
斯坦福大学在三月份开设了一门“深度学习与自然语言处理”的课程:CS224d: Deep Learning for Natural Language Processing,授课老师是青年才俊 Richard Socher,以下为相关的课程笔记。
第二讲:简单的词向量表示:word2vec, Glove(Simple Word Vector representations: word2vec, GloVe)
推荐阅读材料:
- Paper1:[Distributed Representations of Words and Phrases and their Compositionality]]
- Paper2:[Efficient Estimation of Word Representations in Vector Space]
- 第二讲Slides [slides]
- 第二讲视频 [video]
以下是第二讲的相关笔记,主要参考自课程的slides,视频和其他相关资料。
如何来表示一个词的意思(meaning)
- 英文单词Meaning的定义(来自于韦氏词典)
- the idea that is represented by a word, phrase, etc.
- the idea that a person wants to express by using words, signs, etc.
- the idea that is expressed in a work of writing, art, etc.
- 通常使用类似Wordnet的这样的语义词典,包含有上位词(is-a)关系和同义词集
- panda的上位词,来自于NLTK中wordnet接口的演示
- good的同义词集
- 语义词典资源很棒但是可能在一些细微之处有缺失,例如这些同义词准确吗:adept, expert, good, practiced, proficient,skillful?
- 会错过一些新词,几乎不可能做到及时更新: wicked, badass, nifty, crack, ace, wizard, genius, ninjia
- 有一定的主观倾向
- 需要大量的人力物力
- 很难用来计算两个词语的相似度
- 传统的基于规则或基于统计的自然语义处理方法将单词看作一个原子符号:hotel, conference, walk
- 在向量空间的范畴里,这是一个1很多0的向量表示:[0,0,0,0,...,0,1,0,...,0,0,0]
- 维数:20K(speech)–50K(PTB)–500K(big vocab)–13M(Google 1T)
- 这就是"one-hot"表示,这种表示方法存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系:
- 通过一个词语的上下文可以学到这个词语的很多知识
- 这是现代统计NLP很成功的一个观点
- 答案:使用共现矩阵(Cooccurrence matrix)X
- 2个选择:全文还是窗口长度
- word-document的共现矩阵最终会得到泛化的主题(例如体育类词汇会有相似的标记),这就是浅层语义分析(LSA, Latent Semantic Analysis)
- 窗口长度容易捕获语法(POS)和语义信息
- 窗口长度是1(一般是5-10)
- 对称(左右内容无关)
- 语料样例
- I like deep learning.
- I like NLP.
- I enjoy flying
- 规模随着语料库词汇的增加而增加
- 非常高的维度:需要大量的存储
- 分类模型会遇到稀疏问题
- 模型不够健壮
- idea: 将最重要的信息存储在固定的,低维度的向量里:密集向量(dense vector)
- 维数通常是25-1000
- 问题:如何降维?
- 对共现矩阵X进行奇异值分解
- 语料:I like deep learning. I like NLP. I enjoy flying
- 打印U矩阵的前两列这也对应了最大的两个奇异值
- 在相关的模型中,包括深度学习模型,一个单词常常用密集向量(dense vector)来表示
- 功能词(the, he, has)过于频繁,对语法有很大影响,解决办法是降低使用或完全忽略功能词
- 延展窗口增加对临近词的计数
- 用皮尔逊相关系数代替计数,并置负数为0
- +++
- 对于n*m矩阵来说计算的时间复杂度是o(mn^2) 当 n
- 对于新词或者新的文档很难及时更新
- 相对于其他的DL模型,有着不同的学习框架
- 一些方法:和本讲以及深度学习相关
- Learning representations by back-propagating errors(Rumelhart et al.,1986)
- A Neural Probabilistic Language Model(Bengio et al., 2003)
- Natural Language Processing (almost) from Scratch(Collobert & Weston,2008)
- word2vec(Mikolov et al. 2013)->本讲介绍
- 与一般的共现计数不同,word2vec主要来预测单词周边的单词
- GloVe和word2vec的思路相似:GloVe: Global Vectors for Word Representation
- 比较容易且快速的融合新的句子和文档或者添加新的单词进入词汇表
- 预测一个窗口长度为c的窗口内每个单词的周边单词概率
- 目标函数:对于一个中心词,最大化周边任意单词的log概率
- 对于$p(w_{t+j}/w_t)$最简单的表达式是:
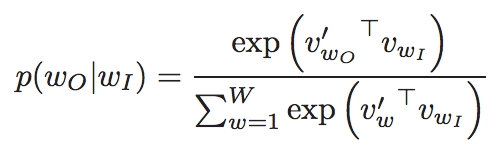
- 这里v和$v^'$分布是w的“输入”和“输出”向量表示(所以每个w都有两个向量表示)
- 这就是基本的“动态”逻辑回归(“dynamic” logistic regression)
- 我们的目标是优化(最大化或最小化)代价/目标函数
- 常用的方法:梯度下降
- 一个例子(来自于维基百科): 寻找函数$f(x) = x^4 - 3x^3 + 2$的局部最小点,其导数是$f^'(x) = 4x^3 - 9x^2$
- Python代码:
- 白板(建议没有直接上课的同学看一下课程视频中的白板推导)
- 有用的公式
- 链式法则
- 这类表示可以很好的对词语相似度进行编码
- 在嵌入空间里相似度的维度可以用向量的减法来进行类别测试
- 训练更快
- 对于大规模语料算法的扩展性也很好
- 在小语料或者小向量上性能表现也很好
- 英文单词frog(青蛙)的最相近的词
- 对单词之间的线性关系进行测试(Mikolov et al.(2014))
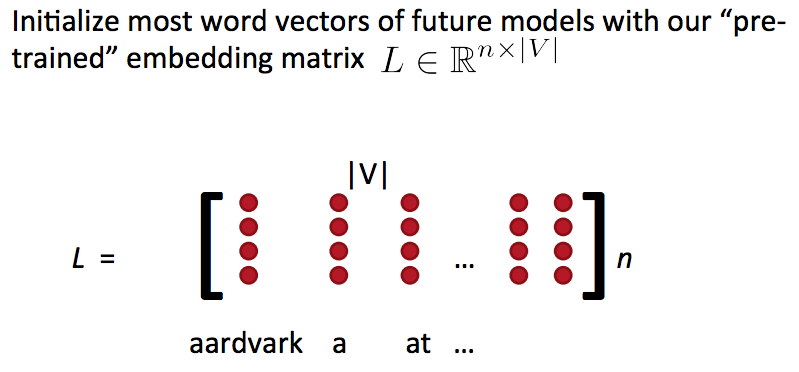
- 提前训练好的词嵌入矩阵
- 又称之为查询表(look-up table)
- 深度学习词向量的最大优势是什么?
- 可以将任何信息表征成词向量的形式然后通过神经网络进行传播
- 词向量将是之后章节的基础
- 我们所有的语义表示都将是向量形式
- 对于长的短语和句子也可以通过词向量的形式组合为更复杂的表示,以此来解决更复杂的任务-->下一讲
在计算机中如何表示一个词的意思
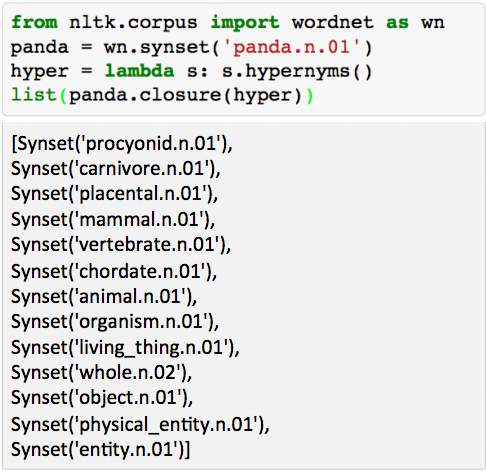

语义词典存在的问题
One-hot Representation

Distributional similarity based representations


如何使用上下文来表示单词
基于窗口的共现矩阵:一个简单例子

存在的问题
解决方案:低维向量
方法1:SVD(奇异值分解)
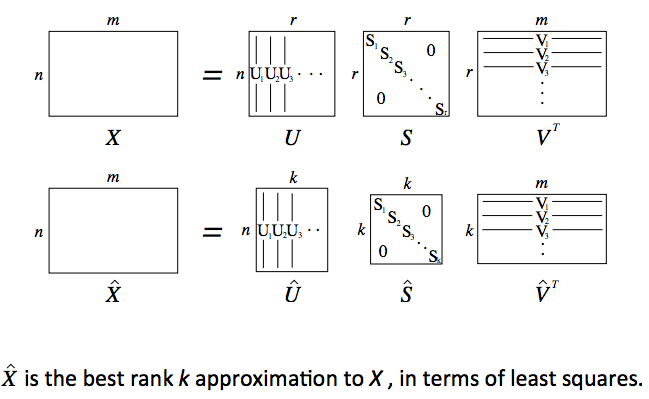
Python中简单的词向量SVD分解

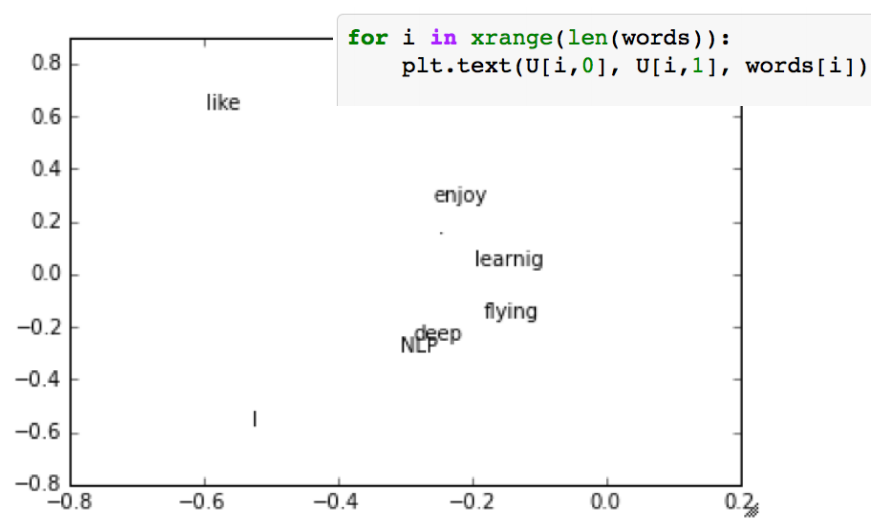
用向量来定义单词的意思:

Hacks to X
词向量中出现的一些有趣的语义Pattern


使用SVD存在的问题
解决方案:直接学习低维度的词向量
word2vec的主要思路
word2vec的主要思路
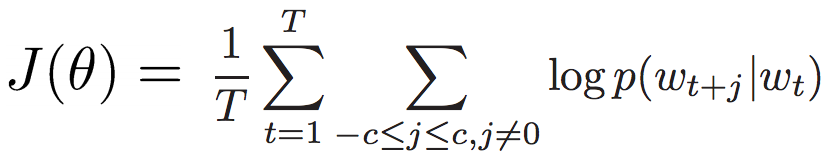
代价/目标函数
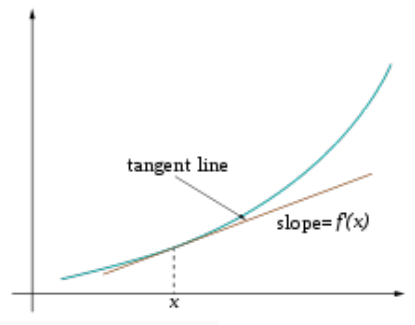

梯度的导数
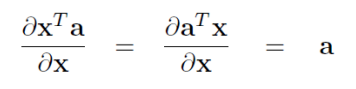
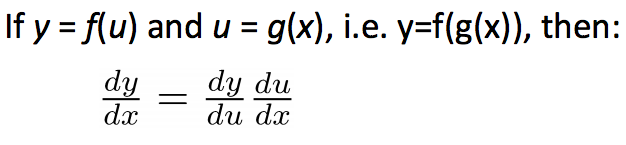
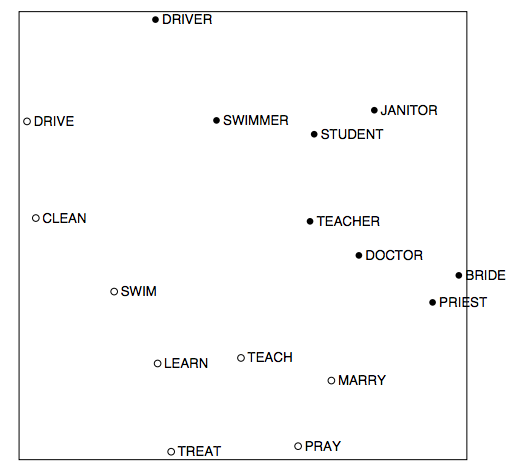
word2vec中的线性关系

计数的方法 vs 直接预测

GloVe: 综合了两类方法的优点

GloVe的效果

Word Analogies(词类比)
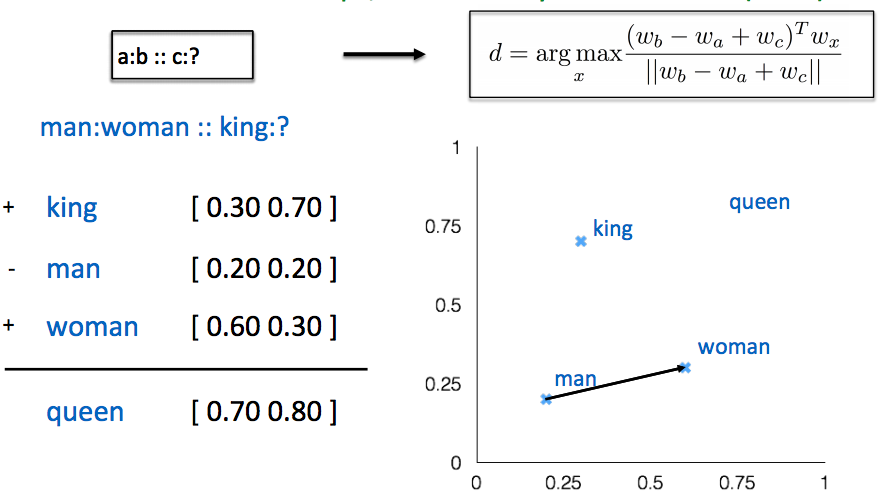
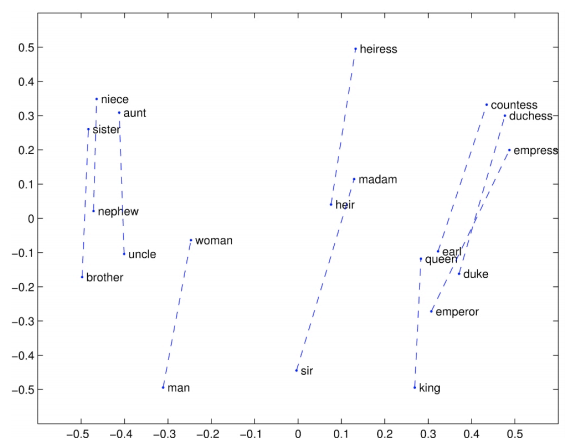
Glove可视化一
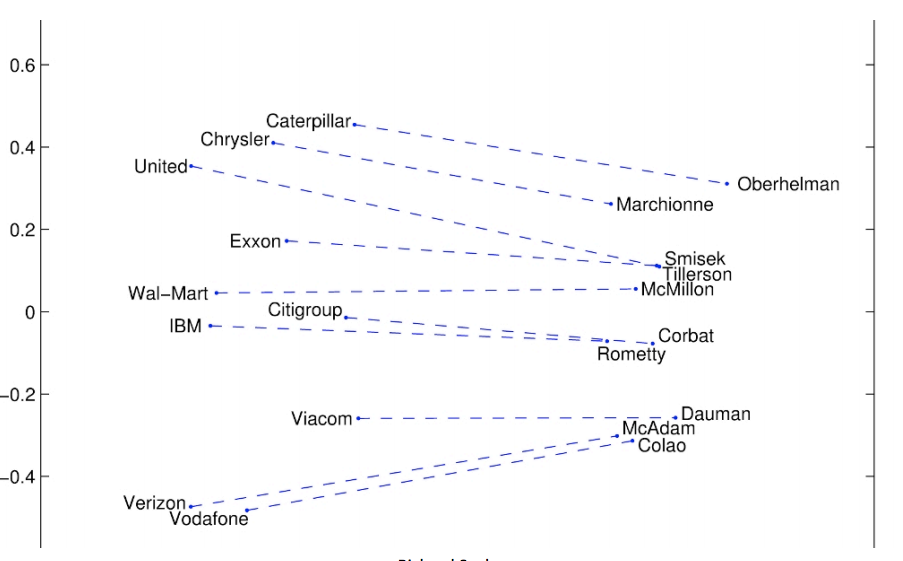
Glove可视化二:Company-CEO
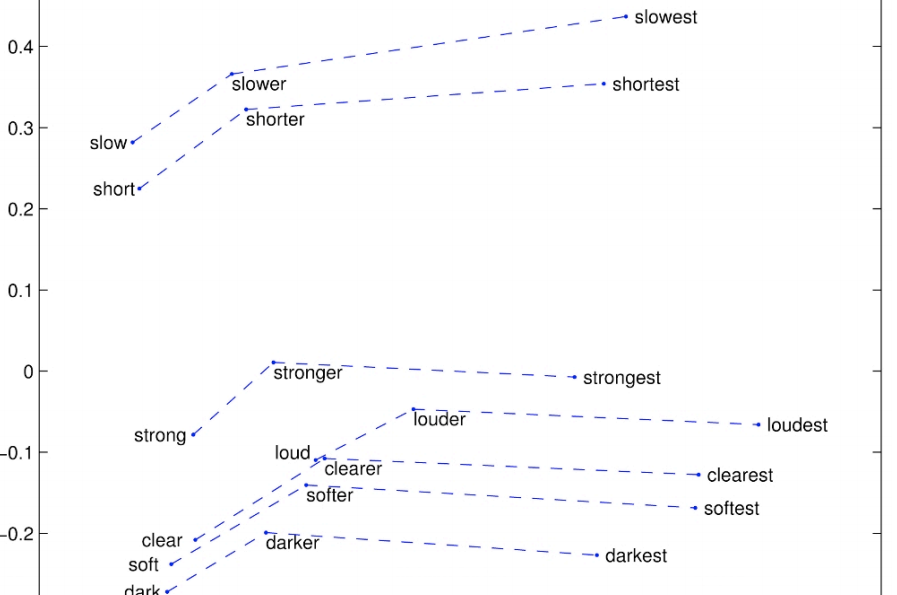
Glove可视化三:Superlatives
Word embedding matrix(词嵌入矩阵)
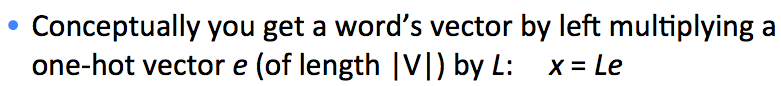
低维度词向量的优点
课程笔记索引:
斯坦福大学深度学习与自然语言处理第一讲:引言
参考资料:
Deep Learning in NLP (一)词向量和语言模型
奇异值分解(We Recommend a Singular Value Decomposition)
注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:https://www.52nlp.cn
本文链接地址:斯坦福大学深度学习与自然语言处理第二讲:词向量
你好,咨询一个问题,是关于句子转换成向量的问题,不知能否解答。
最近在看实体关系抽取(relation extraction)方面的内容,最基本的方法就是把一个句子里的词、词性提取出来,转换成特征向量,然后放到分类模型里跑。我查了一些问题,都是只提到把词、词性提取出来这一步就完了,没有提怎么把这些非数值型特征转换成数值型特征 。 可是放到分类模型里跑的话,必须要是数值型啊。不知道能否解答一下。
谢谢
[回复]
52nlp 回复:
9 6 月, 2015 at 18:08
可以认为这些是离散的0,1特征
[回复]
codding 回复:
18 6 月, 2015 at 13:53
其实可以把特征表示成一个多维的矩阵。比如说位置特征,每个位置都可以用一个特定维数,比如50*1这样的矩阵来表示。这个已经有人做过了。
[回复]
后面的不更新了吗?
[回复]
52nlp 回复:
26 6 月, 2015 at 10:26
稍安勿躁,最近有点忙,回头会更新的
[回复]
博主大大,更博吧,我在一边看您的博客一边做毕业论文,受益匪浅
[回复]
52nlp 回复:
2 7 月, 2015 at 17:31
建议直接看英文原版的,原汁原味,绝对比我这里强;我比较忙,更新的要慢一些
[回复]
持续关注下
[回复]
受益匪浅,看完英文再来看看中文。
[回复]