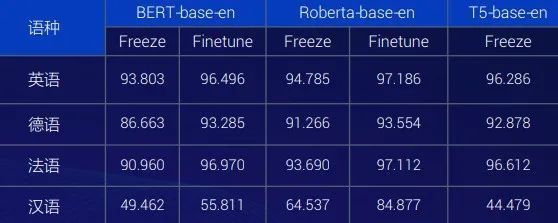
单语种下其他语种词性标注任务性能
Blevins T, Zettlemoyer L. Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 3563-3574.
语种越接近,能力迁移作用越明显。如上图,汉语虽然语料占比非常低,但是效果不错。因此,在训练语料和语料集合构成中,不同语言的语料相互影响。
八、选择最合适的训练数据
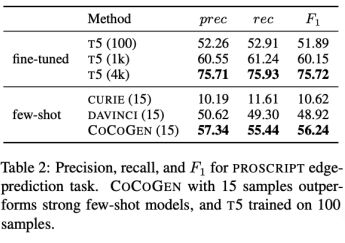
Madaan A, Zhou S, Alon U, et al. Language models of code are few-shot commonsense learners[J]. arXiv preprint arXiv:2210.07128, 2022.
在复杂任务如事件和图推理上的实验表明,代码训练显著增强大模型的常识推理能力,且仅使用有限的代码训练量就 能取得比 fine-turned T5 模型明显得多的效果提升。
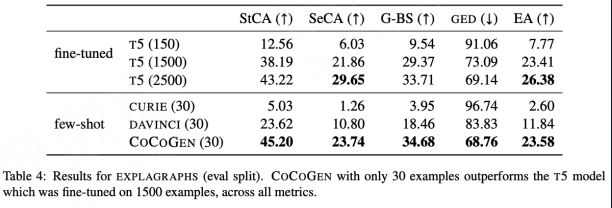
Madaan A, Zhou S, Alon U, et al. Language models of code are few-shot commonsense learners[J]. arXiv preprint arXiv:2210.07128, 2022.
正确的训练数据对提升某些能力有重要效果,“对症下药”很关键,未来在垂直领域任务中可能存在优化空间。
九、探索预训练的数据过滤和提纯方法 
现在常用的模型数据提纯方法有两类,一类是上图这个,它用到传统的文本分类技术,将高质量的文本作为正面的样本集合,一部分如大量带有互联网上的垃圾广告或者低质量评论等数据做负面样本。标注以后送到分类器里分类,再把高质量的文本提取出来。这是一种常规方法,但严重依赖文本分类、数据标注等,费时费力。

Xie S M, Santurkar S, Ma T, et al. Data Selection for Language Models via Importance Resampling[J]. arXiv preprint arXiv:2302.03169, 2023.
另一类是基于重要性采样的数据提纯方法。我们在目标样本集里人为的挑出一些我们认可的高质量的数据,对这个高质量的数据做一个 KL reduction,并且做相应分布计算。得出的目标样本的集合越接近,重要性越高,这种方式相对更容易提纯出优质语料用来做模型训练。
垂直领域适应预训练
探索垂直领域大模型预训练的三种思路:
- 先用大规模通用语料预训练,再用小规模领域语料二次训练
- 直接进行大规模领域语料预训练
- 通用语料比例混合领域语料同时训练
一、探索路线一:自适应预训练 先大规模通用语料预训练,再用小规模领域语料预训练。
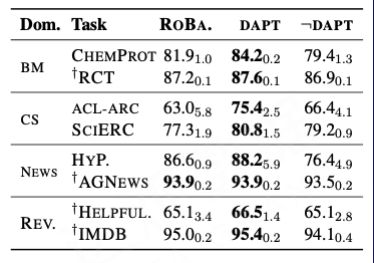
Gururangan S, Marasović A, Swayamdipta S, et al. Don't stop pretraining: Adapt language models to domains and tasks[J]. arXiv preprint arXiv:2004.10964, 2020.
