自去年以来,在AINLP公众号上陆续给大家提供了自然语言处理相关的基础工具的在线测试接口,使用很简单,关注AINLP公众号,后台对话关键词触发测试,例如输入 “中文分词 我爱自然语言处理”,“词性标注 我爱NLP”,“情感分析 自然语言处理爱我","Stanza 52nlp" 等,具体可参考下述文章:
五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg, THULAC, HanLP
中文分词工具在线PK新增:FoolNLTK、LTP、StanfordCoreNLP
Python中文分词工具大合集:安装、使用和测试
八款中文词性标注工具使用及在线测试
百度深度学习中文词法分析工具LAC试用之旅
来,试试百度的深度学习情感分析工具
AINLP公众号新增SnowNLP情感分析模块
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
既然中文分词、词性标注已经有了,那下一步很自然想到的是命名实体识别(NER,Named-entity recognition)工具了,不过根据我目前了解到的情况,开源的中文命名实体工具并不多,这里主要指的是一些成熟的自然语言处理开源工具,不是github上一些学习性质的代码。目前明确有NER标记的包括斯坦福大学的NLP组的Stanza,百度的Paddle Lac,哈工大的LTP,而其他这些测试过的开源NLP基础工具,需要从词性标注结果中提取相对应的专有名词,也算是一种折中方案。
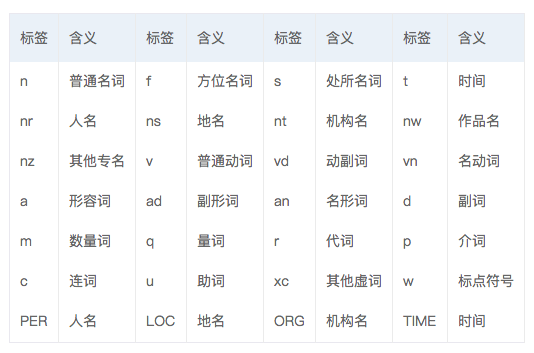
在之前这些可测的工具中,除了斯坦福大学的Stanza和CoreNLP有一套词性标记外,LTP使用的是863词性标注集,其他包括Jieba,SnowNLP,PKUSeg,Thulac,HanLP,FoolNLTK,百度Lac等基础工具的词性标注集主要是以人民日报标注语料中的北京大学词性标注集(40+tags)为蓝本:
| 代码 | 名称 | 帮助记忆的诠释 |
|---|---|---|
| Ag | 形语素 | 形容词性语素。 形容词代码为 a ,语素代码 g 前面置以 A。 |
| a | 形容词 | 取英语形容词 adjective 的第 1 个字母。 |
| ad | 副形词 | 直接作状语的形容词。 形容词代码 a 和副词代码 d 并在一起。 |
| an | 名形词 | 具有名词功能的形容词。 形容词代码 a 和名词代码 n 并在一起。 |
| b | 区别词 | 取汉字“别”的声母。 |
| c | 连词 | 取英语连词 conjunction 的第 1 个字母。 |
| Dg | 副语素 | 副词性语素。 副词代码为 d ,语素代码 g 前面置以 D。 |
| d | 副词 | 取 adverb 的第 2 个字母 ,因其第 1 个字母已用于形容词。 |
| e | 叹词 | 取英语叹词 exclamation 的第 1 个字母。 |
| f | 方位词 | 取汉字“方” 的声母。 |
| g | 语素 | 绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。 由于实际标注时 ,一定 标注其子类 ,所以从来没有用到过 g。 |
| h | 前接成分 | 取英语 head 的第 1 个字母。 |
| i | 成语 | 取英语成语 idiom 的第 1 个字母。 |
| j | 简称略语 | 取汉字“简”的声母。 |
| k | 后接成分 | |
| l | 习用语 | 习用语尚未成为成语 ,有点“临时性”,取“临”的声母。 |
| m | 数词 | 取英语 numeral 的第 3 个字母 ,n ,u 已有他用。 |
| Ng | 名语素 | 名词性语素。 名词代码为 n ,语素代码 g 前面置以 N。 |
| n | 名词 | 取英语名词 noun 的第 1 个字母。 |
| nr | 人名 | 名词代码 n 和“人(ren) ”的声母并在一起。 |
| ns | 地名 | 名词代码 n 和处所词代码 s 并在一起。 |
| nt | 机构团体 | “团”的声母为 t,名词代码 n 和 t 并在一起。 |
| nx | 非汉字串 | |
| nz | 其他专名 | “专”的声母的第 1 个字母为 z,名词代码 n 和 z 并在一起。 |
| o | 拟声词 | 取英语拟声词 onomatopoeia 的第 1 个字母。 |
| p | 介词 | 取英语介词 prepositional 的第 1 个字母。 |
| q | 量词 | 取英语 quantity 的第 1 个字母。 |
| r | 代词 | 取英语代词 pronoun 的第 2 个字母,因 p 已用于介词。 |
| s | 处所词 | 取英语 space 的第 1 个字母。 |
| Tg | 时语素 | 时间词性语素。时间词代码为 t,在语素的代码 g 前面置以 T。 |
| t | 时间词 | 取英语 time 的第 1 个字母。 |
| u | 助词 | 取英语助词 auxiliary 的第 2 个字母,因 a 已用于形容词。 |
| Vg | 动语素 | 动词性语素。动词代码为 v。在语素的代码 g 前面置以 V。 |
| v | 动词 | 取英语动词 verb 的第一个字母。 |
| vd | 副动词 | 直接作状语的动词。动词和副词的代码并在一起。 |
| vn | 名动词 | 指具有名词功能的动词。动词和名词的代码并在一起。 |
| w | 标点符号 | |
| x | 非语素字 | 非语素字只是一个符号,字母 x 通常用于代表未知数、符号。 |
| y | 语气词 | 取汉字“语”的声母。 |
| z | 状态词 | 取汉字“状”的声母的前一个字母。 |
其中HanLp增加了更细粒度的词性标注集,具体可参考:https://www.hankcs.com/nlp/part-of-speech-tagging.html
HanLP使用的HMM词性标注模型训练自2014年人民日报切分语料,随后增加了少量98年人民日报中独有的词语。所以,HanLP词性标注集兼容《ICTPOS3.0汉语词性标记集》,并且兼容《现代汉语语料库加工规范——词语切分与词性标注》。
另外百度词法分析工具Lac使用的词性标注集中特别加了一套强相关的专名类别标签:
词性和专名类别标签集合如下表,其中词性标签24个(小写字母),专名类别标签4个(大写字母)。这里需要说明的是,人名、地名、机名和时间四个类别,在上表中存在两套标签(PER / LOC / ORG / TIME 和 nr / ns / nt / t),被标注为第二套标签的词,是模型判断为低置信度的人名、地名、机构名和时间词。开发者可以基于这两套标签,在四个类别的准确、召回之间做出自己的权衡。
哈工大LTP的命名实体标注集没有提取“时间”,具体参考如下:
https://ltp.readthedocs.io/zh_CN/latest/appendix.html
NE识别模块的标注结果采用O-S-B-I-E标注形式,其含义为
标记 含义 O 这个词不是NE S 这个词单独构成一个NE B 这个词为一个NE的开始 I 这个词为一个NE的中间 E 这个词位一个NE的结尾 LTP中的NE 模块识别三种NE,分别如下:
标记 含义 Nh 人名 Ni 机构名 Ns 地名
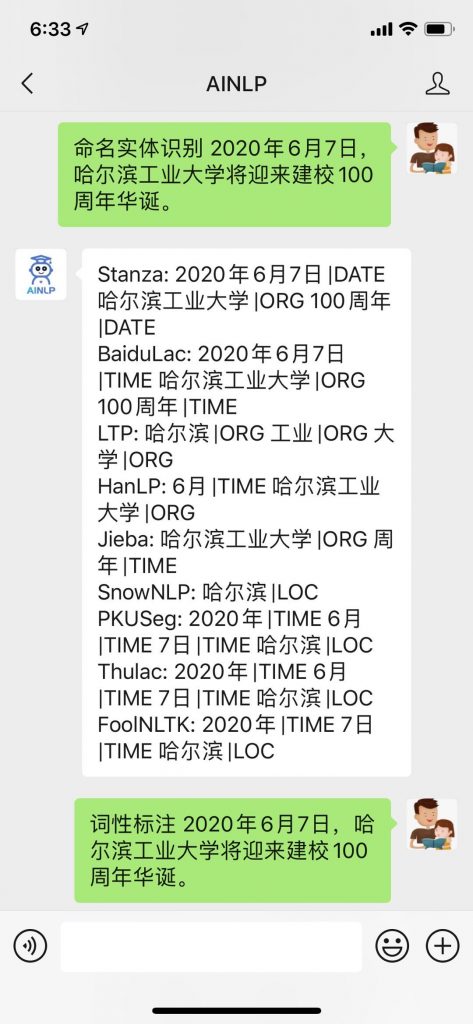
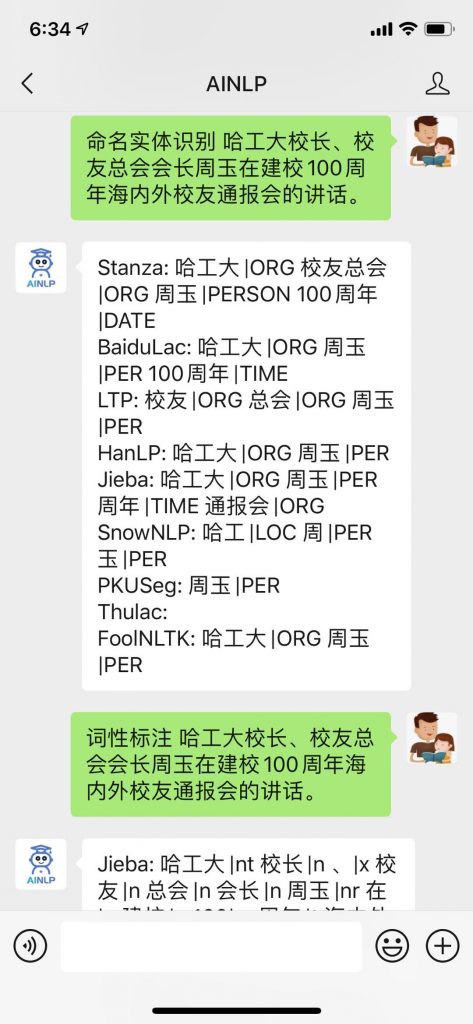
基于上述观察,我决定采用这种方案做中文命名实体工具测试接口:对于斯坦福Stanza的NER结果直接保留,对于 Baidu Lac 结果则保留强置信度的人名(PER)、地名(LOC)、机构名(ORG)、时间(TIME)提取结果,对于哈工大LTP的NER结果做个人名(Nh=>PER)、地名(Ns=>LOC)和机构名(Ni=>ORG)的映射,对于其他几个工具,去除斯坦福的老NLP工具CoreNLP,其他NLP工具则保留nr、ns、nt、t、nz这几个提取工具,并做了标记映射人名(nr=>PER),地名(ns=>LOC),机构名(nt=>ORG),时间(t=>TIME)。下面是几组测试结果,欢迎关注AINLP公众号试用,结果仅供参考,毕竟除了斯坦福Stanza、Baidu Lac以及哈工大LTP外,其他几个工具的“NER命名实体识别”功能是“强加”的,在实际使用中,可以根据需求采用: