
之前写过《中英文维基百科语料上的Word2Vec实验》,近期有不少同学在这篇文章下留言提问,加上最近一些工作也与Word2Vec相关,于是又做了一些功课,包括重新过了一遍Word2Vec的相关资料,试了一下gensim的相关更新接口,google了一下"wikipedia word2vec" or "维基百科 word2vec" 相关的英中文资料,发现多数还是走得这篇文章的老路,既通过gensim提供的维基百科预处理脚本"gensim.corpora.WikiCorpus"提取维基语料,每篇文章一行文本存放,然后基于gensim的Word2Vec模块训练词向量模型。这里再提供另一个方法来处理维基百科的语料,训练词向量模型,计算词语相似度(Word Similarity)。关于Word2Vec, 如果英文不错,推荐从这篇文章入手读相关的资料: Getting started with Word2Vec 。
这次我们仅以英文维基百科语料为例,首先依然是下载维基百科的最新XML打包压缩数据,在这个英文最新更新的数据列表下:https://dumps.wikimedia.org/enwiki/latest/ ,找到 "enwiki-latest-pages-articles.xml.bz2" 下载,这份英文维基百科全量压缩数据的打包时间大概是2017年4月4号,大约13G,我通过家里的电脑wget下载大概花了3个小时,电信100M宽带,速度还不错。
接下来就是处理这份压缩的XML英文维基百科语料了,这次我们使用WikiExtractor:
WikiExtractor.py is a Python script that extracts and cleans text from a Wikipedia database dump.
The tool is written in Python and requires Python 2.7 or Python 3.3+ but no additional library.
WikiExtractor是一个Python 脚本,专门用于提取和清洗Wikipedia的dump数据,支持Python 2.7 或者 Python 3.3+,无额外依赖,安装和使用都非常方便:
安装:
git clone https://github.com/attardi/wikiextractor.git
cd wikiextractor/
sudo python setup.py install
使用:
WikiExtractor.py -o enwiki enwiki-latest-pages-articles.xml.bz2
...... INFO: 53665431 Pampapaul INFO: 53665433 Charles Frederick Zimpel INFO: Finished 11-process extraction of 5375019 articles in 8363.5s (642.7 art/s) |
这个过程总计花了2个多小时,提取了大概537万多篇文章。关于我的机器配置,可参考:《深度学习主机攒机小记》
提取后的文件按一定顺序切分存储在多个子目录下:
每个子目录下的又存放若干个以wiki_num命名的文件,每个大小在1M左右,这个大小可以通过参数 -b 控制:
-b n[KMG], --bytes n[KMG] maximum bytes per output file (default 1M)
我们看一下wiki_00里的具体内容:
Anarchism
Anarchism is a political philosophy that advocates self-governed societies based on voluntary institutions. These are often described as stateless societies, although several authors have defined them more specifically as institutions based on non-hierarchical free associations. Anarchism holds the state to be undesirable, unnecessary, and harmful.
...
Criticisms of anarchism include moral criticisms and pragmatic criticisms. Anarchism is often evaluated as unfeasible or utopian by its critics.
Autism
Autism is a neurodevelopmental disorder characterized by impaired social interaction, verbal and non-verbal communication, and restricted and repetitive behavior. Parents usually notice signs in the first two years of their child's life. These signs often develop gradually, though some children with autism reach their developmental milestones at a normal pace and then regress. The diagnostic criteria require that symptoms become apparent in early childhood, typically before age three.
...
...
每个wiki_num文件里又存放若干个doc,每个doc都有相关的tag标记,包括id, url, title等,很好区分。
这里我们按照Gensim作者提供的word2vec tutorial里"memory-friendly iterator"方式来处理英文维基百科的数据。代码如下,也同步放到了github里:train_word2vec_with_gensim.py
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: Pan Yang (panyangnlp@gmail.com) # Copyright 2017 @ Yu Zhen import gensim import logging import multiprocessing import os import re import sys from pattern.en import tokenize from time import time logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) def cleanhtml(raw_html): cleanr = re.compile('<.*?>') cleantext = re.sub(cleanr, ' ', raw_html) return cleantext class MySentences(object): def __init__(self, dirname): self.dirname = dirname def __iter__(self): for root, dirs, files in os.walk(self.dirname): for filename in files: file_path = root + '/' + filename for line in open(file_path): sline = line.strip() if sline == "": continue rline = cleanhtml(sline) tokenized_line = ' '.join(tokenize(rline)) is_alpha_word_line = [word for word in tokenized_line.lower().split() if word.isalpha()] yield is_alpha_word_line if __name__ == '__main__': if len(sys.argv) != 2: print "Please use python train_with_gensim.py data_path" exit() data_path = sys.argv[1] begin = time() sentences = MySentences(data_path) model = gensim.models.Word2Vec(sentences, size=200, window=10, min_count=10, workers=multiprocessing.cpu_count()) model.save("data/model/word2vec_gensim") model.wv.save_word2vec_format("data/model/word2vec_org", "data/model/vocabulary", binary=False) end = time() print "Total procesing time: %d seconds" % (end - begin) |
注意其中的word tokenize使用了pattern里的英文tokenize模块,当然,也可以使用nltk里的word_tokenize模块,做一点修改即可,不过nltk对于句尾的一些词的work tokenize处理的不太好。另外我们设定词向量维度为200, 窗口长度为10, 最小出现次数为10,通过 is_alpha() 函数过滤掉标点和非英文词。现在可以用这个脚本来训练英文维基百科的Word2Vec模型了:
python train_word2vec_with_gensim.py enwiki
2017-04-22 14:31:04,703 : INFO : collecting all words and their counts 2017-04-22 14:31:04,704 : INFO : PROGRESS: at sentence #0, processed 0 words, keeping 0 word types 2017-04-22 14:31:06,442 : INFO : PROGRESS: at sentence #10000, processed 480546 words, keeping 33925 word types 2017-04-22 14:31:08,104 : INFO : PROGRESS: at sentence #20000, processed 983240 words, keeping 51765 word types 2017-04-22 14:31:09,685 : INFO : PROGRESS: at sentence #30000, processed 1455218 words, keeping 64982 word types 2017-04-22 14:31:11,349 : INFO : PROGRESS: at sentence #40000, processed 1957479 words, keeping 76112 word types ...... 