众所周知,斯坦福大学自然语言处理组出品了一系列NLP工具包,但是大多数都是用Java写得,对于Python用户不是很友好。几年前我曾基于斯坦福Java工具包和NLTK写过一个简单的中文分词接口:Python自然语言处理实践: 在NLTK中使用斯坦福中文分词器,不过用起来也不是很方便。深度学习自然语言处理时代,斯坦福大学自然语言处理组开发了一个纯Python版本的深度学习NLP工具包:Stanza - A Python NLP Library for Many Human Languages,前段时间,Stanza v1.0.0 版本正式发布,算是一个里程碑:
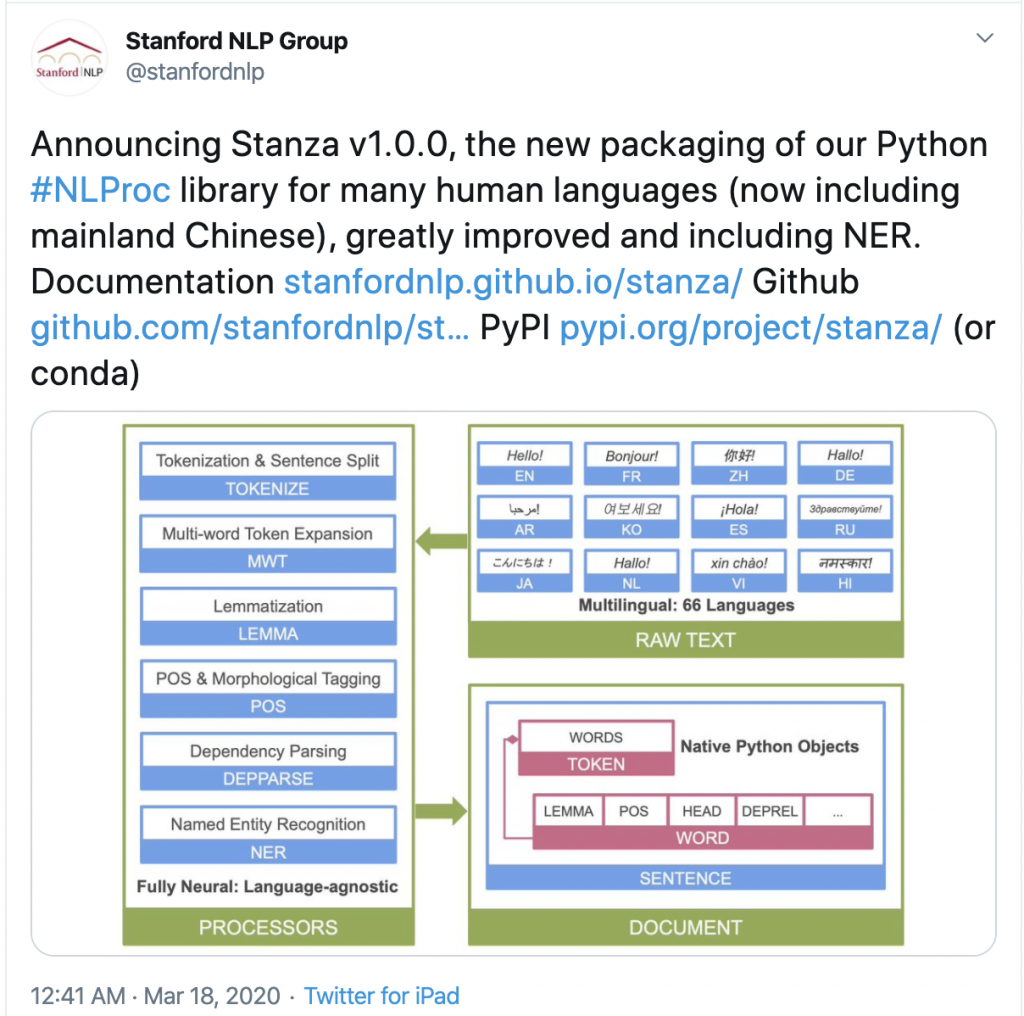
Stanza 是一个纯Python实现的自然语言处理工具包,这个区别于斯坦福大学自然语言处理组之前一直维护的Java实现 CoreNLP 等自然语言处理工具包,对于Python用户来说,就更方便调用了,并且Stanza还提供了一个Python接口可用于CoreNLP的调用 ,对于一些没有在Stanza中实现的NLP功能,可以通过这个接口调用 CoreNLP 作为补充。 Stanza的深度学习自然语言处理模块基于PyTorch实现,用户可以基于自己标注的数据构建更准确的神经网络模型用于训练、评估和使用,当然,如果有GPU机器加持,速度可以更快。Stanza目前支持66种语言的文本分析,包括自动断句、Tokenize(或者分词)、词性标注和形态素分析、依存句法分析以及命名实体识别。
To summarize, Stanza features:
Native Python implementation requiring minimal efforts to set up;
Full neural network pipeline for robust text analytics, including tokenization, multi-word token (MWT) expansion, lemmatization, part-of-speech (POS) and morphological features tagging, dependency parsing, and named entity recognition;
Pretrained neural models supporting 66 (human) languages;
A stable, officially maintained Python interface to CoreNLP.
试用了一下Stanza,还是很方便的,官方文档很清晰,可以直接参考。简单记录一下中英文模块的安装和使用,以下是在Ubuntu16.04, Python 3.6.8 环境下,请注意,Stanza需要Python3.6及以上的版本,如果低于这个版本,用 pip install stanza 安装的stanza非斯坦福大学NLP组的Stanza。
安装Stanza的方法有多种,这里是virtualenv虚拟环境下通过 pip install stanza 安装stanza及其相关依赖的,具体可以参考Stanza的安装文档:https://stanfordnlp.github.io/stanza/installation_usage.html
安装完成后,可以尝试使用,不过使用某种语言的NLP工具包时,还需要先下载相关的打包模型,这个在第一次使用时会有提示和操作,以后就无需下载了,我们先从斯坦福官方的例子走起,以英文为例:
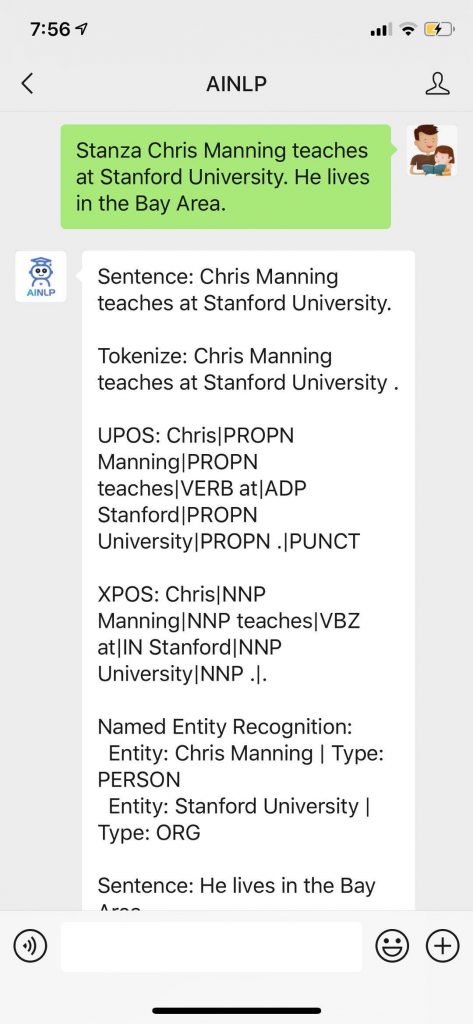
In [1]: import stanza # 这里因为已经下载过英文模型打包文件,所以可以直接使用,如果没有下载过,初次使用会有一个下载过程 In [2]: stanza.download('en') Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/master/resources_1.0.0.Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/master/resources_1.0.0.json: 116kB [00:00, 154kB/s] 2020-04-11 23:13:14 INFO: Downloading default packages for language: en (English)... 