
强烈推荐一个项目:Chinese NLP ,这是由滴滴人工智能实验室所属的自然语言处理团队创建并维护的,该项目非常细致的整理了中文自然语言处理相关任务、数据集及当前最佳结果,相当完备。
Github: https://github.com/didi/ChineseNLP
这个项目里面目前包含了18个中文自然语言处理任务,以及一个其他类别:
每个子任务下面,会详细介绍相关的任务背景、示例、评价指标、相关数据集及当前最佳结果。以中文分词为例,除了我们熟悉的backoff2005数据集外,还有一些其他数据来源:

再看一下机器翻译任务,关于评价指标,描述的相当详细:
直接评估(人工评判)。Amazon Mechnical Turk上的标注人员会看到一个系统生成的翻译和一个人工翻译,然后回答这样一个问题:“系统翻译有多么精确的表达了人工翻译的含义?”
Bleu score (Papineni et al 02 ).
大小写敏感 vs. 大小写不敏感
Brevity penalty 触发条件: 当机器翻译结果短于最短的参考译文 (reference) 或者短于最接近的参考译文 (reference)。
brevity penalty: 一个系数,用来惩罚长度短于参考翻译的机器翻译结果。
标准的Bleu计算流程会先对参考译文和机器翻译结果进行符号化 (tokenizition)。
如果中文是目标 (target) 语言, 则使用字符级别 {1,2,3,4}-gram匹配。
当只有1条人工参考翻译译文时使用Bleu-n4r1评估。
Bleu-n4r4: 词级别 {1,2,3,4}-gram 匹配, 与4条人工参考翻译译文比较
标准Bleu有很多重要的变种:
NIST. Bleu的一种变体,赋予少见的n-gram更高的权重。
TER (Translation Edit Rate). 计算机器翻译与人工参考译文之间的编辑距离 (Edit distance)。
BLEU-SBP ((Chiang et al 08)[http://aclweb.org/anthology/D08-1064] ). 解决了Bleu的解耦(decomposability) 问题,在Bleu和单词错误率取得一个折中。
HTER. 修改为一个良好的翻译所需要的人工编辑次数 (the number of edits)。
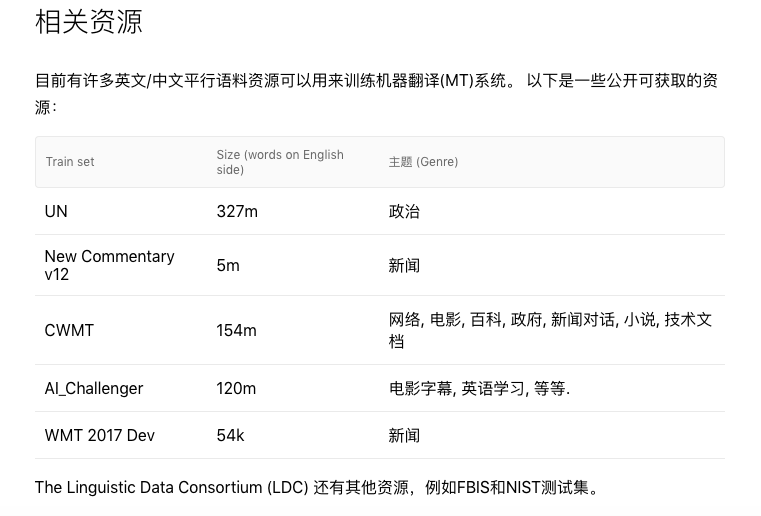
机器翻译相关语料资源方面,也包括我们比较熟悉的联合国语料库和AI Challenger:
其他相关任务感兴趣的同学可以自行参考,这是一个相当不错的了解当前中文NLP相关任务的参考点,感谢建设和维护该项目的同学。
注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:https://www.52nlp.cn
本文链接地址:中文自然语言处理相关的开放任务,数据集, 以及当前最佳结果 https://www.52nlp.cn/?p=12099