2017-04-23 02:50:59,844 : INFO : worker thread finished; awaiting finish of 2 more threads 2017-04-23 02:50:59,844 : INFO : worker thread finished; awaiting finish of 1 more threads 2017-04-23 02:50:59,854 : INFO : worker thread finished; awaiting finish of 0 more threads 2017-04-23 02:50:59,854 : INFO : training on 8903084745 raw words (6742578791 effective words) took 37805.2s, 178351 effective words/s 2017-04-23 02:50:59,855 : INFO : saving Word2Vec object under data/model/word2vec_gensim, separately None 2017-04-23 02:50:59,855 : INFO : not storing attribute syn0norm 2017-04-23 02:50:59,855 : INFO : storing np array 'syn0' to data/model/word2vec_gensim.wv.syn0.npy 2017-04-23 02:51:00,241 : INFO : storing np array 'syn1neg' to data/model/word2vec_gensim.syn1neg.npy 2017-04-23 02:51:00,574 : INFO : not storing attribute cum_table 2017-04-23 02:51:13,886 : INFO : saved data/model/word2vec_gensim 2017-04-23 02:51:13,886 : INFO : storing vocabulary in data/model/vocabulary 2017-04-23 02:51:17,480 : INFO : storing 868777x200 projection weights into data/model/word2vec_org Total procesing time: 44476 seconds |
这个训练过程中大概花了12多小时,训练后的文件存放在data/model下:

我们来测试一下这个英文维基百科的Word2Vec模型:
textminer@textminer:/opt/wiki/data$ ipython Python 2.7.12 (default, Nov 19 2016, 06:48:10) Type "copyright", "credits" or "license" for more information. IPython 2.4.1 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: from gensim.models import Word2Vec In [2]: en_wiki_word2vec_model = Word2Vec.load('data/model/word2vec_gensim') |
首先来测试几个单词的相似单词(Word Similariy):
word:
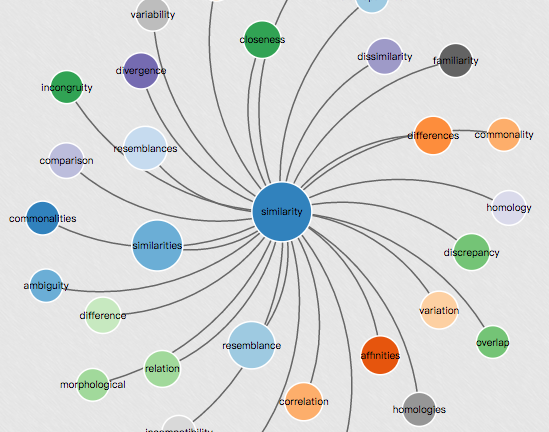
In [3]: en_wiki_word2vec_model.most_similar('word') Out[3]: [('phrase', 0.8129693269729614), ('meaning', 0.7311851978302002), ('words', 0.7010501623153687), ('adjective', 0.6805518865585327), ('noun', 0.6461974382400513), ('suffix', 0.6440576314926147), ('verb', 0.6319557428359985), ('loanword', 0.6262609958648682), ('proverb', 0.6240501403808594), ('pronunciation', 0.6105246543884277)] |
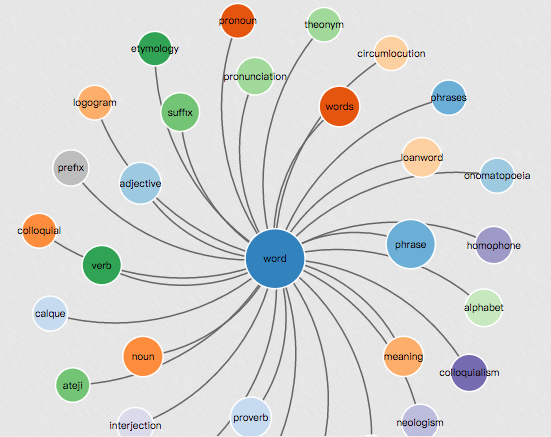
In [4]: en_wiki_word2vec_model.most_similar('similarity') Out[4]: [('similarities', 0.8517599701881409), ('resemblance', 0.786037266254425), ('resemblances', 0.7496883869171143), ('affinities', 0.6571112275123596), ('differences', 0.6465682983398438), ('dissimilarities', 0.6212711930274963), ('correlation', 0.6071442365646362), ('dissimilarity', 0.6062943935394287), ('variation', 0.5970577001571655), ('difference', 0.5928016901016235)] |
