
上一节我们介绍了一些背景知识以及gensim , 相信很多同学已经尝试过了。这一节将从gensim最基本的安装讲起,然后举一个非常简单的例子用以说明如何使用gensim,下一节再介绍其在课程图谱上的应用。
二、gensim的安装和使用
1、安装
gensim依赖NumPy和SciPy这两大Python科学计算工具包,一种简单的安装方法是pip install,但是国内因为网络的缘故常常失败。所以我是下载了gensim的源代码包安装的。gensim的这个官方安装页面很详细的列举了兼容的Python和NumPy, SciPy的版本号以及安装步骤,感兴趣的同学可以直接参考。下面我仅仅说明在Ubuntu和Mac OS下的安装:
1)我的VPS是64位的Ubuntu 12.04,所以安装numpy和scipy比较简单"sudo apt-get install python-numpy python-scipy", 之后解压gensim的安装包,直接“sudo python setup.py install"即可;
2)我的本是macbook pro,在mac os上安装numpy和scipy的源码包废了一下周折,特别是后者,一直提示fortran相关的东西没有,google了一下,发现很多人在mac上安装scipy的时候都遇到了这个问题,最后通过homebrew安装了gfortran才搞定:“brew install gfortran”,之后仍然是“sudo python setpy.py install" numpy 和 scipy即可;
2、使用
gensim的官方tutorial非常详细,英文ok的同学可以直接参考。以下我会按自己的理解举一个例子说明如何使用gensim,这个例子不同于gensim官方的例子,可以作为一个补充。上一节提到了一个文档:Latent Semantic Indexing (LSI) A Fast Track Tutorial , 这个例子的来源就是这个文档所举的3个一句话doc。首先让我们在命令行中打开python,做一些准备工作:
>>> from gensim import corpora, models, similarities
>>> import logging
>>> logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
然后将上面那个文档中的例子作为文档输入,在Python中用document list表示:
>>> documents = ["Shipment of gold damaged in a fire",
... "Delivery of silver arrived in a silver truck",
... "Shipment of gold arrived in a truck"]
正常情况下,需要对英文文本做一些预处理工作,譬如去停用词,对文本进行tokenize,stemming以及过滤掉低频的词,但是为了说明问题,也是为了和这篇"LSI Fast Track Tutorial"保持一致,以下的预处理仅仅是将英文单词小写化:
>>> texts = [[word for word in document.lower().split()] for document in documents]
>>> print texts
[['shipment', 'of', 'gold', 'damaged', 'in', 'a', 'fire'], ['delivery', 'of', 'silver', 'arrived', 'in', 'a', 'silver', 'truck'], ['shipment', 'of', 'gold', 'arrived', 'in', 'a', 'truck']]
我们可以通过这些文档抽取一个“词袋(bag-of-words)",将文档的token映射为id:
>>> dictionary = corpora.Dictionary(texts)
>>> print dictionary
Dictionary(11 unique tokens)
>>> print dictionary.token2id
{'a': 0, 'damaged': 1, 'gold': 3, 'fire': 2, 'of': 5, 'delivery': 8, 'arrived': 7, 'shipment': 6, 'in': 4, 'truck': 10, 'silver': 9}
然后就可以将用字符串表示的文档转换为用id表示的文档向量:
>>> corpus = [dictionary.doc2bow(text) for text in texts]
>>> print corpus
[[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1)], [(0, 1), (4, 1), (5, 1), (7, 1), (8, 1), (9, 2), (10, 1)], [(0, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (10, 1)]]
例如(9,2)这个元素代表第二篇文档中id为9的单词“silver”出现了2次。
有了这些信息,我们就可以基于这些“训练文档”计算一个TF-IDF“模型”:
>>> tfidf = models.TfidfModel(corpus)
2013-05-27 18:58:15,831 : INFO : collecting document frequencies
2013-05-27 18:58:15,881 : INFO : PROGRESS: processing document #0
2013-05-27 18:58:15,881 : INFO : calculating IDF weights for 3 documents and 11 features (21 matrix non-zeros)
基于这个TF-IDF模型,我们可以将上述用词频表示文档向量表示为一个用tf-idf值表示的文档向量:
>>> corpus_tfidf = tfidf[corpus]
>>> for doc in corpus_tfidf:
... print doc
...
[(1, 0.6633689723434505), (2, 0.6633689723434505), (3, 0.2448297500958463), (6, 0.2448297500958463)]
[(7, 0.16073253746956623), (8, 0.4355066251613605), (9, 0.871013250322721), (10, 0.16073253746956623)]
[(3, 0.5), (6, 0.5), (7, 0.5), (10, 0.5)]
发现一些token貌似丢失了,我们打印一下tfidf模型中的信息:
>>> print tfidf.dfs
{0: 3, 1: 1, 2: 1, 3: 2, 4: 3, 5: 3, 6: 2, 7: 2, 8: 1, 9: 1, 10: 2}
>>> print tfidf.idfs
{0: 0.0, 1: 1.5849625007211563, 2: 1.5849625007211563, 3: 0.5849625007211562, 4: 0.0, 5: 0.0, 6: 0.5849625007211562, 7: 0.5849625007211562, 8: 1.5849625007211563, 9: 1.5849625007211563, 10: 0.5849625007211562}
我们发现由于包含id为0, 4, 5这3个单词的文档数(df)为3,而文档总数也为3,所以idf被计算为0了,看来gensim没有对分子加1,做一个平滑。不过我们同时也发现这3个单词分别为a, in, of这样的介词,完全可以在预处理时作为停用词干掉,这也从另一个方面说明TF-IDF的有效性。
有了tf-idf值表示的文档向量,我们就可以训练一个LSI模型,和Latent Semantic Indexing (LSI) A Fast Track Tutorial中的例子相似,我们设置topic数为2:
>>> lsi = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
>>> lsi.print_topics(2)
2013-05-27 19:15:26,467 : INFO : topic #0(1.137): 0.438*"gold" + 0.438*"shipment" + 0.366*"truck" + 0.366*"arrived" + 0.345*"damaged" + 0.345*"fire" + 0.297*"silver" + 0.149*"delivery" + 0.000*"in" + 0.000*"a"
2013-05-27 19:15:26,468 : INFO : topic #1(1.000): 0.728*"silver" + 0.364*"delivery" + -0.364*"fire" + -0.364*"damaged" + 0.134*"truck" + 0.134*"arrived" + -0.134*"shipment" + -0.134*"gold" + -0.000*"a" + -0.000*"in"
lsi的物理意义不太好解释,不过最核心的意义是将训练文档向量组成的矩阵SVD分解,并做了一个秩为2的近似SVD分解,可以参考那篇英文tutorail。有了这个lsi模型,我们就可以将文档映射到一个二维的topic空间中:
>>> corpus_lsi = lsi[corpus_tfidf]
>>> for doc in corpus_lsi:
... print doc
...
[(0, 0.67211468809878649), (1, -0.54880682119355917)]
[(0, 0.44124825208697727), (1, 0.83594920480339041)]
[(0, 0.80401378963792647)]
可以看出,文档1,3和topic1更相关,文档2和topic2更相关;
我们也可以顺手跑一个LDA模型:
>>> lda = models.LdaModel(copurs_tfidf, id2word=dictionary, num_topics=2)
>>> lda.print_topics(2)
2013-05-27 19:44:40,026 : INFO : topic #0: 0.119*silver + 0.107*shipment + 0.104*truck + 0.103*gold + 0.102*fire + 0.101*arrived + 0.097*damaged + 0.085*delivery + 0.061*of + 0.061*in
2013-05-27 19:44:40,026 : INFO : topic #1: 0.110*gold + 0.109*silver + 0.105*shipment + 0.105*damaged + 0.101*arrived + 0.101*fire + 0.098*truck + 0.090*delivery + 0.061*of + 0.061*in
lda模型中的每个主题单词都有概率意义,其加和为1,值越大权重越大,物理意义比较明确,不过反过来再看这三篇文档训练的2个主题的LDA模型太平均了,没有说服力。
好了,我们回到LSI模型,有了LSI模型,我们如何来计算文档直接的相思度,或者换个角度,给定一个查询Query,如何找到最相关的文档?当然首先是建索引了:
>>> index = similarities.MatrixSimilarity(lsi[corpus])
2013-05-27 19:50:30,282 : INFO : scanning corpus to determine the number of features
2013-05-27 19:50:30,282 : INFO : creating matrix for 3 documents and 2 features
还是以这篇英文tutorial中的查询Query为例:gold silver truck。首先将其向量化:
>>> query = "gold silver truck"
>>> query_bow = dictionary.doc2bow(query.lower().split())
>>> print query_bow
[(3, 1), (9, 1), (10, 1)]
再用之前训练好的LSI模型将其映射到二维的topic空间:
>>> query_lsi = lsi[query_bow]
>>> print query_lsi
[(0, 1.1012835748628467), (1, 0.72812283398049593)]
最后就是计算其和index中doc的余弦相似度了:
>>> sims = index[query_lsi]
>>> print list(enumerate(sims))
[(0, 0.40757114), (1, 0.93163693), (2, 0.83416492)]
当然,我们也可以按相似度进行排序:
>>> sort_sims = sorted(enumerate(sims), key=lambda item: -item[1])
>>> print sort_sims
[(1, 0.93163693), (2, 0.83416492), (0, 0.40757114)]
可以看出,这个查询的结果是doc2 > doc3 > doc1,和fast tutorial是一致的,虽然数值上有一些差别:
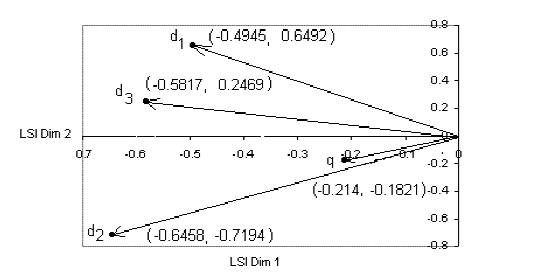
好了,这个例子就到此为止,下一节我们将主要说明如何基于gensim计算课程图谱上课程之间的主题相似度,同时考虑一些改进方法,包括借助英文的自然语言处理工具包NLTK以及用更大的维基百科的语料来看看效果。
未完待续...
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/如何计算两个文档的相似度二
居然有这么详细的python自然语言处理工具包,用起来好爽呀。
[回复]
请教一下,为什么建立index的时候是
index = similarities.MatrixSimilarity(lsi[corpus])
而不是
index = similarities.MatrixSimilarity(lsi[corpus_tfidf])
呢?
[回复]
52nlp 回复:
19 6 月, 2013 at 15:41
这个问题没怎么思考过,不过可以认为lsi model中已经含了tfidf的信息,具体可以看看代码中是如何操作的。
[回复]
maomao 回复:
20 6 月, 2014 at 15:15
因为对新的文档无法计算idf吧应该是,
[回复]
董国盛 回复:
26 3 月, 2015 at 10:44
参考了官方Tutorial发现,模型构建和建索引并计算相似度是分为两部分来讲的。
Topic Model构建部分,教程中使用的是tfidf corpus来构造lsi model;
建索引和相似度查询的部分,教程中直接使用了corpus,也就是bow vector来构造lsi model,所以使用lsi model的时候,才直接使用原始corpus,而不是tfidf corpus。
所以在本教程中是不是应该改成
index = similarities.MatrixSimilarity(lsi[corpus_tfidf])
query_lsi = lsi[tfidf[query_bow]]
[回复]
lyf 回复:
19 8 月, 2015 at 21:02
我的python在执行到query_lsi = lsi[query_bow]这里会崩溃,求救
您好,我在win7上装上了gensim,按照您的例子输入语句:
from gensim import corpora, models, similarities的时候报错:
Traceback (most recent call last):
File "", line 1, in
from gensim import corpora, models, similarities
ImportError: No module named gensim
请问这是什么原因导致的呢?我之前没有接触过python.
[回复]
52nlp 回复:
21 6 月, 2013 at 07:42
这是显示的是gensim美元安装成功:ImportError: No module named gensim
[回复]
陈亮 回复:
21 6 月, 2013 at 07:54
谢谢您的回复,是不是说这个导入错误信息不影响使用呢?另外“gensim美元”是什么意思?我问这些可能是些很菜的问题,见笑了。
[回复]
陈亮 回复:
21 6 月, 2013 at 07:59
额,应该是您把“没有”打成美元了,多谢你的回答。
[回复]
corpus_lsi = lsi[corpus_tfidf]
>>> for doc in corpus_lsi:
… print doc
以上这段程序和上下文没有任何关联,去掉感觉阅读全文更加流畅。
通过用lda求相似
lda = models.LdaModel(corpus_tfidf, id2word=dictionary, num_topics=2)
lda.print_topics(2)
for doc in lda[corpus]:
print doc
query_lda = lda[query_bow]
index = similarities.MatrixSimilarity(lda[corpus])
sims = index[query_lda]
print list(enumerate(sims)) #[(0, 0.37399071), (1, 0.9899627), (2, 0.9950707)]
##可以看出来用lsi 和lda模型 运算出来的结果是一致的
[回复]
我其实不是很明白LSI模型 设置topic2
>>> corpus_lsi = lsi[corpus_tfidf]
>>> for doc in corpus_lsi:
… print doc
…
[(0, 0.67211468809878649), (1, -0.54880682119355917)]
[(0, 0.44124825208697727), (1, 0.83594920480339041)]
[(0, 0.80401378963792647)]
可以看出,文档1,3和topic1更相关,文档2和topic2更相关;
这一段不是很了解
[回复]
liu 回复:
9 10 月, 2016 at 16:27
同问
[回复]
请教博主,gensim中tfidf的具体计算公式是啥?按照正常的思路:词频tf(w,d) = count(w, d) / size(d) (count(w, d)为词w在文档d中出现次数,size(d)为文档d中总词数),逆文档频率idf = log(n / docs(w, D)) (n为文档总数,docs(w,D)词w所出现文档数)。貌似gensim算出来的结果和这个公式不合。
另外文档的相似度是根据余弦相似度吗?比如后面那个博文里面,如果以tfidf作为文档的特征向量,文档的相似度是否应该以余弦公式来算?同理引入lda模型,此刻的特征向量应该是文档属于各topic的概率向量,相似度也以余弦公式来算吗?
[回复]
52nlp 回复:
24 10 月, 2014 at 14:15
抱歉,gensim的tf-idf具体计算公式建议你自己看一下代码;相似度是根据余弦相似度计算的。
[回复]
我其实不是很明白LSI模型 设置topic2
>>> corpus_lsi = lsi[corpus_tfidf]
>>> for doc in corpus_lsi:
… print doc
…
[(0, 0.67211468809878649), (1, -0.54880682119355917)]
[(0, 0.44124825208697727), (1, 0.83594920480339041)]
[(0, 0.80401378963792647)]
可以看出,文档1,3和topic1更相关,文档2和topic2更相关;
博主,能解释下文档1,3为什么跟topic1相关,文档2跟topic2相关?
[回复]
52nlp 回复:
24 3 月, 2015 at 14:37
这个怎么解释呢?就是余弦相似度而已
[回复]
博主您好,向您请教一个问题:
① dictionary = corpora.Dictionary(texts)
② corpus = [dictionary.doc2bow(text) for text in texts]
我在用上述两个步骤的时候发现一个问题:
用14w条文本,①耗费的计算时间是6分钟,②耗费的计算时间是26分钟。
而在看gensim代码过程中我发现,在生成Dictionary这个类的时候,是在__init__函数里调用self.add_documents(documents)函数,在add_documents函数里就是通过对每篇文本计算doc2bow(text) 来更新dictionary,很奇怪的是运行时间却比我的②这一步少很多,百思不得其解,盼望回复~
[回复]
博主,你好
能否请教一下,lsi适不适合用在query经常为一个单词的情况下?或者博主有没有什么推荐的用在query经常为一个单词的情况下。
[回复]
52nlp 回复:
27 4 月, 2015 at 22:27
query为一个单词的话你可以试试近期比较火热的word2vec;
另外以前遇到此类情况,我们会将query丢给搜索引擎,然后取top-N的搜索结果来组长一个文档,然后再用topic model.
[回复]
楼主你好,我有个问题想请教一下
你在这一步:
lsi = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
训练LSI模型的时候用的是tfidf向量表示文本
但是在计算query相似度的时候:
query_bow = dictionary.doc2bow(query.lower().split())
query_lsi = lsi[query_bow]
又直接使用了词袋向量表示文本,这是不是有错误?
我看官网上应该是有两种训练方法,一种是tfidf表示文本然后训练LSI模型,一种是直接用词袋向量表示文本训练模型。
[回复]
52nlp 回复:
18 5 月, 2015 at 11:18
soryy, 时间有点长,有点忘了,印象query_bow只是id表示一下,并不影响推理,你可以自己试试。
[回复]
jianghu 回复:
25 5 月, 2015 at 19:54
我也是在win7上装的。
Numpy: numpy-MKL-1.8.0.win-amd64-py2.7
scipy: scipy_0.14.0.win_amd64_py2.7
gensim: gensim-0.11.1-1.tar
安装过程没问题,但from gensim import models时出现如下问题:
DLL load failed,找不到指定的模块.
请教。
[回复]
我也是在win7上装的。
Numpy: numpy-MKL-1.8.0.win-amd64-py2.7
scipy: scipy_0.14.0.win_amd64_py2.7
gensim: gensim-0.11.1-1.tar
安装过程没问题,但from gensim import models时出现如下问题:
DLL load failed,找不到指定的模块.
请教。
[回复]
52nlp 回复:
25 5 月, 2015 at 22:14
抱歉,win下的安装不太清楚,需要你自行google
[回复]
内存:4G
加载500M数据的时候,出现内存不足,
请问楼主是怎么解决加载大文本的问题的?
