

在自然语言处理和知识图谱中,实体抽取、NER是一个基本任务,也是产业化应用NLP 和知识图谱的关键技术之一。BERT是一个大规模预训练模型,它通过精心设计的掩码语言模型(Masked Language Model,MLM)来模拟人类对语言的认知,并对数十亿个词所组成的语料进行预训练而形成强大的基础语义,形成了效果卓绝的模型。通过 BERT来进行实体抽取、NER的方法是当前在NLP和知识图谱的产业化应用中最常用的方法,是效果与成本权衡下的最佳选择。本文详细讲解使用BERT来进行实体抽取,看完本文就会用当前工业界最佳的模型了。
什么是实体抽取?
实体是一个常见的名词,《知识图谱:认知智能理论与实战》一书将其定义为:
实体(Entity):是指一种独立的、拥有清晰特征的、能够区别于其他事物的事物。在信息抽取、自然语言处理和知识图谱等领域,用来描述这些事物的信息即实体。实体可以是抽象的或者具体的。
在实体抽取中,实体也成为命名实体(Named Entity),是指在实体之上会将其分门别类,用实体类型来框定不同的实体。图1是一些常见的“实体”的例子,比如“城市”类型的实体“上海”,“ 公司”类型的实体“达观数据”等。
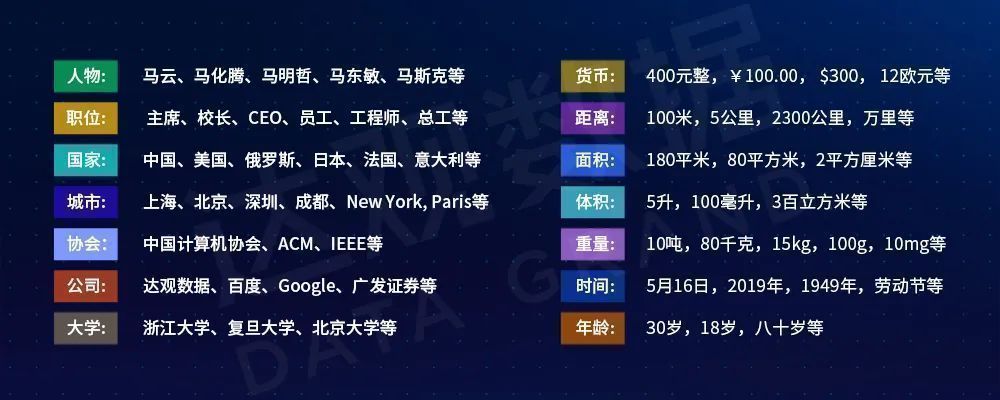
图1 实体示例
实体抽取(Entity Extraction,EE)的目标就是识别一段文本中所包含的实体,在其他语境中,也被称之为“实体识别(Entity Recognition,ER)”、“命名实体识别(Named Entity Recognition,NER)”,这些不同的名词在大多数情况下所指代的意思是一样的。
举例来说,有一段文本:
达观数据与同济大学联合共建的“知识图谱与语义计算联合实验室”正式揭牌成立
识别出其中的蓝色部分,并标记为“机构”类型的实体,就是实体抽取。实体抽取的过程通常可以分为是两个阶段:
- 识别出所有表示实体的词汇
- 将这些词汇分类到不同实体类型中
在传统的命名实体识别任务中,通常有人物、机构、地点等。而在知识图谱中,实体类型可以有数十种,甚至数百种。对于知识图谱来说,将各种文本中的实体抽取出来是最基本的任务,有许多方法都致力于解决这个问题。
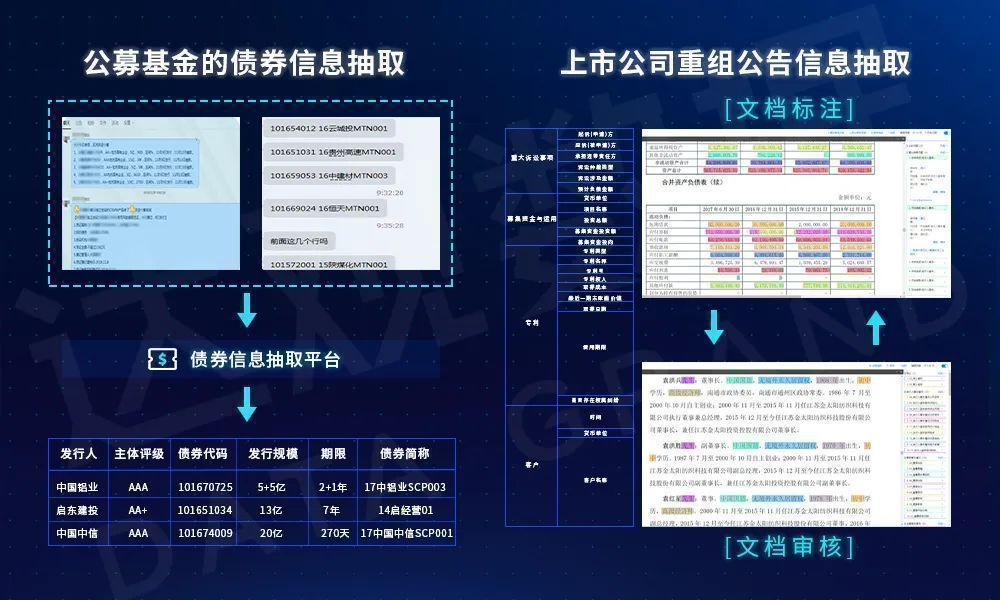 图2 实体抽取案例
图2 实体抽取案例
众所周知,实体抽取的复杂程度十分之高,这不仅仅有上图中的这样复杂的文档的原因,语言本身的理解也存在重重困难,有些场景下即使是人类也会出现不解之处。比如语言中隐含着专业的背景知识,隐形或显性的上下文语境,同样的文本表达着完全不同的概念,而相同的概念又有多变的语言表达方法等等。这些综合的原因使得理解语言成为了人工智能皇冠上的明珠,而从文本中抽取实体则不可避免地要理解语言,实体抽取的效果则依赖于对语言理解的程度。
 图3 语言理解困难重重
图3 语言理解困难重重
