
飞桨框架3.0发布了,有很多新特性,包括但不限于:
1)动静统一自动并行:通过少量的张量切分标记,即可自动完成分布式切分信息的推导,Llama预训练场景减少80%的分布式相关代码开发。
2)大模型训推一体:依托高扩展性的中间表示(PIR)从模型压缩、推理计算、服务部署、多硬件推理全方位深度优化,支持文心4.5、文心X1等多款主流大模型,DeepSeek-R1满血版单机部署吞吐提升一倍。
3)科学计算高阶微分:通过高阶自动微分和神经网络编译器技术,微分方程求解速度比PyTorch快115%。
4)神经网络编译器:通过自动算子自动融合技术,无需手写CUDA等底层代码,部分算子执行速度提升4倍,模型端到端训练速度提升27.4%。
5)异构多芯适配:通过对硬件接入模块进行抽象,降低异构芯片与框架适配的复杂度,兼容硬件差异,初次跑通所需适配接口数比PyTorch减少56%,代码量减少80%。

不过最吸引我的还是大模型训推一体,特别是推理端针对在DeepSeek V3/R1的优化:
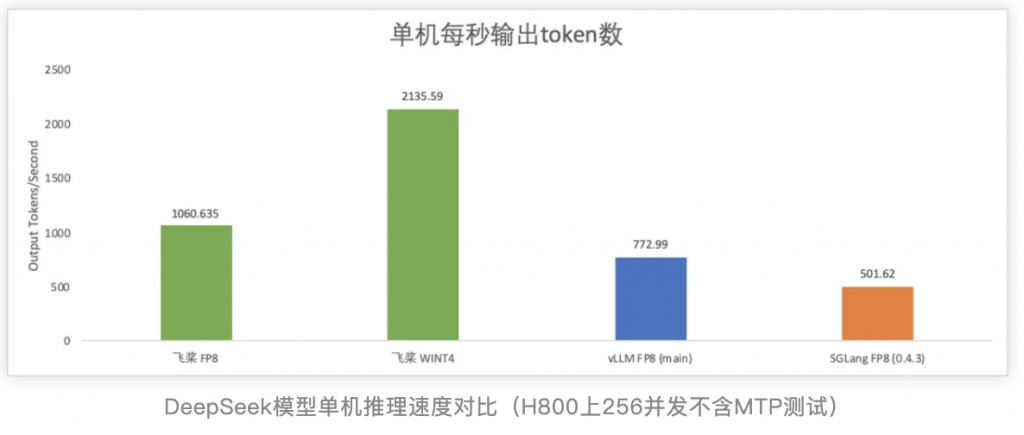
大模型的推理部署需要更好地平衡成本、性能和效果,飞桨框架3.0全面升级了大模型推理能力,依托高扩展性的中间表示(PIR)从模型压缩、推理计算、服务部署、多硬件推理全方位深度优化,能够支持众多开源大模型进行高性能推理,并在DeepSeek V3/R1上取得了突出的性能表现。飞桨框架3.0支持了DeepSeek V3/R1满血版及其系列蒸馏版模型的FP8推理,并且提供INT8量化功能,破除了Hopper架构的限制。此外,还引入了4比特量化推理,使得用户可以单机部署,降低成本的同时显著提升系统吞吐一倍,提供了更为高效、经济的部署方案。在性能优化方面,针对MLA算子进行多级流水线编排、精细的寄存器及共享内存分配优化,性能相比FlashMLA最高可提升23%。综合FP8矩阵计算调优及动态量化算子优化等基于飞桨框架3.0的DeepSeek R1 FP8推理,单机每秒输出token数超1000;若采用4比特单机部署方案,每秒输出token数可达2000以上,推理性能显著领先其他开源方案。此外,还支持了MTP投机解码,突破大批次推理加速,在解码速度保持不变的情况下,吞吐提升144%;吞吐接近的情况下,解码速度提升42%。针对长序列Prefill阶段,通过注意力计算动态量化,首token推理速度提升37%。
话不多说,直接尝试飞桨框架3.0下的DeepSeek的部署,手上刚好有1张24G的3090卡可以测试,之前通过ollama部署过 deepseek-r1-32b 的4bit量化版,看了一下飞桨上关于deepseek部署的说明文档:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/predict/deepseek.md
预制的静态图如下:
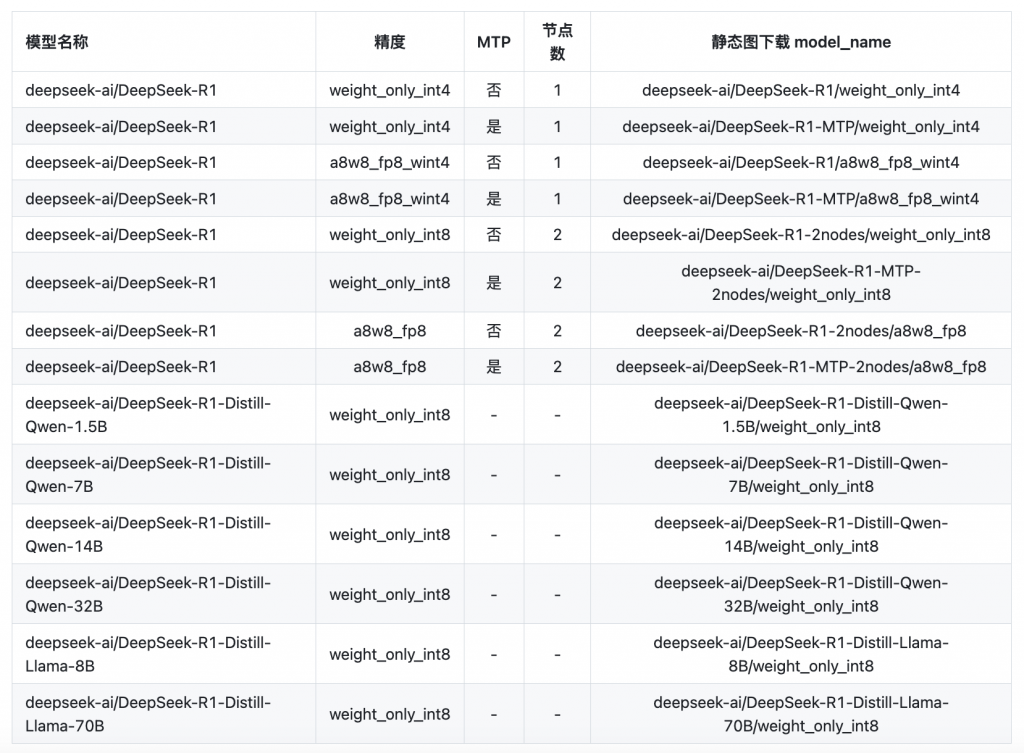
我这张卡大概可以部署一个蒸馏版的14B int8版本的模型:DeepSeek-R1-Distill-Qwen-14B/weight_only_int8。按着官方文档的说明开始部署,不过部署之前,首先需要安装Docker和NVIDIA Container Toolkit,我这台机器之前已经安装了,这一步直接跳过,如果没有安装的同学可以自行搜索相关文档进行安装。另外就是提前下载好模型文件,官方文档提供的是静态图快速一键部署命令,包括自动下载模型和启动推理服务,不过我第一次操作感觉模型貌似没有被下载下来或者模型下载很慢没有成功:
export MODEL_PATH=${MODEL_PATH:-$PWD}