这里有两种不同的处理方法,一种是领域自适应的预训练,叫 “DAPT”,DAPT 后在领域任务上相比通用模型效果提升,但是 DAPT 后的领域模型在其它领域上效果比通用模型效果差。
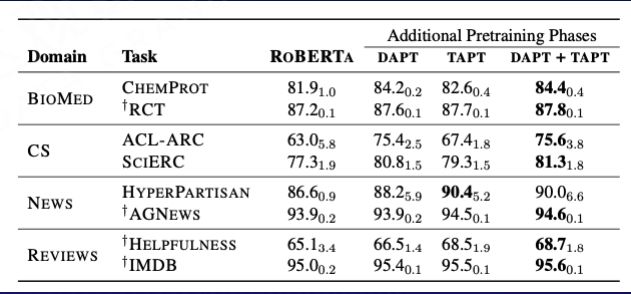
Gururangan S, Marasović A, Swayamdipta S, et al. Don't stop pretraining: Adapt language models to domains and tasks[J]. arXiv preprint arXiv:2004.10964, 2020.
另外一种叫任务自适应预训练,它是在任务的数据集进行训练,叫 “TAPT”。
TAPT 相比通用模型也更好,DAPT +TAPT 效果最佳 。
二、预微调预微调(Pre-Finetuning)技术也是路线一当中可以尝试的一个方法。在预微调的过程中不同任务的 loss 进行缩放后再累加,而且对预微调工作不进行数据采样,维持它的自然分布效果最佳。
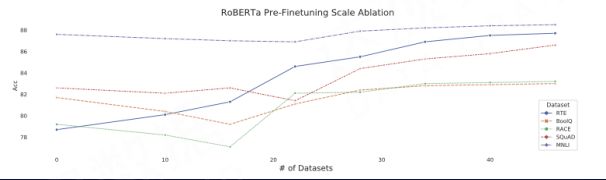
Aghajanyan A, Gupta A, Shrivastava A, et al. Muppet: Massive multi-task representations with pre-finetuning[J]. arXiv preprint arXiv:2101.11038, 2021.
如图,多任务的数据集对它进行 Pre-Finetuning,不同的任务集合越多,最终得到的预微调的模型效果就越好。
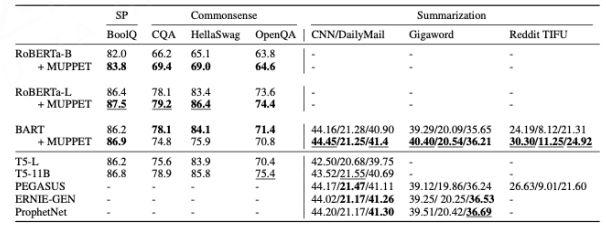
Aghajanyan A, Gupta A, Shrivastava A, et al. Muppet: Massive multi-task representations with pre-finetuning[J]. arXiv preprint arXiv:2101.11038, 2021.
预微调模型的效果比原始模型的效果在上面几个经典的大语言模型上都取得了不错的效果。
三、能力对比
“Codex comments tend to reproduce similar biases to GPT-3, albeit with less diversity in the outputs.” “when the model is used to produce comments in an out-of-distribution fashion, it tends to act like GPT-3.”
—— OpenAI
《Evaluating large language models trained on code》
Chen M, Tworek J, Jun H, et al. Evaluating large language models trained on code[J]. arXiv preprint arXiv:2107.03374, 2021.