历史上,用来进行实体抽取的方法包括基于规则的方法、机器学习方法、深度学习方法和弱监督学习方法等几大类,每类方法中都有很多种不同的算法,具体的算法内容可以参考《知识图谱:认知智能理论与实战》第三章《实体抽取》(P78~136)。
BERT介绍
BERT 是英文“Bidirectional Encoder Representations from Transformers”的缩写,是Google开发的一种基于Transformer的深度学习技术,用于人工智能领域的文本预训练。BERT 由Jacob Devlin和他在 Google 的同事于 2018 年创建,并在论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中发布。在2019 年,谷歌宣布已开始在其搜索引擎中使用 BERT,到 2020 年底,它几乎在搜索查询中都使用了 BERT。在2020 年的一篇论文《"A Primer in BERTology: What We Know About How BERT Works"》中提到“In a little over a year, BERT has become a ubiquitous baseline in NLP experiments and inspired numerous studies analyzing the model and proposing various improvements. The stream of papers seems to be accelerating rather than slowing down, and we hope that this survey helps the community to focus on the biggest unresolved questions.”自从 BERT 出来以后,也引导了至今炙手可热的“大模型”浪潮。其本质就是“预训练”+“微调”:
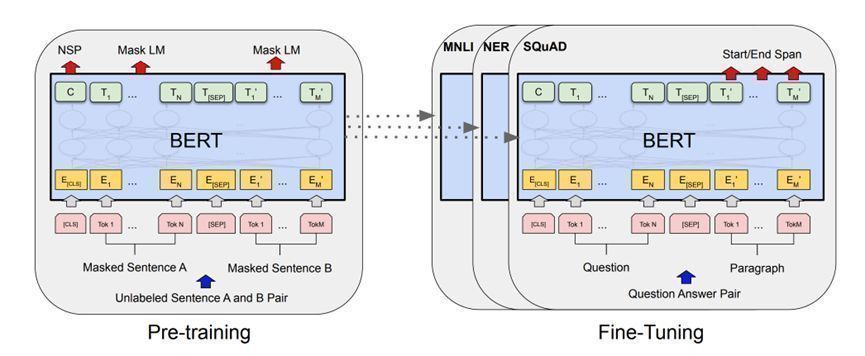
图4 BERT模型,来自参考文献[2]
对于普罗大众来说,人工智能的标志性事件当属AlphaGo,号称人类最难的智力游戏败于机器,可是街头巷尾的谈资。
在自然语言处理领域,BERT在当时的自然语言处理领域可谓掀起轩然大波,总结起来有:
- 在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人成绩,首次两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩。
关于 SQuAD数据集和评测参考https://rajpurkar.github.io/SQuAD-explorer/,当前是2.0版本。 - 谷歌团队成员Thang Luong表示,BERT模型开启了NLP的新时代
- 证明了通过大规模语料集预训练的技术,能够大幅度提升各类文本阅读理解的效果,也因此,“大模型”自此兴起
