
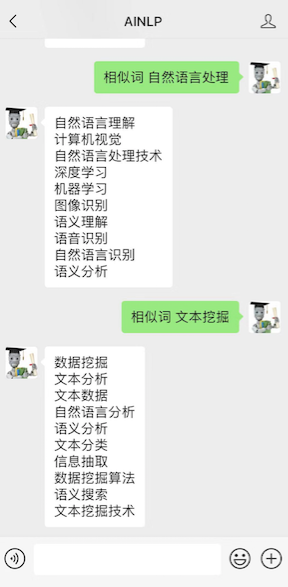
周末闲来无事,给AINLP公众号聊天机器人加了一个技能点:中文相似词查询功能,基于腾讯 AI Lab 之前公布的一个大规模的中文词向量,例如在公众号对话窗口输入"相似词 自然语言处理",会得到:自然语言理解、计算机视觉、自然语言处理技术、深度学习、机器学习、图像识别、语义理解、语音识别、自然语言识别、语义分析;输入"相似词 文本挖掘",会得到:数据挖掘、文本分析、文本数据、自然语言分析、语义分析、文本分类、信息抽取、数据挖掘算法、语义搜索、文本挖掘技术。如下图所示:
关于这份腾讯中文词向量 Tencent_AILab_ChineseEmbedding.txt ,解压后大概16G,可参考去年10月份腾讯官方的描述:腾讯AI Lab开源大规模高质量中文词向量数据,800万中文词随你用
从公开描述来看,这份词向量的质量看起来很不错:
腾讯AI Lab此次公开的中文词向量数据包含800多万中文词汇,其中每个词对应一个200维的向量。相比现有的中文词向量数据,腾讯AI Lab的中文词向量着重提升了以下3个方面,相比已有各类中文词向量大大改善了其质量和可用性:
⒈ 覆盖率(Coverage):
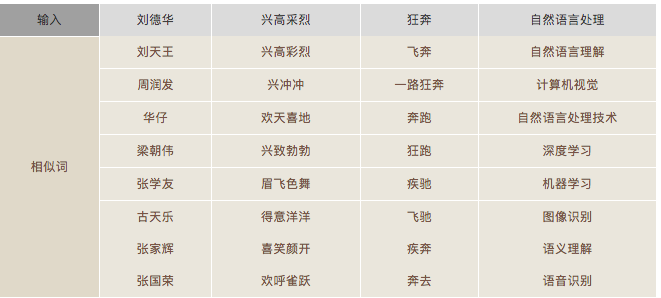
该词向量数据包含很多现有公开的词向量数据所欠缺的短语,比如“不念僧面念佛面”、“冰火两重天”、“煮酒论英雄”、“皇帝菜”、“喀拉喀什河”等。以“喀拉喀什河”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:
墨玉河、和田河、玉龙喀什河、白玉河、喀什河、叶尔羌河、克里雅河、玛纳斯河
⒉ 新鲜度(Freshness):
该数据包含一些最近一两年出现的新词,如“恋与制作人”、“三生三世十里桃花”、“打call”、“十动然拒”、“供给侧改革”、“因吹斯汀”等。以“因吹斯汀”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:
一颗赛艇、因吹斯听、城会玩、厉害了word哥、emmmmm、扎心了老铁、神吐槽、可以说是非常爆笑了
⒊ 准确性(Accuracy):
由于采用了更大规模的训练数据和更好的训练算法,所生成的词向量能够更好地表达词之间的语义关系,如下列相似词检索结果所示:
得益于覆盖率、新鲜度、准确性的提升,在内部评测中,腾讯AI Lab提供的中文词向量数据相比于现有的公开数据,在相似度和相关度指标上均达到了更高的分值。在腾讯公司内部的对话回复质量预测和医疗实体识别等业务场景中,腾讯AI Lab提供的中文词向量数据都带来了显著的性能提升。
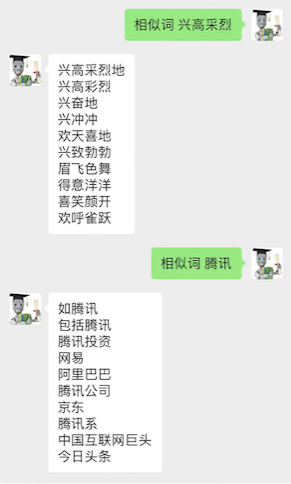
当然官方的说法归官方,我还是遇到了一些bad case,例如输入官方例子 "相似词 兴高采烈" 和输入"相似词 腾讯",我们会发现一些"bad case":
另外这里用到的这份腾讯词向量数据的词条数总计8824330,最长的一个词条是:关于推进传统基础设施领域政府和社会资本合作(ppp)项目资产证券化相关工,查询的结果是:
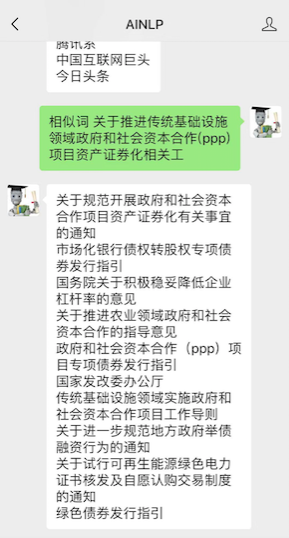
很像一些文章标题,可能预处理的时候没有对词长做一些限制,感兴趣的同学可以详细统计一下这份词向量的词长分布。当然,少量的 bad case 不会降低这份难得的中文词向量的质量,也不会降低我们玩转这份词向量的兴趣,继续测试一些词或者短语。例如输入"相似词 马化腾"、"相似词 马云",会得到:

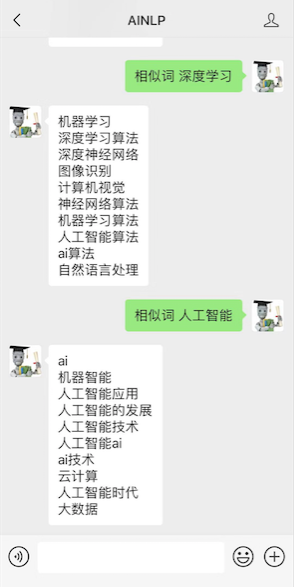
输入"相似词 深度学习"、"相似词 人工智能"会得到:
输入"相似词 AI"、"相似词 NLP"会得到:

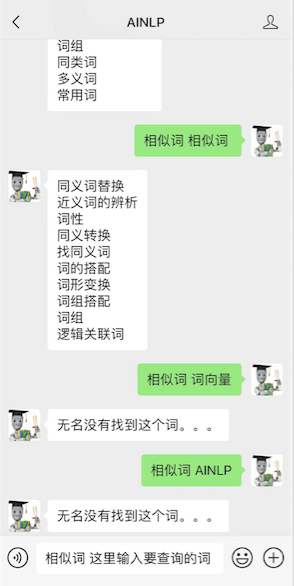
当然,要是输入的"词条"没有在这份词库中,AINLP的聊天机器人无名也无能为力了,例如输入"词向量","AINLP",那是没有的:
需要说明的是,这里的查询功能间接借助了gensim word2vec 的相关接口,在腾讯这份词向量说明文档的主页上也有相关的用法提示:Tencent AI Lab Embedding Corpus for Chinese Words and Phrases,可能一些同学早就试验过了。不过对于那些机器资源条件有限的同学,或者不了解词向量、word2vec的同学,这个微信接口还是可以供你们随时查询相近词的,甚至可以给一些查询同义词、近义词或者反义词的同学提供一些线索,当然,从统计学意义上来看这份词向量的查询结果无法做到语言学意义上的准确,但是很有意思,需要自己去甄别。
最后感兴趣的同学可以关注我们的微信公众号AINLP,随时把玩腾讯 AI Lab 的这份词向量:

注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:https://www.52nlp.cn
本文链接地址:相似词查询:玩转腾讯 AI Lab 中文词向量 https://www.52nlp.cn/?p=11234
句子的相似性,貌似没有好的解决方案
[回复]
52nlp 回复:
5 3 月, 2019 at 18:00
是的,到了句子这个层级,貌似没有漂亮的结果
[回复]
请问一下在计算相似词的时候是用的gensim的word_vectors.most_similar这个函数吗?如果不是,想请问一下你们具体使用了什么包和什么函数,非常感谢!
[回复]
52nlp 回复:
12 3 月, 2019 at 18:15
是的,就是gensim的接口
[回复]
我想请问这个语料你是如何加载的,需要多大的内存才行
[回复]
52nlp 回复:
8 4 月, 2019 at 10:39
就是通过gensim加载的,其实官方文档已经写得很清楚了:
from gensim.models.word2vec import KeyedVectors
wv_from_text = KeyedVectors.load_word2vec_format(file, binary=False)
内存应该大于16G,有点忘了,线上服务还用了一些trick
[回复]
请问一下这个模型这么大,计算相似词的时候加载模型特别慢,您那边微信的查询感觉好快,可以给个提示吗。。
[回复]
52nlp 回复:
9 6 月, 2019 at 17:34
可以试试Annoy:https://www.52nlp.cn/%E8%85%BE%E8%AE%AF%E8%AF%8D%E5%90%91%E9%87%8F%E5%AE%9E%E6%88%98-%E9%80%9A%E8%BF%87annoy%E8%BF%9B%E8%A1%8C%E7%B4%A2%E5%BC%95%E5%92%8C%E5%BF%AB%E9%80%9F%E6%9F%A5%E8%AF%A2
[回复]
这个同义词表,有单独形成文本的吗?我好想要一份。谁有给我邮件发一份,谢谢!
[回复]
52nlp 回复:
29 5 月, 2020 at 11:21
直接去腾讯官方下载这个向量,然后尝试按自己的需求提取一份吧
[回复]
腾讯官方800w词向量的下载地址不可用了,可以分享下吗?
[回复]
52nlp 回复:
20 5 月, 2021 at 17:30
抱歉迟复:https://ai.tencent.com/ailab/nlp/en/embedding.html
[回复]
请问关于反义词请问是以什么样的逻辑计算的呢?
[回复]
52nlp 回复:
22 9 月, 2021 at 10:37
这个是相似词计算的逻辑,里面可能包含反义词
[回复]