
深度学习相关技术近年来在工程界可谓是风生水起,在自然语言处理、图像和视频识别等领域得到极其广泛的应用,并且在效果上更是碾压传统的机器学习。一方面相对传统的机器学习,深度学习使用更多的数据可以进行更好的扩展,并且具有非常优异的自动提取抽象特征的能力。
另外得益于GPU、SSD存储、大容量RAM以及大数据分布式计算平台等的快速发展,海量数据的处理能力大幅度提升。同时,“千人千面”的个性化推荐系统已经融入到我们的日常生活的方方面面,并且给企业带来了巨大的收益。智能推荐系统本质上是对原始的用户行为数据进行深入地分析和挖掘,得到用户的兴趣偏好,进行精准推荐。所以,将深度学习和推荐系统相结合也成为了工业界的研究热点,Google、Facebook、Netflix等公司很早就开始研究基于深度学习的推荐系统,并且取得了显著的效果提升。(达观数据 于敬)
一、RBM介绍
1 RBM和Netflix
提到基于RBM的推荐系统,不得不提Netflix竞赛。2006年,Netflix公司为了提升推荐效果,悬赏百万美元组织了一场竞赛,让大家穷尽所能以使其推荐算法的效果能够提升10%以上。在竞赛的后半程,RBM异军突起。当时以SVD++为核心的各种模型几乎已经陷入了僵局,很多人在此基础上加了pLSA、LDA、神经元网络算法、马尔可夫链、决策树等等,但效果提升并不明显,各个参赛队伍基本上进入到了比拼trick与融合模型数据的体力活阶段了。
但是,RBM的出现,把整个竞赛推进到了一个新的台阶。最终在2009年,“鸡尾酒”团队将上百个模型进行融合以10.05%的结果获得了此次竞赛的终极大奖。但是Netflix后来的线上系统并没有采用如此复杂的全套算法,而是仅仅应用了最核心的两个算法,其中就有受限玻尔兹曼机,另外一个就是耳熟能详的奇异值分解。
2 RBM的层次结构
RBM是一种可用随机神经网络来解释的概率图模型,主要用于协同过滤、降维、分类、回归、特征学习和主题建模。RBM包括两层,第一个层称为可见层,第二个层称为隐藏层。
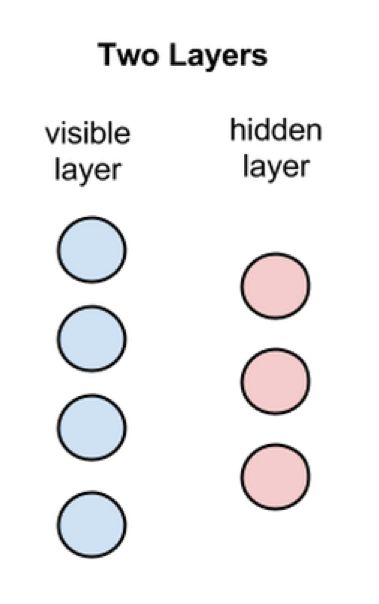
如图1所示,每个圆圈称为节点,代表一个与神经元相似的单元,而运算就在这些节点中进行。每一个神经元是一个二值单元,也就是每一个神经元的取值只能等于0或1。节点之间的连接具有如下特点:层内无连接,层间全连接。
RBM和BM的不同之处就在于:BM允许层内节点连接,而RBM不允许。这就是受限玻尔兹曼机中受限二字的本意。每一个节点对输入数据进行处理,同时随机地决定是否继续传输输入数据,这里的“随机”是指改变输入数据的系数是随机初始化的。每个可见层的节点表示有待学习数据集合中一个物品的一个低层次特征。
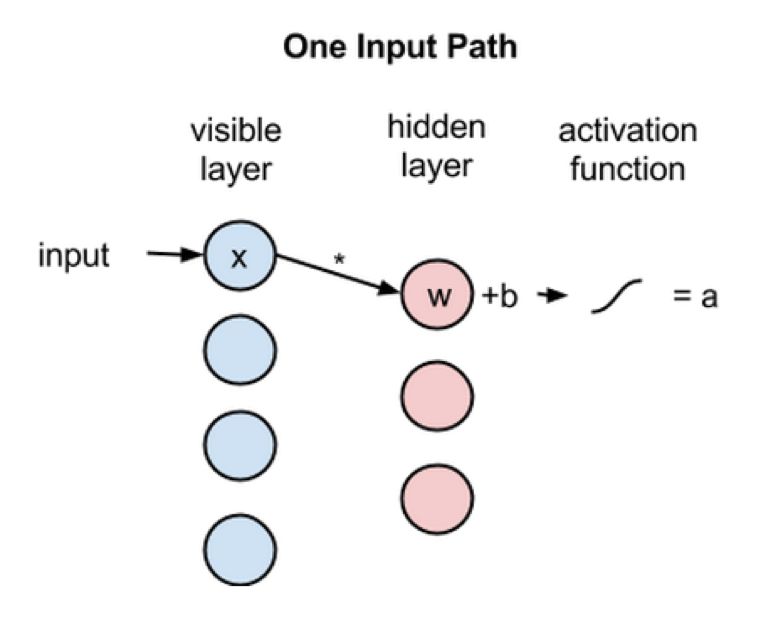
接下来看一下单个输入x是如何通过这个两层网络的,如图2所示。在隐藏层的节点中,x和一个权重w相乘,再和所谓的偏差b相加。这两步的结果输入到一个激活函数中,进而得到节点的输出,也就是对于给定输入x,最终通过节点后的信号强度。如果用公式表示的话,即:
![]()
sigmoid函数是神经网络中常用的激活函数之一,其定义为:
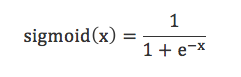
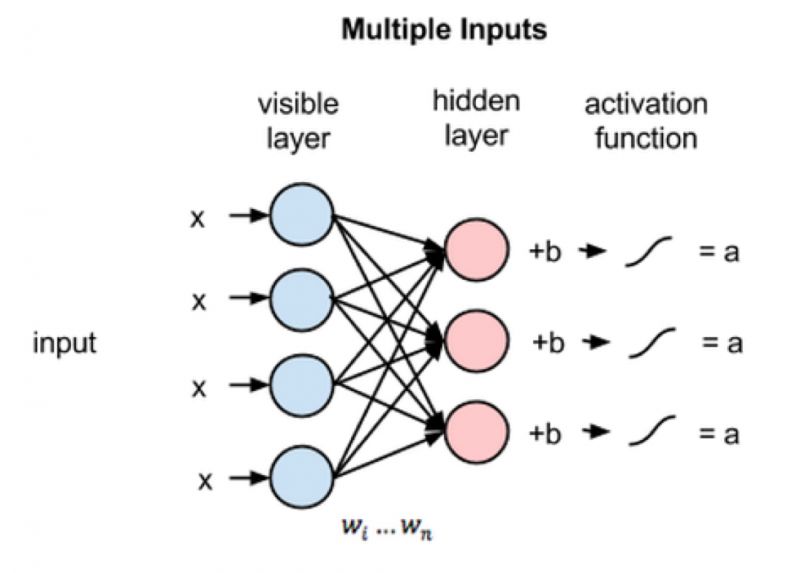
接下来看看多项输入节点是如何整合到隐藏节点中的,如图4所示。每个输入x分别与各自的权重w相乘,再将结果求和后与偏差b想加,得到结果后输入到激活函数中,最后得到节点的输出值a。
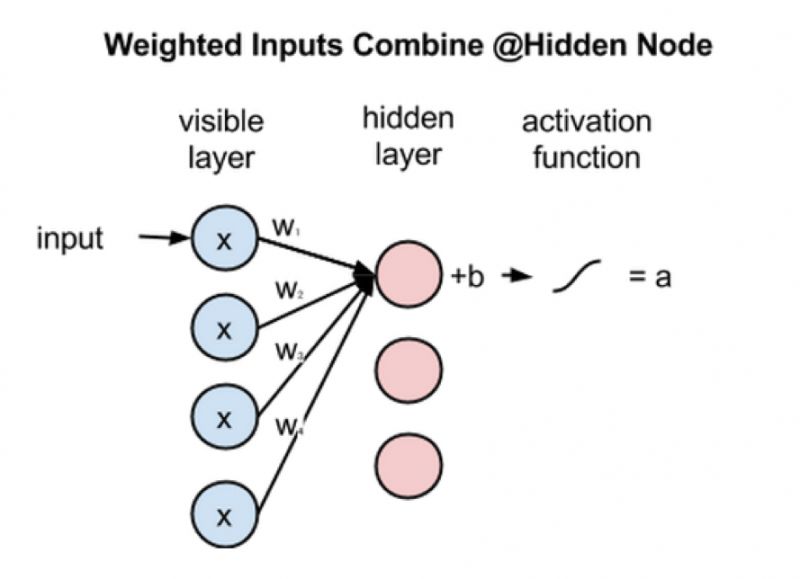
由于可见层的所有节点的输入都会被传送到隐藏层中的每个节点,所以RBM可以被定义成一种对称二分图。如图5所示,当多个输入通过多个隐藏节点时,在隐藏层的每个节点中,都会有 x和权重w相乘,有4个输入,而每个输入x会有三个权重,最终就有12个权重,从而可以形成一个行数等于输入节点数、列数等于输出节点数的权重矩阵。隐藏层的每个节点接收4个可见层的输入与各自权重相乘后的输入值,乘积之和与偏差值b相加,再经过激活运算后得到隐藏层每个节点的输出a。
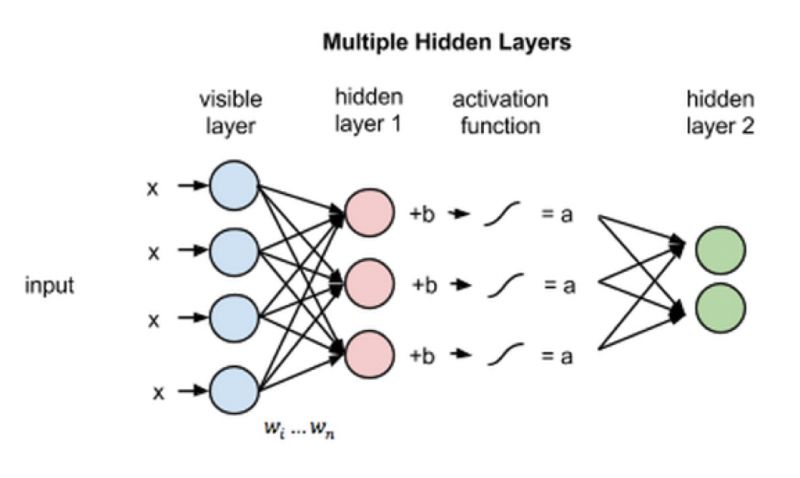
再进一步,如果是想构建一个二层的深度神经网络,如6所示,将第一隐藏层的输出作为第二隐藏层的输入,然后再通过不定数量的隐藏层,最终就可以到达分类层。(达观数据 于敬)
3 RBM的重构