- Masked LM(见下图)通过学习masked的词,不仅让模型学会了上下文信息,还学会了语法syntax、语义semantics、语用pragmatics等,并能够很好地学会部分领域知识
- 预训练模型越大,效果越好;对应的,成本也会越高。相比于单任务模型来说,无监督的预训练模型成本要大1000倍以上
- 学术界传统上认为,在一些很难处理的文字阅读理解任务上,计算机有望能够全面超越人类

图5 掩码语言模型
掩码语言模型的提出则来自于Google 的更早些的一篇论文《Attention Is All You Need》(下载地址:https://arxiv.org/pdf/1706.03762.pdf) 所提到的 Transformers 模型(见下图)。但 BERT 与 Transformers 略有区别,使用的是其编码器部分,这点从BERT 的论文标题也可以看出来。事实上,当前炙手可热的大模型中(如 GPT-3等),几乎都依赖于 Transformers 的模型结构,特别是其中的自注意力机制。《知识图谱:认知智能理论与实战》一书 P123~130的“BERT 模型详解”一节则对结合代码实现该BERT 的模型结构进行详细的解析,通俗易懂,非常适合阅读来深入理解BERT 模型。上述两篇论文则提供了更多的实验对比素材,深入阅读有助于了解BERT 为何会在当时引起轰动,以至于在NLP领域引领风骚数年。
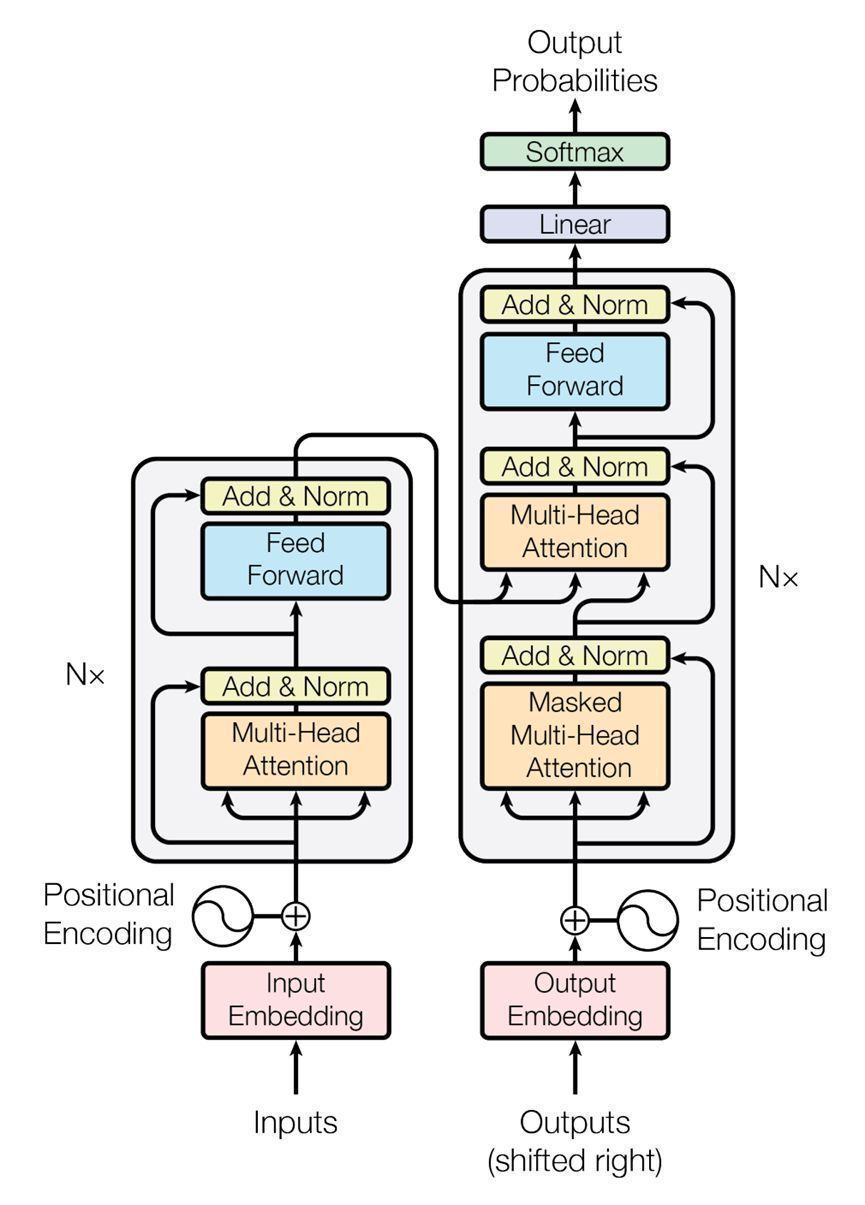 图6 Transformer模型结构
图6 Transformer模型结构
此外值得一提的是,Google最初 发布的 BERT 模型有两种配置:
- BERT BASE:12 个编码器,带有 12 个双向自注意力头;
- BERT LARGE:24 个编码器,带有 16 个双向自注意力头。
这两种配置结构类似,Large版本要比Base版本“更大”,效果自然更好,同时使用时资源要求也更高。本文以Base版本示例,以使得在一张显卡上即可完成。换成 Large 版本不用改变任何代码,但因为网络更大,可能需要更高级的显卡或多卡来支持模型的训练。
语料准备
本文采用“MSRA实体抽取数据集”,并使用BIO标记方法来标记,数据集在GitHub 上有很多,也可以GitHub官网下载。
(https://github.com/wgwang/kgbook/tree/main/datasets/NER-MSRA)
MSRA数据集中,实体类型有三种:
- LOC:地点类型
- ORG:机构类型
- PER:人物类型
一个例子为:
1 O
、 O
中 B-ORG
国 I-ORG
作 I-ORG
协 I-ORG
和 O
现 B-LOC
代 I-LOC
文 I-LOC
学 I-LOC
馆 I-LOC
负 O
责 O
人 O
在 O
巴 B-PER
金 I-PER
家 O
中 O
介 O
绍 O
文 B-LOC
学 I-LOC
馆 I-LOC
新 O
馆 O
设 O
计 O
模 O
型 O
。O
从上述例子可以看出:1.“中国作协”是组织机构(ORG)类型:
- B-ORG标签:因为它是一个机构实体的开始
- I-ORG标签:因为它是一个机构实体的延续
2. “现代文学馆”和“文学馆”是地点(LOC) 类型:
- B-LOC标签:因为它是地点实体的开始
- I-LOC标签:因为它是地点实体的延续
3.“巴金”是任务(PER) 类型:
- B-PER标签:因为它是人物实体的开始
- I-PER 标签:因为它是人物实体的延续
4.其他词被分配O标签:因为它们不是任何实体
使用 BERT 来进行实体抽取的话,需要将语料进行处理,转化成列表的形式(train_data和test_data,对应于原始的train.txt 和test.txt),列表的每一个元素是一个键值对元组,键为文本列表,值为标签列表。如下图所示:
 图7 数据样例
图7 数据样例
用BERT进行实体抽取
这里使用最流行的 PyTorch 框架来实现。首先是引入相关的库。

这里选择的是Google发布的模型bert-base-chinese(https://huggingface.co/models 提供了大量的模型供使用,包括各种专业的预训练模型,比如面向金融领域 FinBERT,面向医药领域的 MedBERT等等):
BERT_NAME = 'bert-base-chinese'
转化为torch能够使用的数据集

再用如下代码将torch 的 dataset转化为按微批提取的 dataloader:

到此,数据准备完成,后面就可以使用数据集来训练模型和测试模型效果了。
构建模型
在本文中,我们将使用来自HuggingFace的预训练 BERT 基础模型。既然我们要在token级别对文本进行分类,那么我们需要使用BertForTokenClassificationclass。
BertForTokenClassificationclass是一个包装 BERT 模型并在 BERT 模型之上添加线性层的模型,将充当token级分类器。基于BertForTokenClassificationclass来创建基于 BERT 的实体抽取模型非常简单,见下面代码:
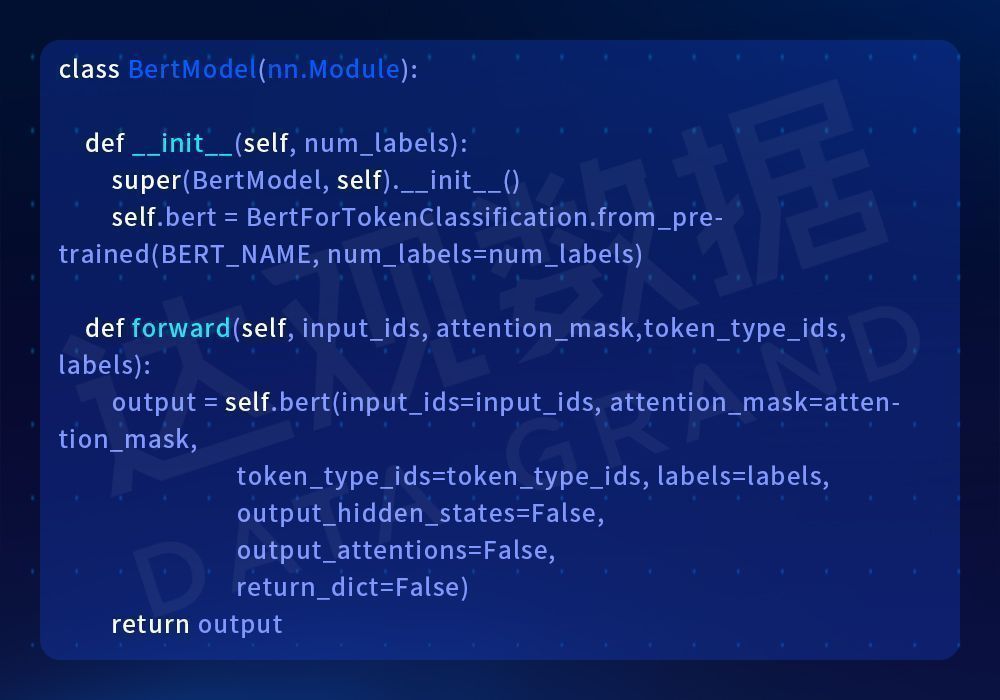
通过如下代码即可实例化一个用BERT进行实体抽取的模型:
model = BertModel(len(label2id)+1)
训练
我们的BERT模型的训练循环是标准的PyTorch训练循环。在训练模型中,需要使用 GPU,否则会非常耗时。GPU建议使用nvidia的显卡提供,1080ti及其更高版本皆可。model = model.cuda()
由于BERT已经使用了大规模语料训练并得到了通用的语义表示,通常使用的话,仅需要重新微调最上面一层即可。为此,需要冻结其他不需要训练的层的参数。下面代码实现了这个逻辑:

接下来就是常见的深度学习训练方法了,这里使用AdamW优化器,其他优化器也可以根据需要进行选择,具体的参考PyTorch的官方文档。