[回复]
52nlp 回复:
11 6 月, 2015 at 18:20
我的mac是16G内存的
[回复]
我的python在执行到query_lsi = lsi[query_bow]这里会崩溃,求救
[回复]
52nlp 回复:
20 8 月, 2015 at 08:19
具体报错信息是什么?崩溃这个词没有什么信息量
[回复]
lyf 回复:
20 8 月, 2015 at 22:27
不知道为什么
如果直接访问query_lsi【0】,这样就会崩溃
但是如果用for来遍历就不会,这是为什么呢
[回复]
想问问楼主,就是为什么主题切分是2个呢?
有时候文档会很多很多,如何确定最优的topic个数呢?
[回复]
52nlp 回复:
23 3 月, 2016 at 11:03
这只是个例子吧,另外确定最优topic的个数可能需要你更多实验了
[回复]
博主您好,我想请教下训练好之后想得到 主题-词 分布之后如何转换成词-文档分布?因为我想用这个特征去做词语的表示。我用英文wiki语料,去除停词后的平均句长3580.比如将1W篇文章分为100个主题,得到了每一个主题的词分布,但是当我需要转换为词的主题分布的时候,调用的是lda.get_term_topics(word,minimum_probability=0.0)
然后源码有一句minimum_probability = max(minimum_probability, 1e-8)
但是我无论怎么设置,哪怕主题数只有3都是很小的3个数字,
[(0, 0.00020780514726886015), (1, 7.1061797219949862e-05), (2, 0.00013262868335584357)]
但是用博主你的那三句话结果是
word damaged has topics [(0, 0.07518266881121316), (1, 0.023448489488055283), (2, 0.0092945843729267084)]
word gold has topics [(0, 0.079410806183473903), (1, 0.026511499571314628), (2, 0.13723715078927687)]
word fire has topics [(0, 0.077049817596793482), (1, 0.021261744162525544), (2, 0.0084894800062794377)]
word delivery has topics [(0, 0.07717087133383782), (1, 0.021744898976618968), (2, 0.0081913504955464945)]
word arrived has topics [(0, 0.077944930839941071), (1, 0.028781475132377787), (2, 0.13819001300870382)]
word shipment has topics [(0, 0.076738603311799422), (1, 0.026165422947636914), (2, 0.14222985102631228)]
word truck has topics [(0, 0.080320514364299156), (1, 0.028149183963371238), (2, 0.13444114163728532)]
word silver has topics [(0, 0.16495955576627075), (1, 0.023541118283613077), (2, 0.0092045861801407797)]
是不是因为我词语词典太大的原因?因为我看tf_idf值也都很小,但是我最终是得到每个词语的一个类似word2vec的等维特征表示,又不能选取前top的关键词,这样就丢失了很多词。
希望能够得到解答,万分感谢!
[回复]
52nlp 回复:
5 12 月, 2016 at 15:24
抱歉,这个不是太清楚
[回复]
您好,冒昧的问下博主,在计算lsi模型中,计算query和corpus的相似度的时候需要将query映射到2维空间中,但是将语聊映射到2维空间的时候用的是语料的tfidf表示,为什么将query映射到2维空间的时候,只是用query的tf表示,而不是tfidf的表示?
corpus_lsi = lsi[corpus_tfidf]
query_lsi = lsi[query_bow]
[回复]
52nlp 回复:
20 12 月, 2016 at 15:44
这个问题上面有同学讨论过,我又review了一下gensim的官方tutorial,它确实是按照这个方式给得。另外就是这个同学给得一个改写方式可以参考一下,可以试试效果。
董国盛 回复:
三月 26th, 2015 at 10:44
参考了官方Tutorial发现,模型构建和建索引并计算相似度是分为两部分来讲的。
Topic Model构建部分,教程中使用的是tfidf corpus来构造lsi model;
建索引和相似度查询的部分,教程中直接使用了corpus,也就是bow vector来构造lsi model,所以使用lsi model的时候,才直接使用原始corpus,而不是tfidf corpus。
所以在本教程中是不是应该改成
index = similarities.MatrixSimilarity(lsi[corpus_tfidf])
query_lsi = lsi[tfidf[query_bow]]
[回复]
楼主,现在毕业设计正在做lda提取主题信息,我打算用gensim做,刚开始有很多疑问希望能请教您,我初步试了试,gensim最后能得到topic0 ,topic1...这样的分布,但我已经有了一些主题词,我应该怎样把训练得到的主题映射到我需要得到的主题上啊?
[回复]
52nlp 回复:
21 5 月, 2017 at 18:51
topic里包含的是词的概率分布信息,你自己试着匹配一下。
[回复]
请问下 最后的那张图是怎么 画出来的 上面的坐标值取至哪里
[回复]