这里介绍下RBM在无监督情况下如何重构数据的,其实就是在可见层和第一隐藏层之间多次进行正向和反向传递,但并不涉及更深的网络结构。在重构阶段,第一隐藏层的激活值作为反向传递的输入。这些输入值和相应的权重相乘,然后对这些乘积求和后再与偏差相加,得到的结果就是重构值,也就是原始输入x的近似值。
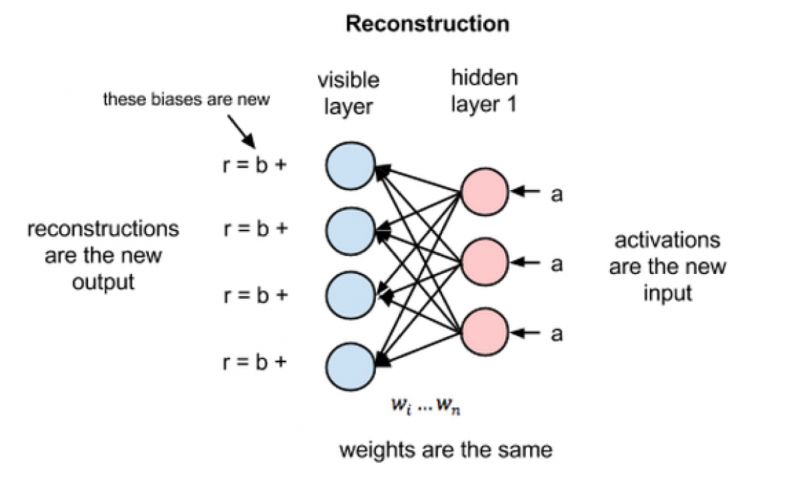
由于RBM的初始权重是随机初始化的,所以重构值与原始输入之间的差别往往很大。r值与输入值之差定义为重构误差,经由反向传递来不断修正RBM的权重,经过不断迭代,可以使得重构误差达到最小。
RBM在正向传递过程中根据输入值来计算节点的激活值,也就是对输入x进行加权后得到输出为a的概率p(a|x;w)。 而在反向传递时,激活值则变成输入,输出值变成了原始数据的重构值,也就是RBM在估计激活值为a时而输入值为x的概率p(x|a;w),激活值的权重w和正向传递中的一样。最终两个过程相结合,得到输入 为x 和激活值为 a 的联合概率分布p(x, a)。
重构不同于平时所说的回归、分类。重构是在预测原始输入数据的概率分布,同时预测许多不同点的值,这就是生成学习。RBM用KL(Kullback Leibler)散度来衡量预测的概率分布与基准分布之间的距离。
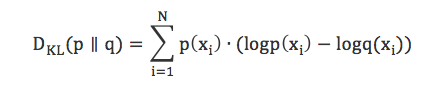
KL散度衡量的是两条曲线下方不重叠区域的面积,RBM的优化算法就是要最小化这个面积,从而使得权重在与第一隐藏层的激活值相乘后,可以得到与原始输入尽可能近似的结果。如图7所示,左半边是一组原始输入的概率分布曲线p,另外一个是重构值的概率分布曲线q,右半边的图则显示了两条曲线之间的差异。
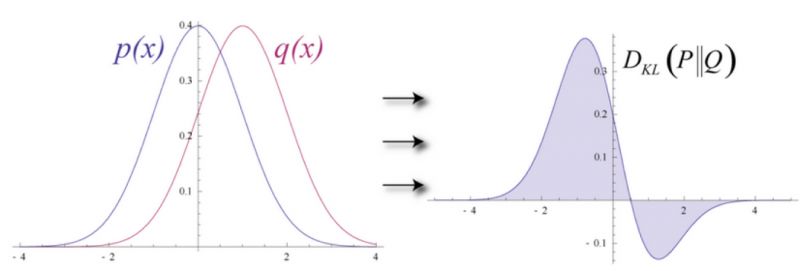
在整个重构过程中,RBM会根据重构误差反复的迭代计算,以尽可能准确地学习出原始值,最终看上去两条概率分布曲线会尽可能地逼近,如图8所示。
利用RBM的堆叠可以构造出深层的神经网络模型——深度置信网络(Deep Belief Net, DBN),感兴趣的话可以查阅相关资料深入了解。在处理无监督学习问题时,使用一定的数据集合来训练网络,设置下可见层节点的值匹配下数据集合中的值。然后使用训练好的网络,对未知数据进行计算就可以进行分类。(达观数据 于敬)
二、RBM的数学原理