export model_name=${model_name:-"deepseek-ai/DeepSeek-R1-Distill-Qwen-14B/weight_only_int8"}
docker run --gpus all --shm-size 32G --network=host --privileged --cap-add=SYS_PTRACE \
-v /MODEL_PATH/:/models -e "model_name=${model_name}"\
-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.3 /bin/bash \
-c -ex 'start_server $model_name && tail -f /dev/null'不过飞桨官方同时提供了自动下载的脚本,支持下载后再启动服务进行推理。进入容器后根据单机或多机模型进行静态图下载。MODEL_PATH 为指定模型下载的存储路径,可自行指定 model_name 为指定下载模型名称。下载脚本为脚本为 download_model.py ,镜像内路径是:脚本所在路径/opt/output/download_model.py ,可以等待相关镜像启动后进入容器内下载。而github上的路径如下:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/server/server/server/download_model.py
我直接下载了这个脚本,提前下载好模型文件,速度很快,这是我的下载命令:
python download_model.py --model_name $model_name --dir $MODEL_PATH --nnodes 1下载的deepseek蒸馏版14B int8版本模型有16G,很快就下载好了:
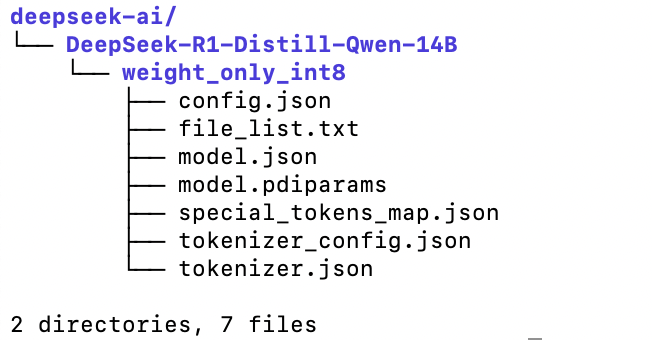
模型下载好之后,可以运行之前那个一键启动命令了,我稍微修改了一下:
docker run --gpus '"device=0" --shm-size 24G --network=host --privileged --cap-add=SYS_PTRACE -v /MODEL_PATH/:/models -e "model_name=${model_name}" -dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.3 /bin/bash -c -ex 'start_server $model_name && tail -f /dev/null'稍等一会儿,运行一下nvidia-smi,就可以看到大致的显存占用情况了:
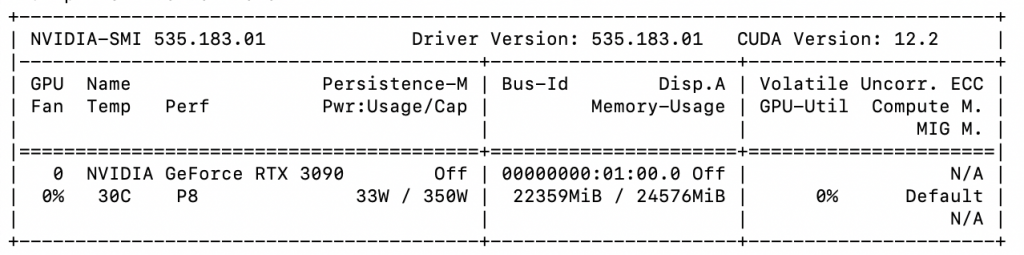
本地测试一下:
curl 127.0.0.1:9965/v1/chat/completions \
-H'Content-Type: application/json' \
-d'{"text": "你好,你是谁"}'如果得到的返回结果类似下面的,那么这次部署就成功了:
{"result":"您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。","error_msg":"","error_code":0}这里think部分不太明显,我又测了一下那个经典的问题:9.8和9.11谁大
