
中文语法纠错任务旨在对文本中存在的拼写、语法等错误进行自动检测和纠正,是自然语言处理领域一项重要的任务。同时该任务在公文、新闻和教育等领域都有着落地的应用价值。但由于中文具有的文法和句法规则比较复杂,基于深度学习的中文文本纠错在实际落地的场景中仍然具有推理速度慢、纠错准确率低和假阳性高等缺点,因此中文文本纠错任务还具有非常大的研究空间。
达观数据在CCL2022汉语学习者文本纠错评测比赛的赛道一中文拼写检查(Chinese Spelling Check)任务中取得了冠军,赛道二中文语法纠错(Chinese Grammatical Error Diagnosis)任务中获得了亚军。本文基于赛道二中文语法纠错任务的内容,对比赛过程中采用的一些方法进行分享,并介绍比赛采用的技术方案在达观智能校对系统中的应用和落地。赛道一中文拼写检查的冠军方案会在后续的文章分享。
本次中文语法纠错任务是对给定的句子输出可能包含的错误位置、错误类型和修正答案,而最终的评测指标是假阳性、侦测层、识别层、定位层和修正层这五个维度指标的综合结果。而且本次评测任务使用的数据是汉语学习者的写作内容,与母语写作者相比汉语学习者的数据本身就具有句子流畅度欠佳、错误复杂度较高等情况。因此,本次评测的难度在于对于汉语学习者的书写内容既要保证检错和纠错的准确率和召回率,还要保证正确句子不能进行修改操作以降低模型的假阳性。本文主要从数据和模型两方面来分享本次比赛中采用的模型和策略。
数据分析
本次评测中,官方提供了CGED的历年比赛数据(41,239条)和Lang8数据(1212,457条)供模型训练,同时提供了3767条评测数据用以验证模型的效果和性能。为了解数据的错误分布以及数据的质量,我们首先对评测数据进行了分析。CGED-21验证集中的错误分布情况如图1所示,由此可以看出数据集中占绝大多数的均为用词错误,其次为缺失错误,而乱序错误的占比最少。
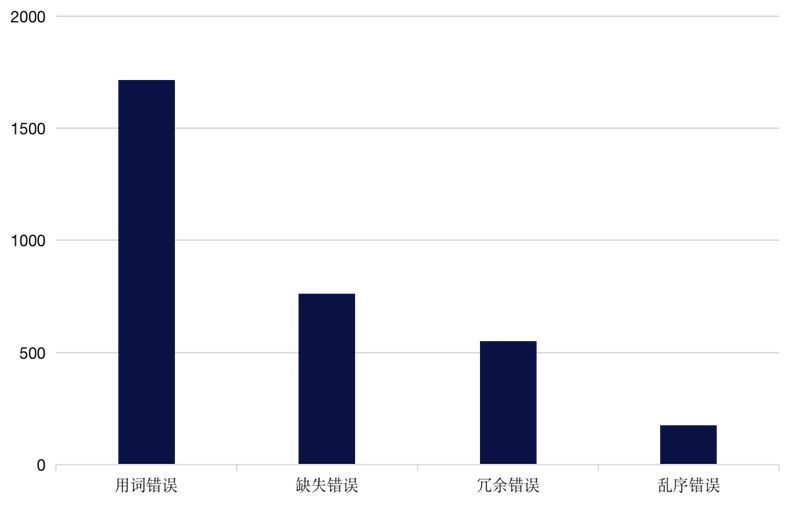 图1 验证集错误占比统计图
图1 验证集错误占比统计图
同时在数据测验的过程中还发现了CGED和Lang8数据集中存在的一些数据问题。
具体问题如下所示:
- 源句子与目标句子完全不相关;
- 目标句子是对源句子的批注;
- 源句子中存在错误编辑距离较大的情况;
- 数据集中末尾处存在多字的缺失错误
对此,我们也摘录了数据集中存在的一些问题的样例数据;由样例数据可知,不管采用哪种模型,数据中包含的这些错误均会导致模型产生一些错误的特征映射,从而影响模型的性能。因此在构建语法纠错模型之前首先需要对数据进行清洗,去除质量较差的句子。在本次比赛中,数据预处理是利用编辑距离、字数差异和纠正字数等多个维度的评估来实现的。

表1 数据中的错误样例数据
纠错策略
本次评测任务中的语法错误可以分为拼写错误、语法错误和符号错误。其中拼写错误包括形似音近错误,而语法错误则主要包括用词错误、缺失、乱序和冗余。这些错误类型具有差异性和多样性,利用单个模型难以覆盖所有的错误类型;因此,比赛中采用串行的多阶段中文语法纠错方法来解决中文文本中存在的各种错误。
01拼写纠错模型
对于拼写纠错任务,我们是从数据和模型两个维度来进行解决的。数据方面,首先收集了不同来源的混淆集词典并对其进行整合和扩充,然后基于混淆集和微信新闻语料生成了包含不同错误模式的大规模语料来对模型进行训练。模型方面是利用MDCSpell[2]来实现拼写纠错任务。进一步地,我们发现检错和纠错模块可以直接使用BERT输出的语义特征信息,而不需要舍弃CLS和SEP。而且这样还能保证两个模块的输出维度相同更方便特征信息的融合。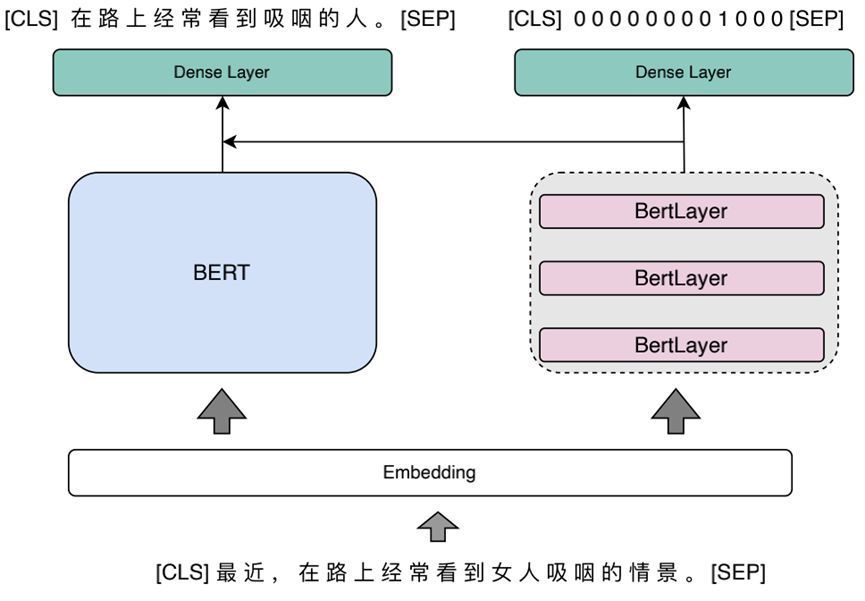 图2 拼写纠错模型结构图
图2 拼写纠错模型结构图
此外,拼写纠错模型的定位是解决数据中存在的形似音近问题,而且整个流程还后接了语法纠错模型,所以拼写纠错模型只需要保证纠错的准确率高而误召回低。因此在推理阶段,拼写纠错模型还利用阈值对模型的输出进行判别以确定是否接受当前的纠错结果。
02语法纠错模型
拼写纠错模型只能解决数据中存在的形似音近错误,因此我们基于序列到编辑的Seq2Edit模型来完成剩余的错误类型的纠正。Seq2Edit是目前最优的语法纠错模型,它通过预训练模型获得输入句子的语义特征编码,然后通过全连接层预测句子中对应的每个句子的编辑标签,该模型对应的解码空间为插入、删除、替换、保持和移动五种编辑操作。而且该模型还通过多任务的方式引入了检错模块,以便利用检错的输出信息增强模型的纠错效果。该语法纠错的模型结构和解码流程如下图所示:
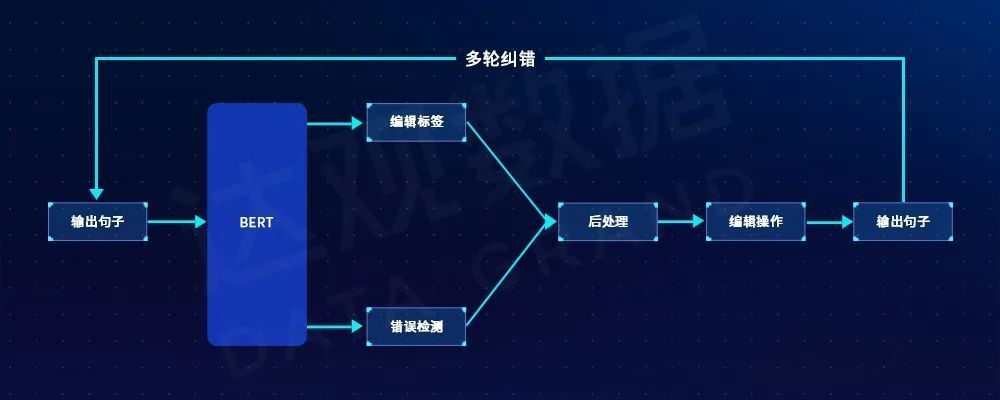
图3 语法纠错流程图
原始Seq2Edit模型是通过删除和插入两种操作来解决句子中的乱序错误,但是由于模型的训练和推理阶段存在暴露偏差,故对于连续字符的缺失错误,模型可能因缺少上下文特征信息即使通过多个轮次也无法进行纠正。例如下表中的乱序错误,当对一侧进行删除操作之后,而缺少了大量的上下文信息故模型无法对另一侧的插入操作进行补齐。而且模型将乱序错误看作冗余和缺失两种错误的集合也会导致模型对删除操作的置信度偏高。但是通过引入移动编辑操作的方法能够较好地解决乱序的问题。

表2 原始Seq2Edit模型对乱序错误的纠错能力
在推理阶段,为了在输出的标签空间中搜索出一条最优的解码路径,我们利用局部路径解码方法对局部的移动编辑操作确定一条和为0的相对路径,并通过自适应阈值的方法对不同编辑操作、不同的词性和词频确定不同的修改接受阈值,由此提高模型的纠正准确率并解决模型的过度纠正等问题。
03模型集成
不同的模型学习到的语义特征信息存在一些差异,因此将多个差异较大而性能略差的模型正确的组合能够极大地提升模型的性能。本次评测中,我们对不同预训练模型训练的纠错模型进行加权集成以提升模型的准确率。此次参与模型集成的有Bert、MacBert和StructBert这3个预训练模型训练的6个Seq2Edit模型。
04数据增强榜单
在实验分析的过程中,我们发现模型对多字词的缺失和句子不同位置的错误的纠错能力不同,并且当前的数据集未能覆盖绝大多数的错误,因此存在OOV的问题。所以我们利用数据生成的策略来解决因OOV导致的模型无法对错误进行纠正的问题。本次比赛中,拼写纠错和语法纠错两个任务都用到了数据增强技术,且均使用微信公众号语料作为种子数据。对于数据增强,我们基于字和词两个维度进行数据扩充,并维护了生僻词表、词频表、键盘布局相邻表、形近混淆集和音近混淆集以保证生成的句子符合中文的语用频率和分布规律。
数据增强的流程如下所述:
(1)数据预处理:对句子进行预处理并掩码掉非中文字符、人名和地名等字符位置;
(2)采样设错位置:确定对句子进行设错操作的字符位置;
(3)采样设错类型:确定当前字符位置的设错类型;
(4)采样设错操作:针对步骤(3)中的设错类型确定设错的操作,一般来说不同的设错类型对应的设错操作也不尽相同,冗余操作的设错操作包括重复当前字词、随机插入和按键盘布局相邻表等方式插入;用词错误的替换策略包括形似混淆集、音似混淆集和随机替换
针对拼写纠错任务形似字错误:音似字错误:词近似错误的比例为0.4:0.4:0.2;而语法纠错的比例是乱序错误:缺失错误:冗余错误:用词错误分别0.05:0.1:0.15:07
05其他策略
- 困惑度策略:困惑度可以用来评估句子的流畅程度,因此比赛中还通过困惑度对多个模型的输出进行评估并选择困惑度最低的纠错句子作为最优解。
- 成语纠错:中文中的成语俗语是约定俗成的,因此我们维护了成语俗语规则表,利用规则匹配到疑似成语错误,并对修改前后的句子进行困惑度计算以确定是否接受对句子错误的修改。
实验结果
在本次比赛的过程中,我们首先对比了基于Seq2Seq的模型和基于Seq2Edit模型的基准模型效果,然后选择了Seq2Edit模型作为本次比赛的基本框架。由该赛道的评测指标可知,本次比赛不仅考察模型的纠错能力,还考察模型正确区分句子对错的能力;因此我们训练了不同性能的多个模型并通过模型集成和困惑度来选择最优结果;不同模型的模型效果对比如下表所示。由表中数据可知,基于Seq2Seq的模型的检错能力较好,但同时模型引入了较高的误召回,从而使得假阳性的指标偏高;而基于Seq2Edit的方法更能够权衡精确率和召回率,使得模型在评测数据上取得更好的结果。同时通过对比可知,利用拼写纠错模型预先纠正用词错误,然后再对其他错误进行纠错,能够提升模型的效果。

表3 不同模型的效果对比
技术落地方案
达观智能校对系统依托于自然语言处理和光学字符识别等技术,实现了不同格式的输入文本的自动校对。该系统涵盖了内容纠错、格式纠错和行文规则纠错等针对不同应用场景下的纠错模块,其中内容纠错模块包括拼写纠错、语法纠错、领导人纠错、符号纠错和敏感词检测等多种校对模块。目前达观智能校对系统已支持公文领域、金融领域和通用领域的文本校对任务,并且可针对不同领域的校对需求为客户提供定制化的解决方案。
达观智能校对系统的如图4所示,其核心模块主要是文档解析和智能纠错。其中智能纠错模块基于预训练模型、序列标注、语言模型和知识蒸馏等技术不断提升中文文本纠错的精度和速度。同时达观智能校对系统也在不断探索新的技术以更好地实现领域迁移和无痛解锁更多的应用场景。

图4 达观智能校对系统
总结展望
对比本次比赛和实际纠错工作中的技术落地点可知中文语法纠错的相关研究距离工程落地还有一定的差距。
工程应用中的一些难点在于:
- 模型复杂度较高,推理速度慢
- 真实的纠错数据较为稀缺,尤其是母语者的错误数据
- 纠错模型容易出现过度纠正的情况,即模型的假阳性偏高
- 现有的模型往往无法覆盖常识、知识型的错误
参考:1. http://cuge.baai.ac.cn/#/ccl_yaclc2. Chenxi Zhu, Ziqiang Ying, Boyu Zhang, and Feng Mao. 2022. MDCSpell: A Multi-task Detector-Corrector Framework for Chinese Spelling Correction. In Findings of the Association for Computational Linguistics: ACL 2022, pages 1244–1253, Dublin, Ireland. Association for Computational Linguistics.