OpenAI 有一篇论文里提到小规模语料预训练后对通用文本的生成能力并没有负面影响。当涉及与Code领域无关的文本生成时,Codex 的生成和 GPT-3 的生成差异不大,体现在两者有很多共现的词,区别是 GPT-3 表述更多样性。由此猜想小规模领域语料预训练后的大模型在自身领域内相比通用大模型增强,而在通用生成上表现与通用大模型相当。这是我们值得未来探索的。
四、探索路线二:效果分析 直接进行大规模领域语料预训练工作。
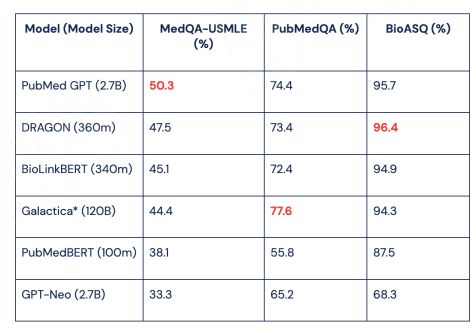
BioMedLM: a Domain-Specific Large Language Model for Biomedical Text(https://www.mosaicml.com/blog/introducing-pubmed-gpt)
一个医学领域的代表模型 PubMedGPT 2.7 B。一个是金融领域 BBT-FinT5 模型。它们的参数规模都不大,但是这些用垂直领域的数据做的专用训练,它的效果比参数规模更小一点的小模型来说有非常明显的提升。另外,和相同规模通用大规模的 Finetune 相比,垂直领域大模型的效果仍然是领先的。
因此,路线二是一个性价比非常高的方案,它用到的参数规模并不大,但在垂直领域的效果不错。同时,垂直领域大模型所用资源会比通用大模型少很多,并且和超大规模模型在垂直领域的效果是接近的,这种方式也给我们开启了一些尝试的空间。
五、知识增强知识增强是专业领域的知识增强,可以较好的探索路线二时提升它的专业模型训练效果。

Lu D, Liang J, Xu Y, et al. BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark[J]. arXiv preprint arXiv:2302.09432, 2023.
在这个知识三元组( head、relation、tail )里,把一部分内容做了一个掩码,进行预训练。
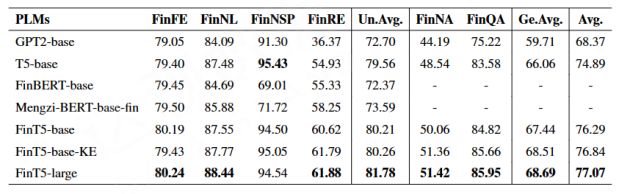
Lu D, Liang J, Xu Y, et al. BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark[J]. arXiv preprint arXiv:2302.09432, 2023.
应用了知识增强技术的领域大模型在领域任务上的效果, 好于领域小模型和通用大模型。所以这可能是一条值得去探索的中间道路,是一种垂直领域比大模型要略小一点,但比小模型要大的中间态的模型。
六、探索路线三:语料按比例混合,同时预训练
通用语料比例混合领域语料同时预训练。这方面目前没有研究报告,但是我们做了些猜测:
- 数据规模:通用语料+领域语料 > 千亿 tokens
- 数据比例:领域语料占总语料比例应显著高于通用语料中该领域的自然比例,且领域语料占总语料比例应显著高于通用语料中各领域自然比例的最大值(显著高于的含义:可能是至少高 1 个数量级)
- 模型规模:> 10B
- 保障训练batch中数据异质性,使得 loss 下降在训练过程中更平稳
- 知识增强技术
- 微调领域增
微调技术探索
一、增量微调我们对微调技术做了一些探索,目标是为了降低大模型的微调成本,同时能够更高效地把一些专业领域的知识引入进来。
与微调进行的实验对比
Ding N, Qin Y, Yang G, et al. Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models[J]. arXiv preprint arXiv:2203.06904, 2022.
结果显示,delta tunig 和 fine tuning 之间的差距并非不可逾越,这证明了参数有效自适应的大规模应用的潜力。上图列了不同研究者提出的增量微调的技术,比如有的是在 PLM 层之间加入一层适配器模块,还有通过更新预先插入的参数来调整 PLM 等等。这些都是在局部来做模型参数的调整,能够把这些理论知识加进去,同时又不影响整个模型大规模应用的潜力。
二、多任务提示/指令微调
Muennighoff N, Wang T, Sutawika L, et al. Crosslingual generalization through multitask finetuning[J]. arXiv preprint arXiv:2211.01786, 2022.
指令微调的目标是提升语言模型在多任务中的零样本推理能力。微调后的语言模型具有很强的零任务概括能力。

Muennighoff N, Wang T, Sutawika L, et al. Crosslingual generalization through multitask finetuning[J]. arXiv preprint arXiv:2211.01786, 2022.
上图是其中一个研究结果,像 BLOOMZ、Flan-T5、mT0 这些模型上面,通过使用多任务的提示微调或者指令微调技术,效果有不错的提升。
三、COT(Chain-of-Thought)微调
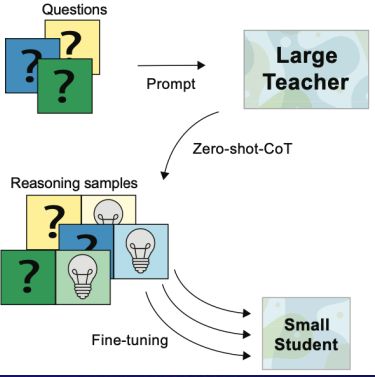
Magister L C, Mallinson J, Adamek J, et al. Teaching small language models to reason[J]. arXiv preprint arXiv:2212.08410, 2022.
Ho N, Schmid L, Yun S Y. Large Language Models Are Reasoning Teachers[J]. arXiv preprint arXiv:2212.10071, 2022.
Fu Y, Peng H, Ou L, et al. Specializing Smaller Language Models towards Multi-Step Reasoning[J]. arXiv preprint arXiv:2301.12726, 2023.
COT 的微调也是一个很不错的技术,将文本 (questions + prompt) 输入给大模型,用大模型输出含有思维链且正确的文本作为 label 。再用上述数据组成的数据对(Reasoning samples),直接对小模型进行微调。使小语言模型获得思维链能力。
提示 Prompt 垂直优化
一、提示工程( Prompt Engineering ) 在大模型领域里,Prompt 是一个新的研究领域,Prompt 能否用好,对未来在垂直领域能否做出优秀的产品起到重要的作用。在这方面我们也做了一些思考,认为垂直领域的提示工程(Prompt Engineering)未来在垂直领域落地产品时会有很多创新点。在垂直领域创新工程方面,我们的大思路是让模型完成垂直领域指定任务后,在 prompt 当中提出明确的要求,这样能够把垂直领域的专业任务变成模型期望的输出。
这一过程当中,产品化很重要。今天所谓的指令提示工程,很多时候还是大段的文字,只不过不同的方式去描述而已。因此,未来在复杂的垂直领域任务可能需要极为丰富的 prompt 信息,包括各类事实、数据、要求等,并存在层层递进的多步骤任务,因此值得探索产品化方案来生成 prompt。
二、提示工程的两种思路 现在我们尝试两种思路,一种是产品化思路。产品化的是请垂直领域的专家,针对每项垂直任务,来设计用于生成 prompt 的产品,由专家编写大量不同的 prompt,评估或输出好的 prompt 后,进行片段切分,形成相应的产品,这对未来 AIGC 任务会起到很好的作用。另一种是自动化的思路,通过借过外部工具,或通过自动化的流程方法和训练方式,对 Prompt 进行自动优化。
Automatic Prompt Engineer (APE)
Zhou Y, Muresanu A I, Han Z, et al. Large language models are human-level prompt engineers[J]. arXiv preprint arXiv:2211.01910, 2022.

Directional Stimulus Prompting(DSP)
Li Z, Peng B, He P, et al. Guiding Large Language Models via Directional Stimulus Prompting[J]. arXiv preprint arXiv:2302.11520, 2023.
这里有两种不同的技术路线,一种叫 APE 的技术,一种叫 DSP 的技术,它们基本思想都是让大语言模型加入到Prompt 过程当中。另外,我们可以训练一个小的 LLM,它能够对 Prompt 进行有效提示,未来都可以在很多垂直领域里得到创新和应用。
模型训练加速思路
整体来说,在我们工业界的模型加速大致有两块思路,一是分布式并行,二是显存优化工作。
一、分布式并行的工作 有 4 种常见技术:
1、数据并行(Data Parallelism):在不同的 CPU 上存放神经网络的副本,用更大的 batch size 来训练模型,来提高并行能力。
2、模型并行(Tensor Parallelism):解决模型在一个 GPU 上放不下的问题。
3、流水线并行(Pipeline Parallelism):多个 GPU 之间高效利用它的资源。
4、混合并行(Hybrid Parallelism):这些并行工作能够更好地充分利用 GPU 的并行运算能力,来提升模型迭代加速的速度。
二、显存优化当然也有不错显存优化方案,像混合精度训练、降低深度学习训练中间激活带来的显存占用、能够降低模型加载到显存当中的资源占用,以及我们通过去除冗余的参数,引入 CPU 和内存等等方式,能够解决显存容量不够导致的模型运算慢或者大模型跑不动的问题。
模型功能的垂直效能增强
大语言模型存在很多缺陷,如存在事实性错误以及关键数据错误、垂直领域可能存在复杂的推理任务等。基于此,我们也在尝试一些不同的思路来做,比如在推理能力方面,我们也在尝试把复杂任务分解为多个简单任务,并且引入其他模型解决;在工具方面,有一些 ALM 的输出中包含特定的 token,激活去调用规则;在行为方面,使用一些工具对虚拟和现实世界进行影响。
一、利用 CoT 增强模型复杂推理能力 我们对原有的模型通过 CoT 做个增强训练,能有效提升它的 Few-Shot 或者 Zero-Shot 的能力。
通过 CoT 可以显著增强模型在 GSM8K 数据集上的准确率
Mialon G, Dessì R, Lomeli M, et al. Augmented Language Models: a Survey[J]. arXiv preprint arXiv:2302.07842, 2023.
二、使用其他模型在商业领域长文档生成的需求很多,长文档生成工作可以引入其他模型和技术,叠加在当前的大语言模型上,来提升它的长文本的生成效能。
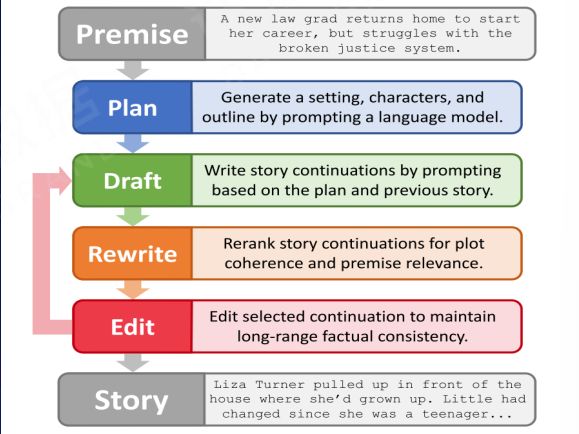
Yang K, Peng N, Tian Y, et al. Re3: Generating longer stories with recursive reprompting and revision[J]. arXiv preprint arXiv:2210.06774, 2022.
由上往下,当计算机做一个长文档的规划协作生成的内容,我们让相应的其他模型做一个生成后,引入分类模型,判断生成段落的上下文和相关性,把其他的模型的结果串连在当前的模型当中,能够进行迭代和顺序的循环调用,这样就能够突破现有当前大语言模型在特别长的文本当中生成的短板,能够提升它的写作效能。
三、使用垂直知识库
Izacard G, Lewis P, Lomeli M, et al. Few-shot learning with retrieval augmented language models[J]. arXiv preprint arXiv:2208.03299, 2022.
上图是使用外部语料库相应的一些算法研究出的成果。可以看到,小模型如果用外部语料库、专用语料库的模式,在有些任务上可以和大模型相媲美。而且应用场景广泛,实际落地中也探索了语言模型和知识图谱的交互。
四、使用搜索引擎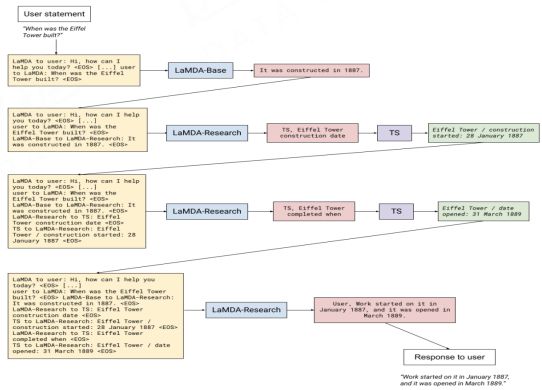
Thoppilan R, De Freitas D, Hall J, et al. Lamda: Language models for dialog applications[J]. arXiv preprint arXiv:2201.08239, 2022.
搜索引擎在传统意义上知识严重受限于语料库的实现,所以如果我们使用特定 token 激活或提示的方式生成查询语言,去请求搜索引擎的结果,并融合到当前模型的训练和输出当中,是可以很好的来弥补语料库更新不及时导致的很多信息滞后等问题。尤其是基于搜索引擎提供事实性的文档,使用外部搜索引擎来补充相关的语料资源,可以增强回答问题的可解释性,和用户的习惯对齐。
五、内容转换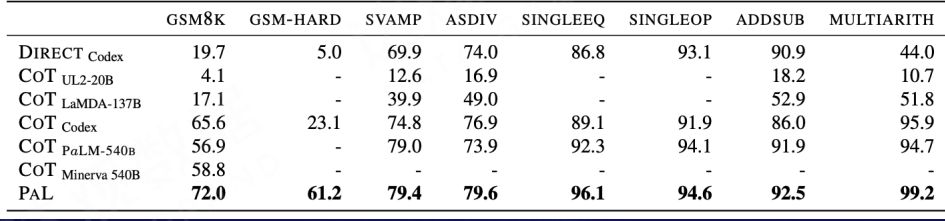
Gao L, Madaan A, Zhou S, et al. PAL: Program-aided Language Models[J]. arXiv preprint arXiv:2211.10435, 2022.
我们发现,在涉及数学领域的运算,今天的语言模型因为没有实质理解数学运算背后的含义,所以往往这个结果会做错。因此,我们可以利用 CoT 将复杂问题分解为若干个简单问题并生成可执行代码,然后利用代码解释器获得最终结果以辅助语言模型解决复杂推理问题。
总结
达观数据在垂直领域的语言模型方面的探索希望能够让大家对 LLM 的研发和落地有所启发。目前达观在研发“曹植模型”,未来希望能够为每个行业赋能。虽然大语言模型算力非常庞大,但模型当中仍有很多难题需要我们克服,我们相信“只要我们找到了路,就不怕路有多长”。
作者简介
陈运文,达观数据董事长兼CEO,复旦大学计算机博士,计算机技术专家,2021年中国青年创业奖,中国五四青年奖章,上海市十大青年科技杰出贡献奖获得者;国际计算机学会(ACM)、电子电器工程师学会(IEEE)、中国计算机学会(CCF)、中国人工智能学会(CAAI)高级会员;上海市首批人工智能正高级职称获得者。在人工智能领域拥有近百项国家技术发明专利,是复旦大学、上海财经大学、上海外国语学院聘任的校外研究生导师,在IEEE Transactions、SIGKDD等国际顶级学术期刊和会议上发表数十篇高水平科研成果论文;曾担任盛大文学首席数据官、腾讯文学高级总监、百度核心技术研发工程师。