2020-04-11 23:13:15 INFO: File exists: /home/textminer/stanza_resources/en/default.zip. 2020-04-11 23:13:19 INFO: Finished downloading models and saved to /home/textminer/stanza_resources. # Pipeline是Stanza里一个重要的概念 In [3]: en_nlp = stanza.Pipeline('en') 2020-04-11 23:14:27 INFO: Loading these models for language: en (English): ========================= | Processor | Package | ------------------------- | tokenize | ewt | | pos | ewt | | lemma | ewt | | depparse | ewt | | ner | ontonotes | ========================= 2020-04-11 23:14:28 INFO: Use device: gpu 2020-04-11 23:14:28 INFO: Loading: tokenize 2020-04-11 23:14:30 INFO: Loading: pos 2020-04-11 23:14:30 INFO: Loading: lemma 2020-04-11 23:14:30 INFO: Loading: depparse 2020-04-11 23:14:31 INFO: Loading: ner 2020-04-11 23:14:32 INFO: Done loading processors! In [5]: doc = en_nlp("Barack Obama was born in Hawaii.") In [6]: print(doc) [ [ { "id": "1", "text": "Barack", "lemma": "Barack", "upos": "PROPN", "xpos": "NNP", "feats": "Number=Sing", "head": 4, "deprel": "nsubj:pass", "misc": "start_char=0|end_char=6" }, { "id": "2", "text": "Obama", "lemma": "Obama", "upos": "PROPN", "xpos": "NNP", "feats": "Number=Sing", "head": 1, "deprel": "flat", "misc": "start_char=7|end_char=12" }, { "id": "3", "text": "was", "lemma": "be", "upos": "AUX", "xpos": "VBD", "feats": "Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin", "head": 4, "deprel": "aux:pass", "misc": "start_char=13|end_char=16" }, { "id": "4", "text": "born", "lemma": "bear", "upos": "VERB", "xpos": "VBN", "feats": "Tense=Past|VerbForm=Part|Voice=Pass", "head": 0, "deprel": "root", "misc": "start_char=17|end_char=21" }, { "id": "5", "text": "in", "lemma": "in", "upos": "ADP", "xpos": "IN", "head": 6, "deprel": "case", "misc": "start_char=22|end_char=24" }, { "id": "6", "text": "Hawaii", "lemma": "Hawaii", "upos": "PROPN", "xpos": "NNP", "feats": "Number=Sing", "head": 4, "deprel": "obl", "misc": "start_char=25|end_char=31" }, { "id": "7", "text": ".", "lemma": ".", "upos": "PUNCT", "xpos": ".", "head": 4, "deprel": "punct", "misc": "start_char=31|end_char=32" } ] ] In [7]: print(doc.entities) [{ "text": "Barack Obama", "type": "PERSON", "start_char": 0, "end_char": 12 }, { "text": "Hawaii", "type": "GPE", "start_char": 25, "end_char": 31 }] |
Pipeline是Stanza里的一个重要概念:

可以通过pipeline预加载不同语言的模型,也可以通过pipeline选择不同的处理模块,还可以选择是否使用GPU,这里我们再试试中文模型:
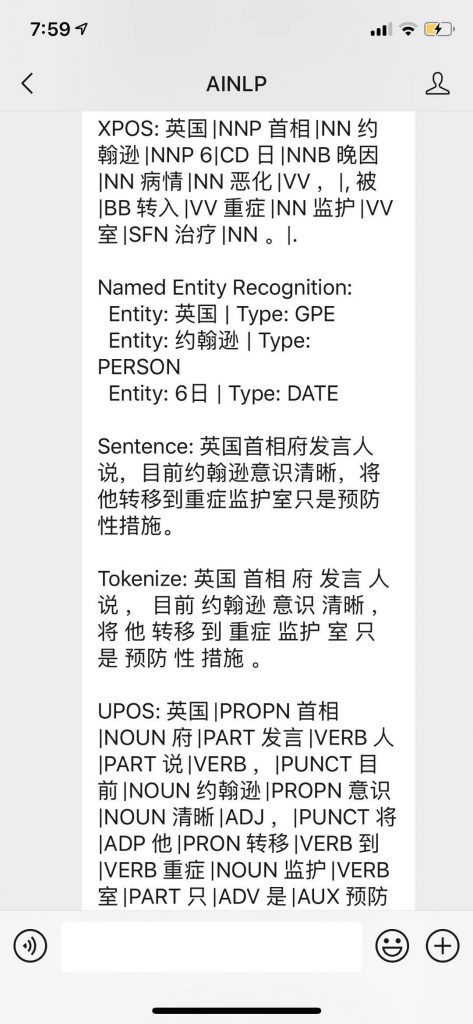
In [9]: import stanza # 测试一下中文模型(因为我这边中文模型已经下载过了,所以跳过download环节) In [10]: zh_nlp = stanza.Pipeline('zh') 2020-04-12 11:32:47 INFO: "zh" is an alias for "zh-hans" 2020-04-12 11:32:47 INFO: Loading these models for language: zh-hans (Simplified_Chinese): ========================= | Processor | Package | ------------------------- | tokenize | gsdsimp | | pos | gsdsimp | | lemma | gsdsimp | | depparse | gsdsimp | | ner | ontonotes | ========================= 2020-04-12 11:32:48 INFO: Use device: gpu 2020-04-12 11:32:48 INFO: Loading: tokenize 2020-04-12 11:32:49 INFO: Loading: pos 2020-04-12 11:32:51 INFO: Loading: lemma 2020-04-12 11:32:51 INFO: Loading: depparse 2020-04-12 11:32:53 INFO: Loading: ner 2020-04-12 11:32:54 INFO: Done loading processors! In [11]: text = """英国首相约翰逊6日晚因病情恶化,被转入重症监护室治疗。英国首相府发言人说,目前约 ...: 翰逊意识清晰,将他转移到重症监护室只是预防性措施。发言人说,约翰逊被转移到重症监护室前已 ...: 安排英国外交大臣拉布代表他处理有关事务。""" In [12]: doc = zh_nlp(text) In [13]: for sent in doc.sentences: ...: print("Sentence:" + sent.text) # 断句 ...: print("Tokenize:" + ' '.join(token.text for token in sent.tokens)) # 中文分词 ...: print("UPOS: " + ' '.join(f'{word.text}/{word.upos}' for word in sent.words)) # 词性标注(UPOS) ...: print("XPOS: " + ' '.join(f'{word.text}/{word.xpos}' for word in sent.words)) # 词性标注(XPOS) ...: print("NER: " + ' '.join(f'{ent.text}/{ent.type}' for ent in sent.ents)) # 命名实体识别 ...: Sentence:英国首相约翰逊6日晚因病情恶化,被转入重症监护室治疗。 