

在上一篇文章中,介绍了数据集的设计,该语料可以用于研究和学习,从规模和质量上,是目前中文问答语料中,保险行业垂直领域最优秀的语料,关于该语料制作过程可以通过语料主页了解,本篇的主要内容是使用该语料实现一个简单的问答模型,并且给出准确度和损失函数作为数据集的Baseline。
DeepQA-1
为了展示如何使用该语料训练模型和评测算法,我做了一个示例项目 - DeepQA-1,本文接下来会介绍DeepQA-1,假设读者了解深度学习基本概念和Python语言。
Data Loader
数据加载包含两部分:加载语料和预处理。 加载数据使用 insuranceqa_data 载入训练,测试和验证集的数据。

预处理是按照模型的超参数处理问题和答案,将它们组合成输入需要的格式,在本文介绍的baseline model中,预处理包含下面工作:
- 在词汇表(vocab)中添加辅助Token: <PAD>, <GO>. 假设x是问题序列,是u回复序列,输入序列可以表示为:
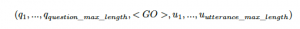
超参数question_max_length代表模型中问题的最大长度。 超参数utterance_max_length代表模型中回复的最大长度,回复可能是正例,也可能是负例。

其中,Token <GO> 用来分隔问题和回复,Token <PAD> 用来补齐问题或回复。
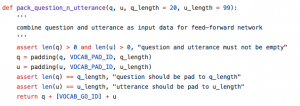
训练数据包含了141,779条,正例:负例=1:10,根据超参数生成输入序列:
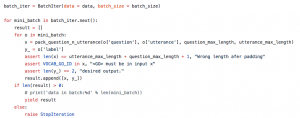
上图 中 x 就是输入序列。y_代表标注数据:正例还是负例,正例标为[1,0],负例标为[0,1],这样做的好处是方便计算损失函数和准确度。测试数据和验证数据也用同样的方式进行处理,唯一不同的是它们不需要做成mini-batch。需要强调的是,处理词汇表和构建输入序列的方式可以尝试用不同的方法,上述方案仅作为表达baseline结果而采用,一些有助于增强模型能力的,比如使用word2vec训练词向量都值得尝试。
Network
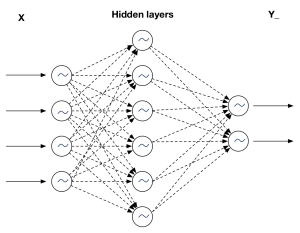
baseline model使用了最简单的神经网络,输入序列从左侧进入,输出序列输出包含2个数值的vector,然后使用损失函数计算误差。
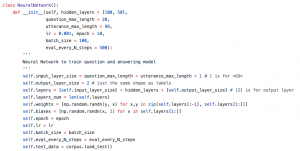
超参数,Hyper params

损失函数
神经网络的激活函数使用函数,损失函数使用最大似然的思想。
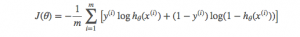

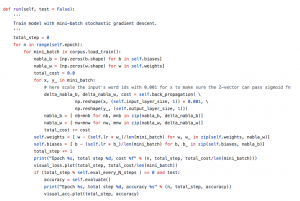
迭代训练
使用mini-batch加载数据,迭代训练的大部分工作在back_propagation中完成,它计算出每次迭代的损失和b,W 的误差率,然后使用学习率和误差率更新每个b,W 。
执行训练脚本
python3 deep_qa_1/network.py
Visual
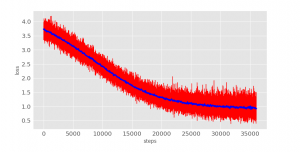
在训练过程中,观察损失函数和准确度的变化可以帮助优化超参数的设计。
loss
python3 visual/loss.py
accuracy
python3 visual/accuracy.py
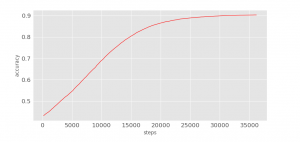
在迭代了25,000步后就基本维持在一个固定值,学习停止了。
Baseline
使用获得的Baseline数据为:
Epoch 25, total step 36400, accuracy 0.9031, cost 1.056221.
总结
Baseline model设计的非常简单,它展示了如何使用insuranceqa-corpus-zh训练FAQ问答模型,项目的源码参考这里。在过去两周中,为了能让这个数据集能满足使用,体现其价值,我花了很多时间来建设,仓促之中仍然会包含一些不足,比如数据集中,每个问题是唯一的,不包含相似问题,是这个数据集目前最大的缺陷,另外一方面,因为该数据集的回复包含一个正例和多个负例,可以用用于训练分类器,也可以用于训练ranking model。如果在使用的过程中,遇到任何问题,可以通过数据集的地址 反馈。
博主你好,我是新人,我想问一下是否可以直接将语料库的中文进行分词,然后利用Word2vec工具算好没个词的向量,然后在用训练好的词向量组成原来的中文的问答对(训练集+测试集+验证集),然后再利用深度学习的方法对进行训练得到结果?期待回答
[回复]
huadidi 回复:
23 10 月, 2017 at 19:07
你好,请问博主写的这个代码,是在pycharm中执行的吗?
[回复]
hain 回复:
23 10 月, 2017 at 19:09
不是,就是在命令行窗口执行python。
[回复]
huadidi 回复:
24 10 月, 2017 at 22:55
我下载了整个代码,但是在pycharm中运行不了,那如何装载数据呢?
在baseline中,我用wordId作为标识生成句向量,这个方法和用word2vec训练词向量,然后通过词的SUM或CONCAT方式组成句向量,效果肯定不一样,可以从精度上得到对比。我觉得使用word2vec的一个前提是大数据,这样才能计算出语义上相近的词汇,使得模型更具有通用性,基于这个想法,我也有用word2vec训练了一个近义词的库,可通过 https://github.com/huyingxi/Synonyms 了解。
[回复]
huadidi 回复:
25 10 月, 2017 at 10:45
我运行network出现错误
[回复]
我也出错了。。
[回复]
huadidi 回复:
30 10 月, 2017 at 09:20
你的现在怎么样
[回复]
感觉读取数据写的好复杂啊看不懂。。。
[回复]
我能问个问题么为什么训练的都是英文预料,没有中文的语料库么,质量高的
[回复]
52nlp 回复:
20 11 月, 2018 at 14:59
中文语料本身就少,质量高的更少或者没有开放
[回复]