curl 127.0.0.1:9965/v1/chat/completions -H'Content-Type: application/json' -d'{"text": "9.8 和 9.11谁大"}'{"result":"首先,我需要比较9.8和9.11的大小。\n\n为了方便比较,我可以将9.8写成9.80,这样它们的小数位数相同。\n\n接下来,我比较它们的整数部分,发现都是9,相等。\n\n然后,我比较小数部分,0.80大于0.11。\n\n因此,9.80大于9.11。\n\n最终,9.8大于9.11。\n</think>\n\n要比较 \ 和 \
和 \ 的大小,可以按照以下步骤进行:\n\n1. **统一小数位数**:\n \n 将 \ 写成 \
的大小,可以按照以下步骤进行:\n\n1. **统一小数位数**:\n \n 将 \ 写成 \ ,以便与 \ 进行相同位数的比较。\n\n2. **比较整数部分**:\n \n 两个数的整数部分都是 \
,以便与 \ 进行相同位数的比较。\n\n2. **比较整数部分**:\n \n 两个数的整数部分都是 \ ,相等。\n\n3. **比较小数部分**:\n \n 比较小数部分:\n \\[\n 0.80 \\quad \\text{和} \\quad 0.11\n \
,相等。\n\n3. **比较小数部分**:\n \n 比较小数部分:\n \\[\n 0.80 \\quad \\text{和} \\quad 0.11\n \ 0.80 > 0.11\
0.80 > 0.11\ 9.80 > 9.11\
9.80 > 9.11\ 9.8 > 9.11\
9.8 > 9.11\ ","error_msg":"","error_code":0}
","error_msg":"","error_code":0}基本没有问题,飞桨同时也提供了兼容openai请求接口规范的样例,感兴趣的朋友可以自己测试:
import openai
client = openai.Client(base_url=f"http://127.0.0.1:9965/v1/chat/completions", api_key="EMPTY_API_KEY")
# 非流式返回
response = client.completions.create(
model="default",
prompt="Hello, how are you?",
max_tokens=50,
stream=False,
)
print(response)
print("\n")
# 流式返回
response = client.completions.create(
model="default",
prompt="Hello, how are you?",
max_tokens=100,
stream=True,
)
for chunk in response:
if chunk.choices[0] is not None:
print(chunk.choices[0].text, end='')
print("\n")我这边的部署测试基本结束了,限于卡的资源有限,仅能测试Deepseek蒸馏版本,有卡有资源的朋友可以尝试飞桨框架3.0提供的DeepSeek 满血版部署方案,特别是DeepSeek-R1-MTP版本,毕竟推理速度和吞吐性能都提升惊人:
综合FP8矩阵计算调优及动态量化算子优化等基于飞桨框架3.0的DeepSeek R1 FP8推理,单机每秒输出token数超1000;若采用4比特单机部署方案,每秒输出token数可达2000以上,推理性能显著领先其他开源方案。此外,还支持了MTP投机解码,突破大批次推理加速,在解码速度保持不变的情况下,吞吐提升144%;吞吐接近的情况下,解码速度提升42%。针对长序列Prefill阶段,通过注意力计算动态量化,首token推理速度提升37%。