lr = 0.00005
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=lr)
下面是具体的训练代码:

在测试数据上评估模型
现在我们已经训练了用于抽取实体的BERT模型。在前面数据集准备中还有测试集,这里可以使用测试集来看效果:

另外,上述的效果评估是比较简单的,实际应用中还可以使用更为精细的评估方法,比如按所抽取的实体来评估的方法。更多的用于评估实体抽取的方法可参考《实体抽取:如何评估算法的效果?》 一文。
(https://mp.weixin.qq.com/s/STS8N1PBML_2BvkO5NfiXg)
结论
本文介绍了全面介绍了如何使用BERT进行实体抽取,并给出了代码实例。通过本文,读者可以很方便地“依瓢画葫芦”实现一个基于BERT模型的实体抽取程序,从而学会工业界中最好用的实体抽取模型,并将其应用到学习或工作当中。
具体来说,本文内容包括:
- 介绍了什么是实体抽取
- 介绍了什么是 BERT
- 用代码实例介绍了如何使用 BERT 进行实体抽取的完整过程,这包括四个内容:
- 准备数据
- 构建模型
- 训练模型
- 测试模型效果
参考文献
- Ashish Vaswani etc., Attention Is All You Need, arxiv: 1706.03762, 2017
- Jacob Devlin etc., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arxiv:1810.04805, 2018
- Anna Rogers etc., A Primer in BERTology: What We Know About How BERT Works, arxiv:2002.12327 2020
- 王文广, 知识图谱:认知智能理论与实战, 电子工业出版社, 2022
作者简介
王文广,达观数据副总裁,高级工程师,《知识图谱:认知智能理论与实战》作者,曾获得上海市计算机学会科技进步奖二等奖和上海市浦东新区科技进步奖二等奖,专注于自然语言处理、知识图谱、图像与语音分析、认知智能、大数据和图分析等方向的技术研究和产品开发。现在是上海市人工智能标准化技术委员会委员,上海科委评审专家,中国计算机学会(CCF)高级会员,中文信息学会(CIPS)语言与知识计算专委会委员,中国人工智能学会(CAAI)深度学习专委会委员。申请有数十项人工智能领域的国家发明专利,在国内外知名期刊会议上发表有十多篇学术论文。曾带队获得国内国际顶尖算法竞赛ACM KDD CUP、EMI Hackathon、“中国法研杯”法律智能竞赛、CCKS知识图谱评测的冠亚季军成绩。在达观数据致力于将自然语言处理、知识图谱、计算机视觉和大数据技术产品化,以OCR、文档智能处理、知识图谱、RPA等产品服务于金融、智能制造、贸易、半导体、汽车工业、航空航天、新能源、双碳等领域。