在RBM中,有如下性质:当给定可见层节点的状态时,隐藏层各节点之间是否激活是条件独立的;反之当给定隐藏层节点的状态时,可见层各节点之间是否激活也是条件成立的。
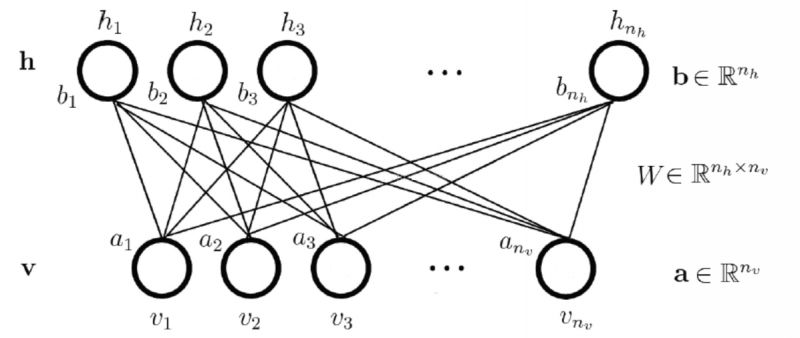
图10是一个RBM的网络结构示意图,其中:
![]() :分别表示可见层和隐藏层的神经元数量;
:分别表示可见层和隐藏层的神经元数量;
![]() :可见层的状态向量,
:可见层的状态向量,![]() 表示可见层中第
表示可见层中第个神经元的状态;
![]() :可见层的状态向量,
:可见层的状态向量,![]() 表示隐藏层中第
表示隐藏层中第个神经元的状态;
![]() :可见层的偏置向量,
:可见层的偏置向量,![]() 表示可见层中第
表示可见层中第个神经元的偏置;
![]() 隐藏层的偏置向量,
隐藏层的偏置向量,![]() 表示隐藏层中第个神经元的偏置;
表示隐藏层中第个神经元的偏置;
![]() :隐藏层和可见层之间的权重矩阵,
:隐藏层和可见层之间的权重矩阵,![]() 表示隐藏层中第
表示隐藏层中第个神经元与可见层中第
个神经元之间的连接权重
对于RBM,其参数主要是可见层和隐藏层之间的权重、可见层的偏置和隐藏层的偏置,记为![]() ,可将其看作是W、a、b中所有分量拼接起来的到的长向量。
,可将其看作是W、a、b中所有分量拼接起来的到的长向量。
RBM是一个基于能量的模型,对于给定的状态(v, h),可以定义能量函数
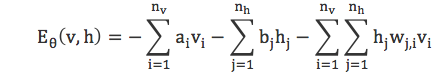
进而可以的到(v, h)的联合概率分布
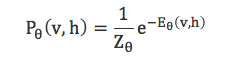
其中

为归一化因子
于是,可以定义边缘概率分布
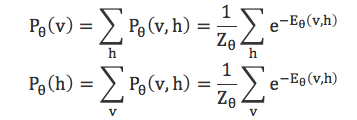
结合联合概率分布、边缘概率分布和sigmoid函数,可以得到:
在给定可见层状态时,隐藏层上某个神经元被激活的概率
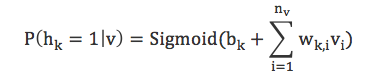
给定隐藏层状态时,可见层上某个神经元被激活的概率

给定训练样本后,训练RBM也就是调整参数![]() ,使得RBM表示的概率分布尽可能与训练数据保持一致。
,使得RBM表示的概率分布尽可能与训练数据保持一致。
给定训练集:
![]()
![]() 是训练样本的数量,
是训练样本的数量,![]() ,则训练RBM的目标就是最大化似然函数:
,则训练RBM的目标就是最大化似然函数:
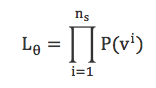
进一步取log函数:

使用梯度上升法进行上述最优化问题的求解,梯度上升法的形式是:
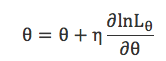
![]() 为学习率,最终可以得到:
为学习率,最终可以得到:

Hinton给出了高效寻来呢RBM的算法——对比散度(Contrastive Divergence,简称CD)算法。
对![]() ,取初始值:
,取初始值:![]() ,然后执行k步Gibbs抽样,其中第t步先后执行:
,然后执行k步Gibbs抽样,其中第t步先后执行:
- 利用
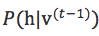 采样出
采样出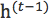
- 利用
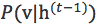 采样出
采样出
最后,关于RBM的评估方法,由于本身算法的限制,一般采用近似方法进行评估,重构误差就是其中之一。重构误差以训练样本作为初始状态,经过RBM的分布进行一次Gibbs转移后与原数据的差异量。重构误差在一定程度上反映了RBM对训练样本的似然度,虽然不完全可靠,但计算简单,在实践中非常有用。(达观数据 于敬)
本质上来说,RBM是一个编码解码器:将原始输入数据从可见层映射到隐藏层,并且得到原始输入数据的隐含因子,对应的是编码过程;然后利用得到的隐藏层向量在映射回可见层,得到新的可见层数据,对应的是解码过程。而优化目标是希望让解码后的数据和原始输入数据尽可能的接近。在推荐场景中,可以获取到用户对物品的评分矩阵,进过RBM的编码-解码过程处理后,不仅得到了已有评分对应的新评分,同时对未评分的物品进行预测,并将预测分数从高到低排序就可以生成推荐列表。换句话说,就是将RBM应用到协同过滤中。
但是这个推荐过程需要解决两个问题:
1)RBM中的节点都是二元变量, 如果用这些二元变量来对用户评分进行建模?
2)实际业务场景中,用户只会对很少的物品评分,用户评分行为矩阵都是非常稀疏的,那么如何处理这些缺失的评分?
Ruslan Salakhutdinov等人首次提出了使用RBM求解Netflix竞赛中的协同过滤问题。对传统的RBM进行改进:可见层使用Softmax神经元;用户只对部分物品评分,而对于没有评分的物品使用一种特殊的神经元表示,这种神经元不与任何隐藏层神经元连接。具体结构如图11所示。
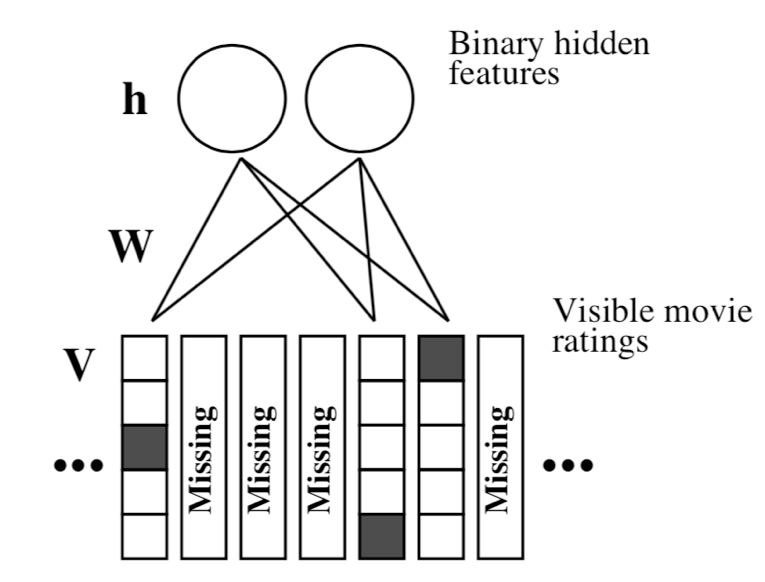
从图11中可以看到,Softmax神经元是一个长度为K的向量(图中K为5),并且这个向量每次只有一个分量为1,而且第i个单元为1仅当用户对该物品打分为i是才会置为1,其余为0。从而可以得到可见层单元和隐藏层单元被激活的概率:
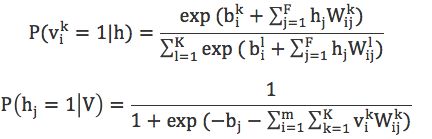
使用前面提到的CD算法,各个参数的学习过程如下:
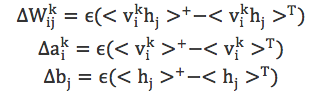
RBM经过学习以后,可以得到整个网络的全部参数。给定一个用户u和一个物品i,预测评分R(u, i)过程如下:
1) 将用户u的所有评分作为RBM的softmax单元的输入
2) 对于所有的隐藏单元j计算激活概率![]()
3)对于所有的k=1,2,…,K, 计算
4)取期望值作为预测结果,比如![]()
以上RBM只用到用户对物品的评分,忽略了很重要的信息:用户浏览过哪些物品,但是并没有评的情况。条件RBM (Conditional Restricted Boltzmann Machine)对这种信息可以进行建模。
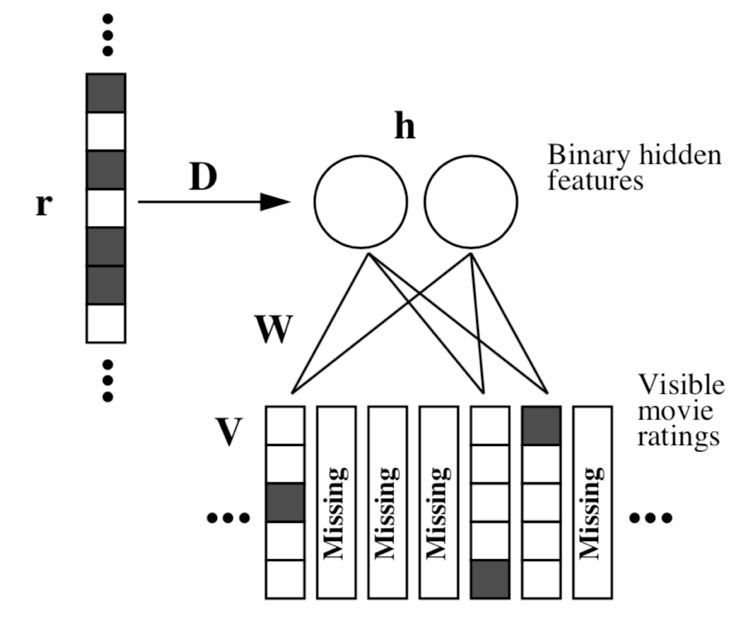
其中r是m维的向量,![]() 为1的话,表示用户对浏览过第i个电影,加入r之后的条件概率:
为1的话,表示用户对浏览过第i个电影,加入r之后的条件概率:
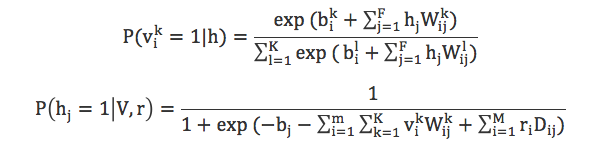
权重D的学习过程:
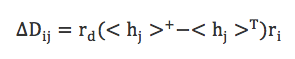
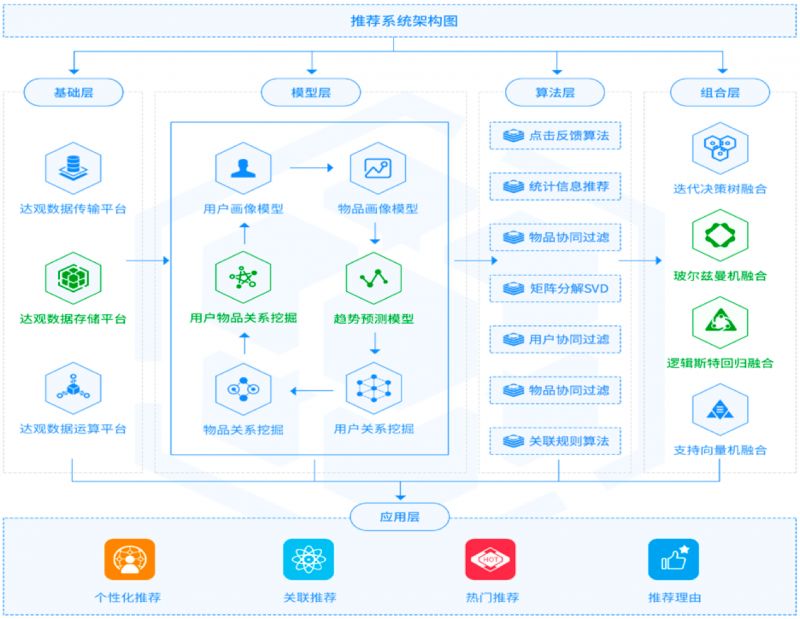
经过前面的分析,对RBM的内部算法原理、编码和解码过程以及在推荐中的应用等有了基本的了解。在推荐业务场景中,一般有两种使用方式:
其实深度学习的很多模型都可以应用于推荐系统,方式也非常多。达观数据精于技术,对于推荐系统和深度学习相结合以持续优化推荐效果的探索也从未停止,后续也会不断地分享相关成果,敬请期待。
关于作者
于敬:达观数据联合创始人,中国计算机学会(CCF)会员,第23届ACM CIKM Competition竞赛国际冠军,达观数据个性化推荐组总负责人,负责达观数据智能推荐系统的架构设计和开发、推荐效果优化等。同济大学计算机应用技术专业硕士,曾先后在盛大创新院、盛大文学和腾讯文学数据中心从事用户行为建模、个性化推荐、大数据处理、数据挖掘和机器学习相关工作,对智能推荐、机器学习、大数据技术和分布式系统有较深入的理解和多年实践经验。
http://credit-n.ru/zaymyi-next.html