nlp:
In [5]: en_wiki_word2vec_model.most_similar('nlp') Out[5]: [('neurolinguistic', 0.6698148250579834), ('psycholinguistic', 0.6388964056968689), ('connectionism', 0.6027182936668396), ('semantics', 0.5866401195526123), ('connectionist', 0.5865628719329834), ('bandler', 0.5837364196777344), ('phonics', 0.5733655691146851), ('psycholinguistics', 0.5613113641738892), ('bootstrapping', 0.559638261795044), ('psychometrics', 0.5555593967437744)] |
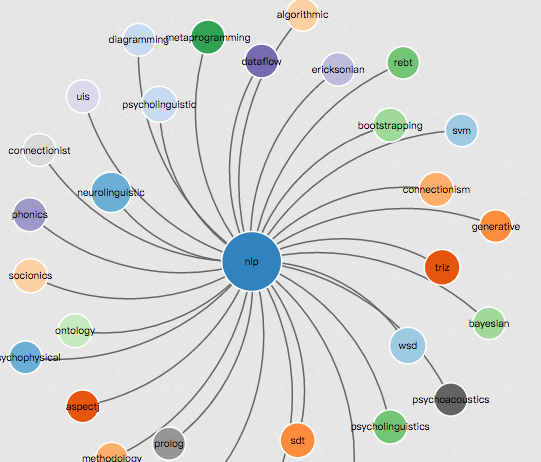
In [6]: en_wiki_word2vec_model.most_similar('learn') Out[6]: [('teach', 0.7533557415008545), ('understand', 0.71148681640625), ('discover', 0.6749690771102905), ('learned', 0.6599283218383789), ('realize', 0.6390970349311829), ('find', 0.6308424472808838), ('know', 0.6171890497207642), ('tell', 0.6146825551986694), ('inform', 0.6008728742599487), ('instruct', 0.5998791456222534)] |
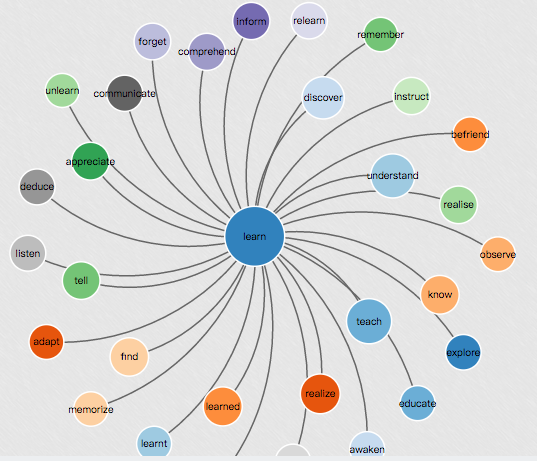
man:
In [7]: en_wiki_word2vec_model.most_similar('man') Out[7]: [('woman', 0.7243080735206604), ('boy', 0.7029494047164917), ('girl', 0.6441491842269897), ('stranger', 0.63275545835495), ('drunkard', 0.6136815547943115), ('gentleman', 0.6122575998306274), ('lover', 0.6108279228210449), ('thief', 0.609005331993103), ('beggar', 0.6083744764328003), ('person', 0.597919225692749)] |
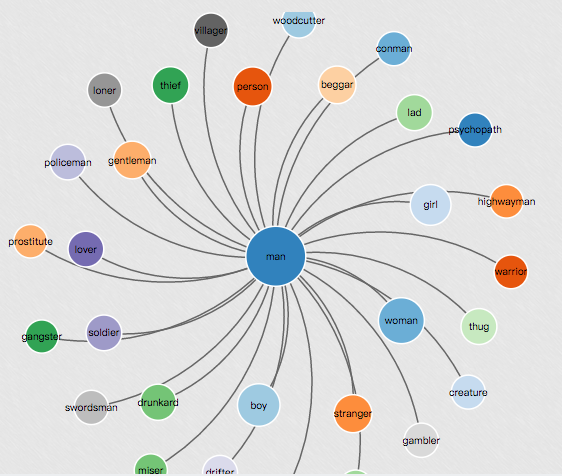
再来看看其他几个相关接口:
In [8]: en_wiki_word2vec_model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) Out[8]: [('queen', 0.7752252817153931)] In [9]: en_wiki_word2vec_model.similarity('woman', 'man') Out[9]: 0.72430799548282099 In [10]: en_wiki_word2vec_model.doesnt_match("breakfast cereal dinner lunch".split()) Out[10]: 'cereal' |
我把这篇文章的相关代码还有另一篇“中英文维基百科语料上的Word2Vec实验”的相关代码整理了一下,在github上建立了一个 Wikipedia_Word2vec 的项目,感兴趣的同学可以参考。
注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:https://www.52nlp.cn
本文链接地址:维基百科语料中的词语相似度探索 https://www.52nlp.cn/?p=9454
请问博主,关于相似度关系可视化是使用了哪个python库?
然后关于w2v方面,我在用爬虫爬取网页数据进行处理分析的时候,w2v里,将多个网页合并成一篇长文本,然后作为一个sentence拿去交给w2v训练,这个与分开成多份sentence相比,训练结果影响大吗?
[回复]
52nlp 回复:
28 5 月, 2017 at 15:45
不是python库,D3.js; 影响应该不大。
[回复]
博主您好,看了你的文章,了解到gensim支持对英文的相似度对比,我想用gensim实现中文文档之间的相似度比对,类似于一个简陋版的论文查重系统,请问实现的思路是什么?请指教。
[回复]
52nlp 回复:
19 7 月, 2017 at 09:58
gensim里使用topic model计算文档的相似度,可参考:https://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%80
[回复]
博主您好啊,词相似度展示的图片是用什么生成的啊,感觉很直观啊,想学习
[回复]
52nlp 回复:
4 8 月, 2017 at 14:02
D3
[回复]
博主您好
請問pattern是否只支援python2 ,因為我在python3.5下裝不起來
另外如果想要用nltk ,程式碼要怎麼改呢?
謝謝
[回复]
52nlp 回复:
10 8 月, 2017 at 10:05
修改一行: from nltk import word_tokenize as tokenize
或者
from nltk import word_tokenize
....
is_alpha_word_line = [word for word in word_tokenize(rline.lower()) if word.isalpha()]
删掉
tokenized_line = ' '.join(tokenize(rline))
[回复]
博主您好
請教一下word2vec訓練出來的詞向量,維度所代表的意義是什麼?(也就是訓練模型時的size參數)
假設訓練時size=100,代表他是用100個特徵去描述每一個詞在該向量空間之位置嗎?
謝謝
[回复]
52nlp 回复:
3 9 月, 2017 at 22:16
如果size=2,就是我们常见的平面坐标;size=3, 就是3维空间坐标的意思;size=100,就是数学上的100维度的意思,差不多你说的意思,每一个维度上都有一个值,用100个值去描述它的位置
[回复]
你好我用windows下处理英文预料 得到的文件和大小和你的基本一致 为什么我在加载的时候出现ioerror:errno22
invalid mode ('rb')or filename?
[回复]
52nlp 回复:
7 9 月, 2017 at 09:28
windows下可能需要在文件名前加个r,参考 http://blog.csdn.net/orangehdc/article/details/39735323
[回复]
博主好,非常感谢您的分享。我们实验室一个项目需要用到word2vec,看了您博客上留的github地址,但是没有发现您训练好的英文模型,请问能否共享一下呢?因为我们只是用到,能实现功能就好,谢谢您
[回复]
52nlp 回复:
20 9 月, 2017 at 14:16
自己动手,丰衣足食。这个github上有一些英文word2vec模型下载地址,可以看看 https://github.com/3Top/word2vec-api
[回复]
hi, 博主,您好, 谢谢分享;
在复现您的文章的情况下出现了点小错误,给您提醒一下。
Traceback (most recent call last):
File "/software/home/recsys/opt/anaconda3/lib/python3.6/site-packages/gensim/utils.py", line 495, in save
_pickle.dump(self, fname_or_handle, protocol=pickle_protocol)
TypeError: file must have a 'write' attribute
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "train_word2vec_with_gensim.py", line 59, in
model.save("data/model/word2vec_gensim")
File "/software/home/recsys/opt/anaconda3/lib/python3.6/site-packages/gensim/models/word2vec.py", line 1514, in save
super(Word2Vec, self).save(*args, **kwargs)
File "/software/home/recsys/opt/anaconda3/lib/python3.6/site-packages/gensim/utils.py", line 498, in save
self._smart_save(fname_or_handle, separately, sep_limit, ignore, pickle_protocol=pickle_protocol)
File "/software/home/recsys/opt/anaconda3/lib/python3.6/site-packages/gensim/utils.py", line 373, in _smart_save
compress, subname)
File "/software/home/recsys/opt/anaconda3/lib/python3.6/site-packages/gensim/utils.py", line 415, in _save_specials
restores.extend(val._save_specials(cfname, None, sep_limit, ignore, pickle_protocol, compress, subname))
File "/software/home/recsys/opt/anaconda3/lib/python3.6/site-packages/gensim/utils.py", line 427, in _save_specials
np.save(subname(fname, attrib), np.ascontiguousarray(val))
File "/software/home/recsys/opt/anaconda3/lib/python3.6/site-packages/numpy/lib/npyio.py", line 490, in save
fid = open(file, "wb")
FileNotFoundError: [Errno 2] No such file or directory: 'data/model/word2vec_gensim.wv.syn0.npy'
模型在最后保存的时候存在路径名称找不到的错误, 其原因是在调用 model.save("data/model/word2vec_gensim")的时候传入参数为 str 类型时, 最终会调用 np.save 函数, 该函数在保存 np的数组对象的时候,需要确保路径名存在,否则报错。
在训练模型之前,似乎需要 mkdir -p data/model
[回复]
52nlp 回复:
9 1 月, 2018 at 21:48
谢谢
[回复]
在运行代码 python train_word2vec_with_gensim.py enwiki 之后, 最终会出现错误如下:
2018-04-20 22:25:14,205 : INFO : worker thread finished; awaiting finish of 0 more threads
2018-04-20 22:25:14,205 : INFO : EPOCH - 5 : training on 62316771 raw words (46692557 effective words) took 423.0s, 110394 effective words/s
2018-04-20 22:25:14,205 : INFO : training on a 311583855 raw words (233479975 effective words) took 2074.4s, 112554 effective words/s
2018-04-20 22:25:14,206 : INFO : saving Word2Vec object under data/model/word2vec_gensim, separately None
2018-04-20 22:25:14,206 : INFO : storing np array 'vectors' to data/model/word2vec_gensim.wv.vectors.npy
Traceback (most recent call last):
File "train_word2vec_with_gensim.py", line 59, in
model.save("data/model/word2vec_gensim")
File "/home/lentitude/.local/lib/python2.7/site-packages/gensim/models/word2vec.py", line 930, in save
super(Word2Vec, self).save(*args, **kwargs)
File "/home/lentitude/.local/lib/python2.7/site-packages/gensim/models/base_any2vec.py", line 281, in save
super(BaseAny2VecModel, self).save(fname_or_handle, **kwargs)
File "/home/lentitude/.local/lib/python2.7/site-packages/gensim/utils.py", line 691, in save
self._smart_save(fname_or_handle, separately, sep_limit, ignore, pickle_protocol=pickle_protocol)
File "/home/lentitude/.local/lib/python2.7/site-packages/gensim/utils.py", line 548, in _smart_save
compress, subname)
File "/home/lentitude/.local/lib/python2.7/site-packages/gensim/utils.py", line 608, in _save_specials
restores.extend(val._save_specials(cfname, None, sep_limit, ignore, pickle_protocol, compress, subname))
File "/home/lentitude/.local/lib/python2.7/site-packages/gensim/utils.py", line 620, in _save_specials
np.save(subname(fname, attrib), np.ascontiguousarray(val))
File "/home/lentitude/.local/lib/python2.7/site-packages/numpy/lib/npyio.py", line 492, in save
fid = open(file, "wb")
IOError: [Errno 2] No such file or directory: 'data/model/word2vec_gensim.wv.vectors.npy'
不知道这个是哪方面出了问题?麻烦请教下
[回复]
52nlp 回复:
21 4 月, 2018 at 17:15
错误有提示的:fid = open(file, "wb")
IOError: [Errno 2] No such file or directory: 'data/model/word2vec_gensim.wv.vectors.npy'
应该是先建好相应的子目录: data/model/
[回复]
刘湧敦 回复:
1 6 月, 2018 at 22:09
你好,报错之后难道要重新跑一遍吗?不要啊,电脑配置low,跑了两天才好,不想在跑一次了!!!!
[回复]
博主你好,如果出现了楼上那种“file not found”的错误是不是要建好子目录重新运行一遍啊?
[回复]
52nlp 回复:
2 6 月, 2018 at 11:03
应该是的,抱歉
[回复]
大神,求助呀!近日查阅gensim发现,关于词语相似度计算有两种情况,一种是model.similarity(词1,词2),第二种情况是model.n_similarity([词列表1],[词列表2])。第一种情况计算两个词的余弦相似度,第二种情况是计算两组词的余弦相似度。现在问题是第二种情况具体是如何计算的?实在搞不清楚。gensim官网没有找到解释(或许是我找的不仔细,但实在找不到),目前百度可找到的就是以下内容,https://blog.csdn.net/mrynr/article/details/52983038
:
n_similarity(ws1, ws2) , 计算两组字之间的余弦相似度。
例:
>>> trained_model.n_similarity(['sushi','shop'], ['japanese','restaurant'])
0.61540466561049689
>>> trained_model.n_similarity(['restaurant','japanese'], ['japanese','restaurant'])
1.0000000000000004
>>> trained_model.n_similarity(['sushi'], ['restaurant'])== trained_model.similarity('sushi','restaurant')
True
求版主解惑,这个n_similarity()函数是如何计算的呀?非常感谢!
[回复]
52nlp 回复:
8 1 月, 2019 at 17:32
很久没有关注gensim,查了一下官方文档和github官方代码,应该是先对各组vector求均值,再计算两个均值的cosine相似度,每组vector可以认为是来自一篇文档:
https://radimrehurek.com/gensim/models/keyedvectors.html
n_similarity(ds1, ds2)
Compute cosine similarity between two sets of docvecs from the trained set.
TODO: Accept vectors of out-of-training-set docs, as if from inference.
Parameters:
ds1 (list of {str, int}) – Set of document as sequence of doctags/indexes.
ds2 (list of {str, int}) – Set of document as sequence of doctags/indexes.
Returns:
The cosine similarity between the means of the documents in each of the two sets.
Return type:
float
https://github.com/RaRe-Technologies/gensim/blob/9c5215afe3bc4edba7dde565b6f2db982bba5113/gensim/models/keyedvectors.py
[回复]
波特 回复:
8 1 月, 2019 at 20:04
非常感谢斑竹回复,谢谢呀!
[回复]
请问博主,在执行python train_word2vec_with_gensim.py enwiki后,出现了错误。
2019-04-08 17:49:07,956 : INFO : collecting all words and their counts
2019-04-08 17:49:07,956 : INFO : collected 0 word types from a corpus of 0 raw words and 0 sentences
2019-04-08 17:49:07,957 : INFO : Loading a fresh vocabulary
2019-04-08 17:49:07,958 : INFO : effective_min_count=2 retains 0 unique words (0% of original 0, drops 0)
2019-04-08 17:49:07,959 : INFO : effective_min_count=2 leaves 0 word corpus (0% of original 0, drops 0)
2019-04-08 17:49:07,959 : INFO : deleting the raw counts dictionary of 0 items
2019-04-08 17:49:07,960 : INFO : sample=0.001 downsamples 0 most-common words
2019-04-08 17:49:07,960 : INFO : downsampling leaves estimated 0 word corpus (0.0% of prior 0)
2019-04-08 17:49:07,960 : INFO : estimated required memory for 0 words and 200 dimensions: 0 bytes
2019-04-08 17:49:07,960 : INFO : resetting layer weights
Traceback (most recent call last):
File "train_word2vec_with_gensim.py", line 52, in
workers=multiprocessing.cpu_count())
File "C:\Users\dzh\Anaconda\lib\site-packages\gensim\models\word2vec.py", line 783, in __init__
fast_version=FAST_VERSION)
File "C:\Users\dzh\Anaconda\lib\site-packages\gensim\models\base_any2vec.py", line 763, in __init__
end_alpha=self.min_alpha, compute_loss=compute_loss)
File "C:\Users\dzh\Anaconda\lib\site-packages\gensim\models\word2vec.py", line 910, in train
queue_factor=queue_factor, report_delay=report_delay, compute_loss=compute_loss, callbacks=callbacks)
File "C:\Users\dzh\Anaconda\lib\site-packages\gensim\models\base_any2vec.py", line 1081, in train
**kwargs)
File "C:\Users\dzh\Anaconda\lib\site-packages\gensim\models\base_any2vec.py", line 536, in train
total_words=total_words, **kwargs)
File "C:\Users\dzh\Anaconda\lib\site-packages\gensim\models\base_any2vec.py", line 1187, in _check_training_sanity
raise RuntimeError("you must first build vocabulary before training the model")
RuntimeError: you must first build vocabulary before training the model
请问要怎么样解决呢?
[回复]
52nlp 回复:
8 4 月, 2019 at 21:01
不太清楚近期gensim是否有升级,如果从最后一句错误看,可能有预处理构建词汇表的一个步骤,google一下吧
[回复]
您好!我直接解压wiki的英文语料,发现应该有69G的数据,但是用wikiextracor抽取,就只有13G的数据,我看楼主抽出来的数据大概也就13G,楼主有发现这个问题嘛?
[回复]
52nlp 回复:
11 11 月, 2019 at 17:46
这个没有注意
[回复]