Tokenize:英国 首相 约翰逊 6 日 晚因 病情 恶化 , 被 转入 重症 监护 室 治疗 。 UPOS: 英国/PROPN 首相/NOUN 约翰逊/PROPN 6/NUM 日/NOUN 晚因/NOUN 病情/NOUN 恶化/VERB ,/PUNCT 被/VERB 转入/VERB 重症/NOUN 监护/VERB 室/PART 治疗/NOUN 。/PUNCT XPOS: 英国/NNP 首相/NN 约翰逊/NNP 6/CD 日/NNB 晚因/NN 病情/NN 恶化/VV ,/, 被/BB 转入/VV 重症/NN 监护/VV 室/SFN 治疗/NN 。/. NER: 英国/GPE 约翰逊/PERSON 6日/DATE Sentence:英国首相府发言人说,目前约翰逊意识清晰,将他转移到重症监护室只是预防性措施。 Tokenize:英国 首相 府 发言 人 说 , 目前 约翰逊 意识 清晰 , 将 他 转移 到 重症 监护 室 只 是 预防 性 措施 。 UPOS: 英国/PROPN 首相/NOUN 府/PART 发言/VERB 人/PART 说/VERB ,/PUNCT 目前/NOUN 约翰逊/PROPN 意识/NOUN 清晰/ADJ ,/PUNCT 将/ADP 他/PRON 转移/VERB 到/VERB 重症/NOUN 监护/VERB 室/PART 只/ADV 是/AUX 预防/VERB 性/PART 措施/NOUN 。/PUNCT XPOS: 英国/NNP 首相/NN 府/SFN 发言/VV 人/SFN 说/VV ,/, 目前/NN 约翰逊/NNP 意识/NN 清晰/JJ ,/, 将/BB 他/PRP 转移/VV 到/VV 重症/NN 监护/VV 室/SFN 只/RB 是/VC 预防/VV 性/SFN 措施/NN 。/. NER: 英国/GPE 约翰逊/PERSON Sentence:发言人说,约翰逊被转移到重症监护室前已安排英国外交大臣拉布代表他处理有关事务。 Tokenize:发言 人 说 , 约翰逊 被 转移 到 重症 监护 室 前 已 安排 英国 外交 大臣 拉布 代表 他 处理 有关 事务 。 UPOS: 发言/VERB 人/PART 说/VERB ,/PUNCT 约翰逊/PROPN 被/VERB 转移/VERB 到/VERB 重症/NOUN 监护/VERB 室/PART 前/ADP 已/ADV 安排/VERB 英国/PROPN 外交/NOUN 大臣/NOUN 拉布/PROPN 代表/VERB 他/PRON 处理/VERB 有关/ADJ 事务/NOUN 。/PUNCT XPOS: 发言/VV 人/SFN 说/VV ,/, 约翰逊/NNP 被/BB 转移/VV 到/VV 重症/NN 监护/VV 室/SFN 前/IN 已/RB 安排/VV 英国/NNP 外交/NN 大臣/NN 拉布/NNP 代表/VV 他/PRP 处理/VV 有关/JJ 事务/NN 。/. NER: 约翰逊/PERSON 英国/GPE 拉布/PERSON |
如果用户不需要使用命名实体识别、依存句法等功能,可以在模型下载或者预加载阶段或者构建Pipeline时选择自己需要的功能模块处理器,例如可以只选择中文分词和词性标注,或者单一的中文分词功能,这里以“我爱自然语言处理”为例:
# 可以在使用时只选择自己需要的功能,这样下载的模型包更小,节约时间,这里因为之前已经下载过全量的中文模型,所以不再有下载过程,只是用于演示 In [14]: stanza.download('zh', processors='tokenize,pos') Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/master/resources_1.0.0.Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/master/resources_1.0.0.json: 116kB [00:00, 554kB/s] 2020-04-15 07:27:38 INFO: "zh" is an alias for "zh-hans" 2020-04-15 07:27:38 INFO: Downloading these customized packages for language: zh-hans (Simplified_Chinese)... ======================= | Processor | Package | ----------------------- | tokenize | gsdsimp | | pos | gsdsimp | | pretrain | gsdsimp | ======================= 2020-04-15 07:27:38 INFO: File exists: /home/textminer/stanza_resources/zh-hans/tokenize/gsdsimp.pt. 2020-04-15 07:27:38 INFO: File exists: /home/textminer/stanza_resources/zh-hans/pos/gsdsimp.pt. 2020-04-15 07:27:39 INFO: File exists: /home/textminer/stanza_resources/zh-hans/pretrain/gsdsimp.pt. 2020-04-15 07:27:39 INFO: Finished downloading models and saved to /home/textminer/stanza_resources. # 构建Pipeline时选择中文分词和词性标注,对其他语言同理 In [15]: zh_nlp = stanza.Pipeline('zh', processors='tokenize,pos') 2020-04-15 07:28:12 INFO: "zh" is an alias for "zh-hans" 2020-04-15 07:28:12 INFO: Loading these models for language: zh-hans (Simplified_Chinese): ======================= | Processor | Package | ----------------------- | tokenize | gsdsimp | | pos | gsdsimp | ======================= 2020-04-15 07:28:13 INFO: Use device: gpu 2020-04-15 07:28:13 INFO: Loading: tokenize 2020-04-15 07:28:15 INFO: Loading: pos 2020-04-15 07:28:17 INFO: Done loading processors! In [16]: doc = zh_nlp("我爱自然语言处理") In [17]: print(doc) [ [ { "id": "1", "text": "我", "upos": "PRON", "xpos": "PRP", "feats": "Person=1", "misc": "start_char=0|end_char=1" }, { "id": "2", "text": "爱", "upos": "VERB", "xpos": "VV", "misc": "start_char=1|end_char=2" }, { "id": "3", "text": "自然", "upos": "NOUN", "xpos": "NN", "misc": "start_char=2|end_char=4" }, { "id": "4", "text": "语言", "upos": "NOUN", "xpos": "NN", "misc": "start_char=4|end_char=6" }, { "id": "5", "text": "处理", "upos": "VERB", "xpos": "VV", "misc": "start_char=6|end_char=8" } ] ] # 