
上一篇文章《腾讯词向量实战:通过Annoy进行索引和快速查询》结束后,觉得可以通过Annoy做一点有趣的事,把“词类比(Word Analogy)”操作放到线上,作为AINLP公众号聊天机器人的新技能,毕竟这是word2vec,或者词向量中很有意思的一个特性,刚好,Annoy也提供了一个基于vector进行近似最近邻查询的接口:
get_nns_by_vector(v, n, search_k=-1, include_distances=False) same but query by vector v.
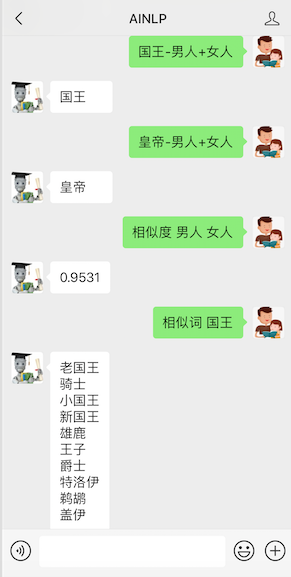
英文词类比中最有名的一个例子大概就是: king - man + woman = queen, 当我把这个例子换成中文映射到腾讯的中文词向量中并且用gensim来计算,竟然能完美复现:国王 - 男人 + 女人 = 王后
In [49]: result = tc_wv_model.most_similar(positive=[u'国王', u'女人'], negative ...: =[u'男人']) In [50]: print("%s\t%.4f" % result[0]) 王后 0.7050 |
然后把国王换成皇帝,还能完美的将“王后”替换为“皇后”:
In [53]: result = tc_wv_model.most_similar(positive=[u'皇帝', u'女人'], negative ...: =[u'男人']) In [54]: print("%s\t%.4f" % result[0]) 皇后 0.8759 |
虽然知道即使在英文词向量中,完美的词类比列子也不多,另外据说换到中文词向量场景下,上述例子会失效,没想到在腾讯AI Lab这份词向量中得到完美复现,还是要赞一下的,虽然感觉这份腾讯词向量在处理词的边界上不够完美,引入了很多无关介词,但是"大力(量)出奇迹",882万的词条数,一方面有很高的词语覆盖率,另外一方面可以完美的将英文词向量空间中的"king - man + woman = queen"映射到中文词向量空间的"国王 - 男人 + 女人 = 王后",不得不感慨一下数学之美,词语之美。
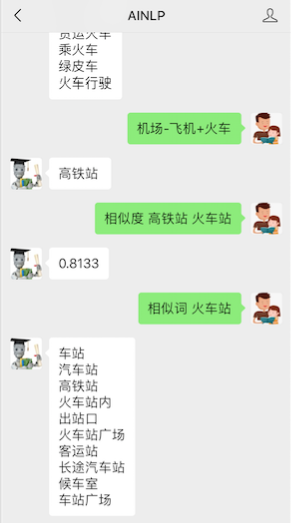
在此前google的时候,据说在中文词向量场景下一个更容易出现的词类比例子是:机场-飞机+火车=火车站,这个确实可以通过gensim在腾讯词向量中得到复现:
In [60]: result = tc_wv_model.most_similar(positive=[u'机场', u'火车'], negative ...: =[u'飞机']) In [61]: print("%s\t%.4f" % result[0]) 火车站 0.7885 |
通过Annoy,我把这个服务做到线上,现在可以在AINLP公众号后台测试,结果看起来也还不错:“机场-飞机+火车=高铁站”:
当把测试用例换回到“国王-男人+女人”或者 “皇帝-男人+女人”结果就有点琢磨不透了:
当然,Annoy的topk最近邻结果是不完全精确的,有两个参数对查询结果影响较大:n_trees 和 search_k
There are just two main parameters needed to tune Annoy: the number of trees n_trees and the number of nodes to inspect during searching search_k.
n_trees is provided during build time and affects the build time and the index size. A larger value will give more accurate results, but larger indexes.
search_k is provided in runtime and affects the search performance. A larger value will give more accurate results, but will take longer time to return.
n_trees影响构建索引时间和索引大小,值越大,结果会越精确,但是索引也会越大,我这次用到的索引构建的时候n_trees是20,无法动态调整;
search_k是查询时的参数,影响检索性能,值越大结果越好,但是查询时间越长,好处是可以动态调整,我将search_k设置到500以上时,“机场-飞机+火车”这个例子的结果变为了“火车站”, 和gensim一致了,不过“国王-男人+女人”这个例子的结果没有变化,考虑到线上服务的响应时间,最终还是把search_k设置的小一些。
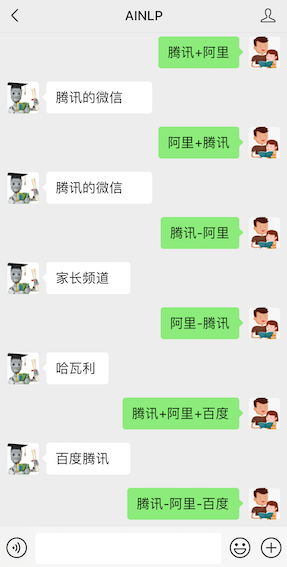
不过除了这几个例子,到目前为止,貌似还没有找到其他比较不错的词类比例子。我想既然如此,索性放开AINLP中这个接口,可以直接玩2个词、3个词的加减法,并且命名为:Game of Words, 记住,是词游,而非权游。
现在,可以拿起你的手机,关注AINLP公众号,然后玩玩词语的加减法游戏了:

请注意,这个词语游戏目前只支持2个词或者3个词的加减法,更多词的暂时不支持,希望大家多玩玩词类比游戏,如果遇到完美例子,非常非常欢迎留言:
最后,欢迎大家脑洞,欢迎把玩,欢迎留言。
注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:https://www.52nlp.cn
本文链接地址:玩转腾讯词向量:Game of Words(词语的加减游戏) https://www.52nlp.cn/?p=11635
发现一个相似度的大概规律,以下词语相似度按照从大到小排列:
1. same field, same direction
2. diff field, same direction
3. same field, diff direction
4. diff field, diff direction
可以配着这个图看https://raw.githubusercontent.com/LinuxerAlan/markdown_photos/master/IMG_6071.jpeg
[回复]
你这个是用的百度的api吧
[回复]
52nlp 回复:
4 11 月, 2019 at 18:48
额,就是用了一下腾讯词向量,其他的就是用代码简单包了一下
[回复]