
近几年来,基于神经网络的深度学习方法在计算机视觉、语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展。在NLP的关键性基础任务—命名实体识别(Named Entity Recognition,NER)的研究中,深度学习也获得了不错的效果。最近,笔者阅读了一系列基于深度学习的NER研究的相关论文,并将其应用到达观的NER基础模块中,在此进行一下总结,与大家一起分享学习。
1、NER 简介
NER又称作专名识别,是自然语言处理中的一项基础任务,应用范围非常广泛。命名实体一般指的是文本中具有特定意义或者指代性强的实体,通常包括人名、地名、组织机构名、日期时间、专有名词等。NER系统就是从非结构化的输入文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。因此实体这个概念可以很广,只要是业务需要的特殊文本片段都可以称为实体。

学术上NER所涉及的命名实体一般包括3大类(实体类,时间类,数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)。
实际应用中,NER模型通常只要识别出人名、地名、组织机构名、日期时间即可,一些系统还会给出专有名词结果(比如缩写、会议名、产品名等)。货币、百分比等数字类实体可通过正则搞定。另外,在一些应用场景下会给出特定领域内的实体,如书名、歌曲名、期刊名等。
NER是NLP中一项基础性关键任务。从自然语言处理的流程来看,NER可以看作词法分析中未登录词识别的一种,是未登录词中数量最多、识别难度最大、对分词效果影响最大问题。同时NER也是关系抽取、事件抽取、知识图谱、机器翻译、问答系统等诸多NLP任务的基础。
NER当前并不算是一个大热的研究课题,因为学术界部分学者认为这是一个已经解决的问题。当然也有学者认为这个问题还没有得到很好地解决,原因主要有:命名实体识别只是在有限的文本类型(主要是新闻语料中)和实体类别(主要是人名、地名、组织机构名)中取得了不错的效果;与其他信息检索领域相比,实体命名评测预料较小,容易产生过拟合;命名实体识别更侧重高召回率,但在信息检索领域,高准确率更重要;通用的识别多种类型的命名实体的系统性能很差。
2. 深度学习方法在NER中的应用
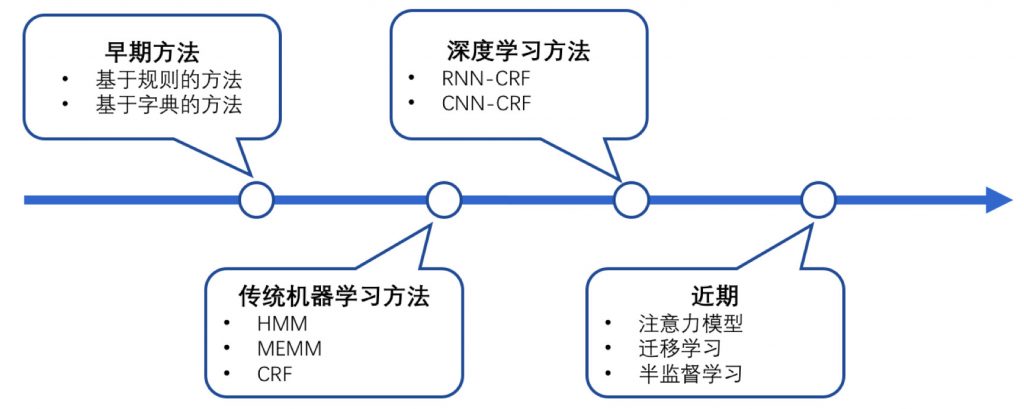
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。
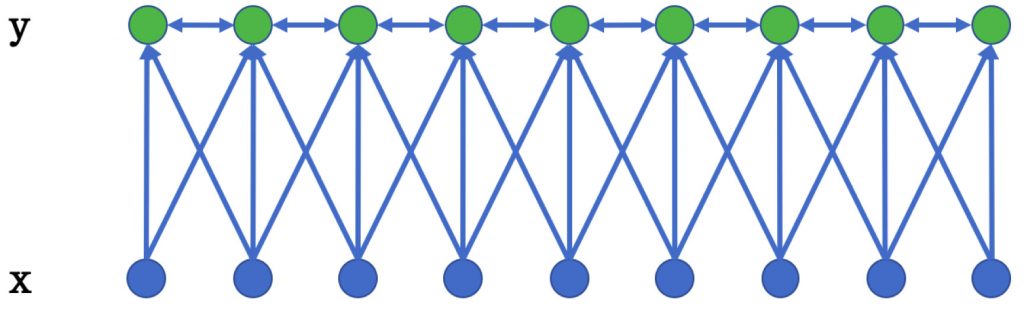