这里单独使用Stanza的中文分词器 In [18]: zh_nlp = stanza.Pipeline('zh', processors='tokenize') 2020-04-15 07:31:27 INFO: "zh" is an alias for "zh-hans" 2020-04-15 07:31:27 INFO: Loading these models for language: zh-hans (Simplified_Chinese): ======================= | Processor | Package | ----------------------- | tokenize | gsdsimp | ======================= 2020-04-15 07:31:27 INFO: Use device: gpu 2020-04-15 07:31:27 INFO: Loading: tokenize 2020-04-15 07:31:27 INFO: Done loading processors! In [19]: doc = zh_nlp("我爱自然语言处理") In [20]: print(doc) [ [ { "id": "1", "text": "我", "misc": "start_char=0|end_char=1" }, { "id": "2", "text": "爱", "misc": "start_char=1|end_char=2" }, { "id": "3", "text": "自然", "misc": "start_char=2|end_char=4" }, { "id": "4", "text": "语言", "misc": "start_char=4|end_char=6" }, { "id": "5", "text": "处理", "misc": "start_char=6|end_char=8" } ] ] |
在Pipeline构建时,除了选择不同的功能模块处理器外,对于有多个模型可以选择使用的功能模块,也可以指定需要使用哪个模型,另外也可以指定Log级别,这些可以参考官方文档。还有一点,如果你觉得使用GPU没有必要,还可以选择使用CPU:
In [21]: zh_doc = stanza.Pipeline('zh', use_gpu=False) 2020-04-15 07:44:04 INFO: "zh" is an alias for "zh-hans" 2020-04-15 07:44:04 INFO: Loading these models for language: zh-hans (Simplified_Chinese): ========================= | Processor | Package | ------------------------- | tokenize | gsdsimp | | pos | gsdsimp | | lemma | gsdsimp | | depparse | gsdsimp | | ner | ontonotes | ========================= 2020-04-15 07:44:04 INFO: Use device: cpu 2020-04-15 07:44:04 INFO: Loading: tokenize 2020-04-15 07:44:04 INFO: Loading: pos 2020-04-15 07:44:06 INFO: Loading: lemma 2020-04-15 07:44:06 INFO: Loading: depparse 2020-04-15 07:44:08 INFO: Loading: ner 2020-04-15 07:44:09 INFO: Done loading processors! |
我将Stanza的中英文模块部署在了AINLP的后台,使用的就是CPU,感兴趣的同学可以关注AINLP公众号,对话测试,Stanza+分析内容触发,会自动判断语言选择不同的Pipeline: