
之前在这里零零碎碎介绍过不少自然语言处理开源工具,这些年随着深度学习以及预训练语言模型的崛起,NLP领域有了很大的进步和变化。准备在52nlp开启一个新的系列:自然语言处理开源工具系列介绍,无论老的新的,经典的非经典的,只要是开源的NLP工具,我都准备测评一下,刚好作为一个调研和学习的过程,并且尽量把它们的基础功能集成到AINLP公众号的NLP测试接口上。关于AINLP公众号上目前的NLP工具测试Demo,主要集中在基础的中文自然语言处理工具上,感兴趣的朋友可以关注AINLP公众号对话测试:

以下是AINLP测试平台上已经集成的NLP工具索引:
五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg, THULAC, HanLP
中文分词工具在线PK新增:FoolNLTK、LTP、StanfordCoreNLP
Python中文分词工具大合集:安装、使用和测试
八款中文词性标注工具使用及在线测试
百度深度学习中文词法分析工具LAC试用之旅
来,试试百度的深度学习情感分析工具
AINLP公众号新增SnowNLP情感分析模块
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
中文命名实体识别工具(NER)哪家强?
这次我们依然从经典的Python英文自然语言处理工具NLTK说起,这里我们不止一次推介过NLTK。NLTK 大概是早期最知名的Python自然语言处理工具,全称"Natural Language Toolkit", 诞生于宾夕法尼亚大学,以研究和教学为目的而生,因此也特别适合入门学习。NLTK虽然主要面向英文,但是它的很多NLP模型或者模块是语言无关的,因此如果某种语言有了初步的Tokenization或者分词,NLTK的很多工具包是可以复用的。
关于NLTK,网上已经有了很多介绍资料,当然首推的NLTK学习资料依然是官方出的在线书籍 NLTK Book:Natural Language Processing with Python – Analyzing Text with the Natural Language Toolkit ,目前基于Python 3 和 NLTK 3 ,可以在线免费阅读和学习。早期的时候还有一个基于Python 2 的老版本:http://www.nltk.org/book_1ed/ ,被 O'Reilly 正式出版过,2012年的时候,国内的陈涛同学无偿翻译过一个中文版,我还在这里推荐过:推荐《用Python进行自然语言处理》中文翻译-NLTK配套书 ,后来才有了基于此版本的更正式的中文翻译版:《Python自然语言处理》。不过如果英文ok的话,优先推荐看目前官方的最新版本:http://www.nltk.org/book/
几年前我尝试写英文博客,觉得可以从NLTK的入门介绍开始,所以写了一个英文系列:Dive into NLTK,基于Python 2,感兴趣的同学可以关注:
Part I: Getting Started with NLTK
Part II: Sentence Tokenize and Word Tokenize
Part III: Part-Of-Speech Tagging and POS Tagger
Part IV: Stemming and Lemmatization
Part V: Using Stanford Text Analysis Tools in Python
Part VI: Add Stanford Word Segmenter Interface for Python NLTK
Part VII: A Preliminary Study on Text Classification
Part VIII: Using External Maximum Entropy Modeling Libraries for Text Classification
Part IX: From Text Classification to Sentiment Analysis
Part X: Play With Word2Vec Models based on NLTK Corpus
Part XI: From Word2Vec to WordNet
这个过程中使用了NLTK中嵌入的斯坦福大学文本分析工具包,发现少了斯坦福中文分词器,所以当时动手加了一个:Python自然语言处理实践: 在NLTK中使用斯坦福中文分词器
斯坦福大学自然语言处理组是世界知名的NLP研究小组,他们提供了一系列开源的Java文本分析工具,包括分词器(Word Segmenter),词性标注工具(Part-Of-Speech Tagger),命名实体识别工具(Named Entity Recognizer),句法分析器(Parser)等,可喜的事,他们还为这些工具训练了相应的中文模型,支持中文文本处理。在使用NLTK的过程中,发现当前版本的NLTK已经提供了相应的斯坦福文本处理工具接口,包括词性标注,命名实体识别和句法分析器的接口,不过可惜的是,没有提供分词器的接口。在google无果和阅读了相应的代码后,我决定照猫画虎为NLTK写一个斯坦福中文分词器接口,这样可以方便的在Python中调用斯坦福文本处理工具。
后来,这个版本在 NLTK 3.2 官方版本中被正式引入:stanford_segmenter.py ,我也可以小自豪一下为NLTK做过一点微小的贡献:
好了,废话说得比较多,现在开始正式介绍NLTK的安装和使用。以下是在 ubuntu 20.04, python 3.8.10 环境下进行的安装测试,其他环境请自行测试。
首先建立一个venv的虚拟环境,同时在这个虚拟环境下安装 ipython (可选,便于测试)和 nltk:
python -m venv venv source venv/bin/activate pip install ipython pip install nltk |
安装完毕后,显示的 NLTK 安装版本是3.6.2:
Installing collected packages: tqdm, click, regex, joblib, nltk
Successfully installed click-8.0.1 joblib-1.0.1 nltk-3.6.2 regex-2021.8.3 tqdm-4.62.1
之后,通过ipython,可以快速测试一下 nltk 的英文 word tokenize 功能:
Python 3.8.10 (default, Jun 2 2021, 10:49:15) Type 'copyright', 'credits' or 'license' for more information IPython 7.26.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: import nltk In [2]: text = """The Natural Language Toolkit, or more commonly NLTK, is a suite of libraries and progra ...: ms for symbolic and statistical natural language processing (NLP) for English written in the Pyth ...: on programming language. It was developed by Steven Bird and Edward Loper in the Department of Co ...: mputer and Information Science at the University of Pennsylvania. NLTK includes graphical demo ...: nstrations and sample data. It is accompanied by a book that explains the underlying concepts beh ...: ind the language processing tasks supported by the toolkit plus a cookbook.""" In [3]: tokens = nltk.word_tokenize(text) ... LookupError: ********************************************************************** Resource punkt not found. Please use the NLTK Downloader to obtain the resource: >>> import nltk >>> nltk.download('punkt') For more information see: https://www.nltk.org/data.html Attempted to load tokenizers/punkt/PY3/english.pickle Searched in: - '/home/yzone/nltk_data' - '/home/yzone/textminer/nlp_tools/venv/nltk_data' - '/home/yzone/textminer/nlp_tools/venv/share/nltk_data' - '/home/yzone/textminer/nlp_tools/venv/lib/nltk_data' - '/usr/share/nltk_data' - '/usr/local/share/nltk_data' - '/usr/lib/nltk_data' - '/usr/local/lib/nltk_data' - '' ********************************************************************** |
这里提示 Lookup Error,因为NLTK的功能模块都对应有相应的模型数据,需要下载相关的模型,在错误提示中有相应的操作,我们按提示操作下载对应的'punkt'模型即可,然后国内情况比较特殊,无法直接下载这个模型:
In [4]: nltk.download('punkt') [nltk_data] Error loading punkt: <urlopen error [Errno 111] Connection [nltk_data] refused> Out[4]: False |
这里需要离线下载相关的数据或者模型。几年前,我从国外服务器上下载过完整的NLTK_DATA数据,然后scp到本地机器,基本上每次新安装NLTK之后都会把这份数据放在相应的目录下,NLTK的基础功能用起来基本都没有问题了。另外也可以通过github上nltk_data的存储路径上下载相关的数据,可以用参考文章中的方法,通过github或者gitee的镜像服务进行下载,不过这个方法我没有测试,请自行测试:
先去Github下载,点击右侧的clone or download 里面的download zip。安装包有点大,别急。
https://github.com/nltk/nltk_data/tree/gh-pages
下载得到nltk_data-gh-pages.zip文件。下载完成后还是pscp到服务器上,然后unzip解压。 oo 别忘了你把整包都下下来了,要把package里的内容挪到根目录下。
将文件中的packages文件夹重新命名为nltk_data
查询nltk搜索的目录
nltk.data.find(".")
将nltk_data放置在任意一个路径下即可
我将 nltk_data 放到了 /usr/local/share/ 目录下,可以看一下树形结构:
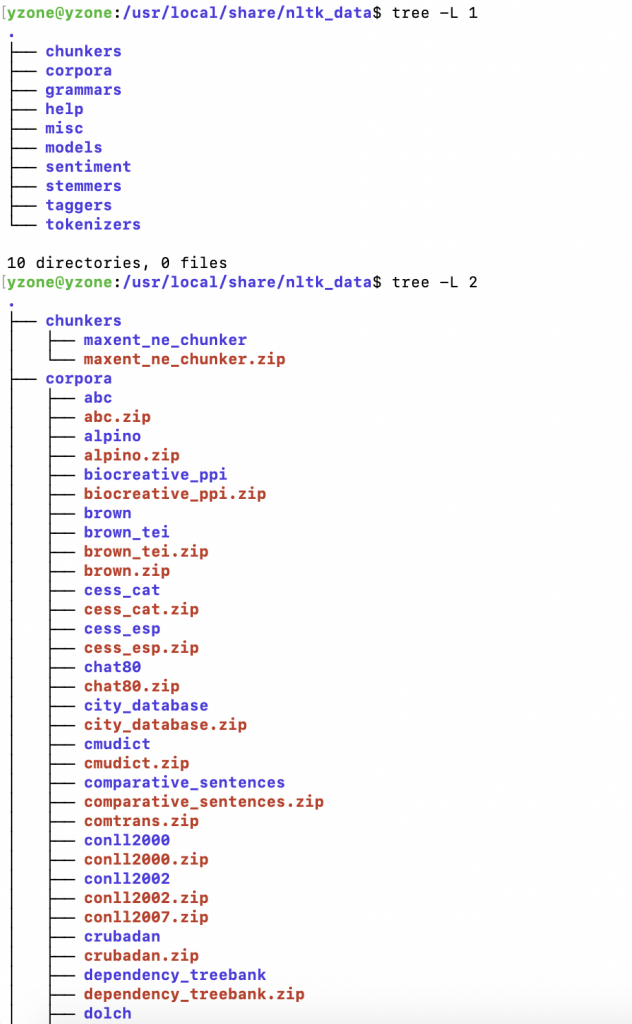
......
现在可以直接测试NLTK的基本功能和数据了:
Python 3.8.10 (default, Jun 2 2021, 10:49:15) Type 'copyright', 'credits' or 'license' for more information IPython 7.26.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: import nltk In [2]: text = "The Natural Language Toolkit, or more commonly NLTK, it's a suite of libraries and programs for ...: symbolic and statistical natural language processing (NLP) for English written in the Python programming ...: language. It was developed by Steven Bird and Edward Loper in the Department of Computer and Informatio ...: n Science at the University of Pennsylvania. NLTK includes graphical demonstrations and sample data. It ...: is accompanied by a book that explains the underlying concepts behind the language processing tasks supp ...: orted by the toolkit, plus a cookbook." # 测试英文 word tokenize 功能 In [3]: tokens = nltk.word_tokenize(text) In [4]: tokens[0:20] Out[4]: ['The', 'Natural', 'Language', 'Toolkit', ',', 'or', 'more', 'commonly', 'NLTK', ',', 'it', "'s", 'a', 'suite', 'of', 'libraries', 'and', 'programs', 'for', 'symbolic'] # 测试英文词性标注功能 In [5]: tagged_tokens = nltk.pos_tag(tokens) In [6]: tagged_tokens[0:20] Out[6]: [('The', 'DT'), ('Natural', 'NNP'), ('Language', 'NNP'), ('Toolkit', 'NNP'), (',', ','), ('or', 'CC'), ('more', 'JJR'), ('commonly', 'RB'), ('NLTK', 'NNP'), (',', ','), ('it', 'PRP'), ("'s", 'VBZ'), ('a', 'DT'), ('suite', 'NN'), ('of', 'IN'), ('libraries', 'NNS'), ('and', 'CC'), ('programs', 'NNS'), ('for', 'IN'), ('symbolic', 'JJ')] # 测试英文断句功能 In [8]: sents = nltk.sent_tokenize(text) In [9]: sents Out[9]: ["The Natural Language Toolkit, or more commonly NLTK, it's a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language.", 'It was developed by Steven Bird and Edward Loper in the Department of Computer and Information Science at the University of Pennsylvania.', 'NLTK includes graphical demonstrations and sample data.', 'It is accompanied by a book that explains the underlying concepts behind the language processing tasks supported by the toolkit, plus a cookbook.'] # 测试英文命名实体标注功能 In [10]: entities = nltk.chunk.ne_chunk(tagged_tokens) --------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) <ipython-input-10-a85268718ce4> in <module> ----> 1 entities = nltk.chunk.ne_chunk(tagged_tokens) ~/textminer/nlp_tools/venv/lib/python3.8/site-packages/nltk/chunk/__init__.py in ne_chunk(tagged_tokens, binary) 183 else: 184 chunker_pickle = _MULTICLASS_NE_CHUNKER --> 185 chunker = load(chunker_pickle) 186 return chunker.parse(tagged_tokens) 187 ~/textminer/nlp_tools/venv/lib/python3.8/site-packages/nltk/data.py in load(resource_url, format, cache, verbose, logic_parser, fstruct_reader, encoding) 753 resource_val = opened_resource.read() 754 elif format == "pickle": --> 755 resource_val = pickle.load(opened_resource) 756 elif format == "json": 757 import json ModuleNotFoundError: No module named 'numpy' # 发现缺少 numpy 模块,直接 pip install 安装 In [11]: pip install numpy Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Collecting numpy Downloading https://pypi.tuna.tsinghua.edu.cn/packages/aa/69/260a4a1cc89cc00b51f432db048c396952f5c05dfa1345a1b3dbd9ea3544/numpy-1.21.2-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.8 MB) |████████████████████████████████| 15.8 MB 11.2 MB/s Installing collected packages: numpy Successfully installed numpy-1.21.2 Note: you may need to restart the kernel to use updated packages. # 继续测试英文命名实体识别 In [12]: entities = nltk.chunk.ne_chunk(tagged_tokens) In [13]: entities Out[13]: Tree('S', [('The', 'DT'), Tree('ORGANIZATION', [('Natural', 'NNP'), ('Language', 'NNP'), ('Toolkit', 'NNP')]), (',', ','), ('or', 'CC'), ('more', 'JJR'), ('commonly', 'RB'), Tree('ORGANIZATION', [('NLTK', 'NNP')]), (',', ','), ('it', 'PRP'), ("'s", 'VBZ'), ('a', 'DT'), ('suite', 'NN'), ('of', 'IN'), ('libraries', 'NNS'), ('and', 'CC'), ('programs', 'NNS'), ('for', 'IN'), ('symbolic', 'JJ'), ('and', 'CC'), ('statistical', 'JJ'), ('natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('(', '('), Tree('ORGANIZATION', [('NLP', 'NNP')]), (')', ')'), ('for', 'IN'), Tree('GPE', [('English', 'NNP')]), ('written', 'VBN'), ('in', 'IN'), ('the', 'DT'), Tree('GPE', [('Python', 'NNP')]), ('programming', 'NN'), ('language', 'NN'), ('.', '.'), ('It', 'PRP'), ('was', 'VBD'), ('developed', 'VBN'), ('by', 'IN'), Tree('PERSON', [('Steven', 'NNP'), ('Bird', 'NNP')]), ('and', 'CC'), Tree('PERSON', [('Edward', 'NNP'), ('Loper', 'NNP')]), ('in', 'IN'), ('the', 'DT'), Tree('ORGANIZATION', [('Department', 'NNP')]), ('of', 'IN'), Tree('ORGANIZATION', [('Computer', 'NNP')]), ('and', 'CC'), Tree('ORGANIZATION', [('Information', 'NNP'), ('Science', 'NNP')]), ('at', 'IN'), ('the', 'DT'), Tree('ORGANIZATION', [('University', 'NNP')]), ('of', 'IN'), Tree('GPE', [('Pennsylvania', 'NNP')]), ('.', '.'), Tree('ORGANIZATION', [('NLTK', 'NNP')]), ('includes', 'VBZ'), ('graphical', 'JJ'), ('demonstrations', 'NNS'), ('and', 'CC'), ('sample', 'JJ'), ('data', 'NNS'), ('.', '.'), ('It', 'PRP'), ('is', 'VBZ'), ('accompanied', 'VBN'), ('by', 'IN'), ('a', 'DT'), ('book', 'NN'), ('that', 'WDT'), ('explains', 'VBZ'), ('the', 'DT'), ('underlying', 'JJ'), ('concepts', 'NNS'), ('behind', 'IN'), ('the', 'DT'), ('language', 'NN'), ('processing', 'NN'), ('tasks', 'NNS'), ('supported', 'VBN'), ('by', 'IN'), ('the', 'DT'), ('toolkit', 'NN'), (',', ','), ('plus', 'CC'), ('a', 'DT'), ('cookbook', 'NN'), ('.', '.')]) |
这里分别测试了NLTK中的英文NLP功能,包括 Word Tokenize (中文翻译我感觉没有合适的),词性标注(Pos Tagging),自动断句(Sentence Tokenize),命名实体识别(NER)等自然语言处理的基础功能。
NLTK的基础功能可能对应有多个模型模块,以英文 Word Tokenize 为例,默认的接口用得是宾州树库word tokenizer ,源代码是:
# Standard word tokenizer. _word_tokenize = TreebankWordTokenizer().tokenize def word_tokenize(text): """ Return a tokenized copy of *text*, using NLTK's recommended word tokenizer (currently :class:`.TreebankWordTokenizer`). This tokenizer is designed to work on a sentence at a time. """ return _word_tokenize(text) |
可以直接调用这个接口 TreebankWordTokenizer,和默认的 word tokenizer 结果是一致的:
In [15]: from nltk.tokenize import TreebankWordTokenizer In [16]: tokenizer = TreebankWordTokenizer() In [17]: tokenizer.tokenize("This's one of the best NLP tools I've ever used") Out[17]: ['This', "'s", 'one', 'of', 'the', 'best', 'NLP', 'tools', 'I', "'ve", 'ever', 'used'] |
NLTK 的 Tokenize 模块还提供了其他 Word Tokenizer 接口,例如 WordPunctTokenizer ,这个接口在 tokenize 的时候会将标点独立提取出来:
In [21]: from nltk.tokenize import WordPunctTokenizer In [22]: tokenizer = WordPunctTokenizer() In [23]: tokenizer.tokenize("This's one of the best NLP tools I've ever used") Out[23]: ['This', "'", 's', 'one', 'of', 'the', 'best', 'NLP', 'tools', 'I', "'", 've', 'ever', 'used'] |
更多tokenize接口可以参考NLTK的官方文档:https://www.nltk.org/api/nltk.tokenize.html
当然,英文预处理阶段不仅仅包括 Word Tokenize,还有 Word Stemming(词干提取) 以及 Word Lemmatization(词形还原),NLTK同样提供了多种工具接口。以下,我们先测试几个著名的词干提取工具:Porter Stemmer, Snowball Stemmer, Lancaster Stemmer
In [24]: In [24]: from nltk.stem.porter import PorterStemmer In [25]: porter_stemmer = PorterStemmer() In [29]: plurals = ['caresses', 'flies', 'dies', 'mules', 'denied', ...: 'died', 'agreed', 'owned', 'humbled', 'sized', ...: 'meeting', 'stating', 'siezing', 'itemization', ...: 'sensational', 'traditional', 'reference', 'colonizer', ...: 'plotted'] In [30]: singles = [porter_stemmer.stem(plural) for plural in plurals] In [31]: singles Out[31]: ['caress', 'fli', 'die', 'mule', 'deni', 'die', 'agre', 'own', 'humbl', 'size', 'meet', 'state', 'siez', 'item', 'sensat', 'tradit', 'refer', 'colon', 'plot'] In [33]: from nltk.stem.snowball import SnowballStemmer # Snowball Stemmer 支持多种语言,这里需要指定英文包 In [34]: snowball_stemmer = SnowballStemmer("english") In [35]: singles = [snowball_stemmer.stem(plural) for plural in plurals] In [36]: singles Out[36]: ['caress', 'fli', 'die', 'mule', 'deni', 'die', 'agre', 'own', 'humbl', 'size', 'meet', 'state', 'siez', 'item', 'sensat', 'tradit', 'refer', 'colon', 'plot'] In [37]: from nltk.stem.lancaster import LancasterStemmer In [38]: lancaster_stemmer = LancasterStemmer() In [39]: singles = [lancaster_stemmer.stem(plural) for plural in plurals] In [40]: singles Out[40]: ['caress', 'fli', 'die', 'mul', 'deny', 'died', 'agree', 'own', 'humbl', 'siz', 'meet', 'stat', 'siez', 'item', 'sens', 'tradit', 'ref', 'colon', 'plot'] |
最后我们来测试一下 NLTK 的英文词形还原功能(Word Lemmatization),这个和词干提取(Word Stemming) 很像,但是还是有很大的不同。NLTK的词形还原功能是基于著名的 WordNet 内置的 morphy 接口做得:
In [41]: from nltk.stem import WordNetLemmatizer In [42]: wordnet_lemmatizer = WordNetLemmatizer() In [43]: singles = [wordnet_lemmatizer.lemmatize(plural) for plural in plurals] In [44]: singles Out[44]: ['caress', 'fly', 'dy', 'mule', 'denied', 'died', 'agreed', 'owned', 'humbled', 'sized', 'meeting', 'stating', 'siezing', 'itemization', 'sensational', 'traditional', 'reference', 'colonizer', 'plotted'] In [45]: wordnet_lemmatizer.lemmatize('are') Out[45]: 'are' In [46]: wordnet_lemmatizer.lemmatize('is') Out[46]: 'is' |
上述词形还原结果确实和词干提取的结果有很大区别,如果你对英文语法比较熟悉,可能会注意到最后的两个例子 "are" 和 "is" 的词性还原应该是 "be", 但是 NLTK 中这个wordnet lemmatizer 的接口似乎没有起作用,其实它的lemmatize函数还有一个pos参数, 默认是名词词性tag 'n',可以传一个动词词性tag 'v' 给它试试:
In [47]: wordnet_lemmatizer.lemmatize('are', pos='v') Out[47]: 'be' In [48]: wordnet_lemmatizer.lemmatize('is', pos='v') Out[48]: 'be' |
所以在使用WordNet这个词形还原接口时特别注意需要同时传入相应的词性tag参数才能得到最佳的结果。
上述接口我们已经集成在了AINLP公众号的NLP测试模块里,感兴趣的同学可以直接关注AINLP公众号:
回复“NLTK 英文内容”进行测试:

最后需要说明的是,这里我们只是简单介绍了一下NLTK的英文基础功能和接口,NLTK不止于此,它还包括很多语料模型和工具,感兴趣的同学可以通过阅读NLTK官方文档或者配套书籍进行相应的学习。
参考:
NLTK官网:https://www.nltk.org/
NLTK官方配套书籍:http://www.nltk.org/book/
TextMining NLTK 系列:https://textminingonline.com/category/nltk
词性标注:https://en.wikipedia.org/wiki/Part-of-speech_tagging
自动断句:https://en.wikipedia.org/wiki/Sentence_boundary_disambiguation
词干提取:https://en.wikipedia.org/wiki/Stemming
词形还原:https://en.wikipedia.org/wiki/Lemmatisation
Poter Stemmer: https://tartarus.org/martin/PorterStemmer/
Snowball Stemmer: http://snowball.tartarus.org/
Lancaster Stemmer:
http://www.comp.lancs.ac.uk/computing/research/stemming/
WordNet: http://wordnet.princeton.edu/