在基于机器学习的方法中,NER被当作序列标注问题。利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。NER 任务中的常用模型包括生成式模型HMM、判别式模型CRF等。条件随机场(ConditionalRandom Field,CRF)是NER目前的主流模型。它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用SGD学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用Viterbi算法解码来得到最优标签序列。CRF的优点在于其为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息。
近年来,随着硬件计算能力的发展以及词的分布式表示(word embedding)的提出,神经网络可以有效处理许多NLP任务。这类方法对于序列标注任务(如CWS、POS、NER)的处理方式是类似的:将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,用神经网络自动提取特征,Softmax来预测每个token的标签。
这种方法使得模型的训练成为一个端到端的过程,而非传统的pipeline,不依赖于特征工程,是一种数据驱动的方法,但网络种类繁多、对参数设置依赖大,模型可解释性差。此外,这种方法的一个缺点是对每个token打标签的过程是独立的进行,不能直接利用上文已经预测的标签(只能靠隐含状态传递上文信息),进而导致预测出的标签序列可能是无效的,例如标签I-PER后面是不可能紧跟着B-PER的,但Softmax不会利用到这个信息。
学界提出了DL-CRF模型做序列标注。在神经网络的输出层接入CRF层(重点是利用标签转移概率)来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。
2.1 BiLSTM-CRF
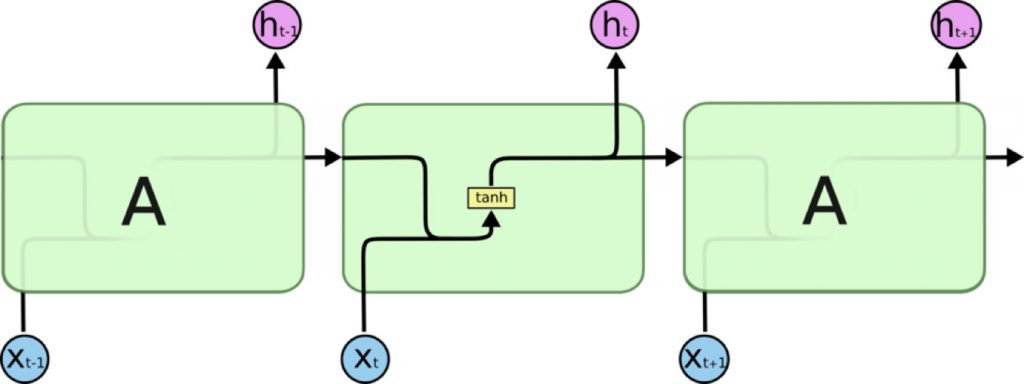
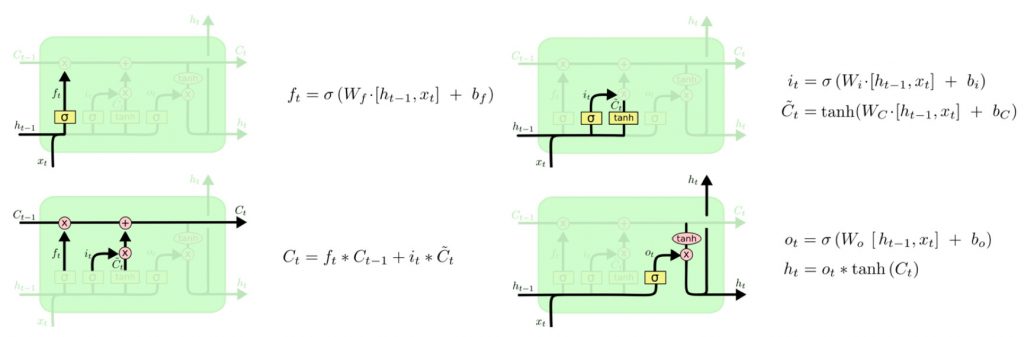
LongShort Term Memory网络一般叫做LSTM,是RNN的一种特殊类型,可以学习长距离依赖信息。LSTM 由Hochreiter &Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题上,LSTM 都取得了相当巨大的成功,并得到了广泛的使用。LSTM 通过巧妙的设计来解决长距离依赖问题。
所有 RNN 都具有一种重复神经网络单元的链式形式。在标准的RNN中,这个重复的单元只有一个非常简单的结构,例如一个tanh层。
LSTM 同样是这样的结构,但是重复的单元拥有一个不同的结构。不同于普通RNN单元,这里是有四个,以一种非常特殊的方式进行交互。
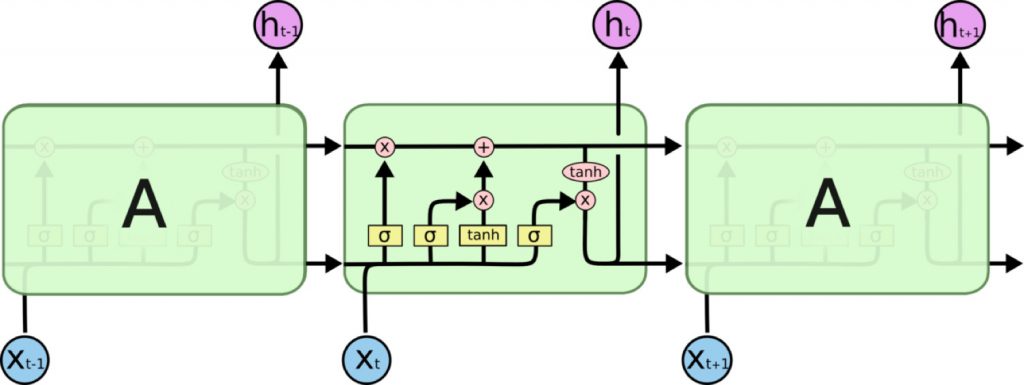
LSTM通过三个门结构(输入门,遗忘门,输出门),选择性地遗忘部分历史信息,加入部分当前输入信息,最终整合到当前状态并产生输出状态。
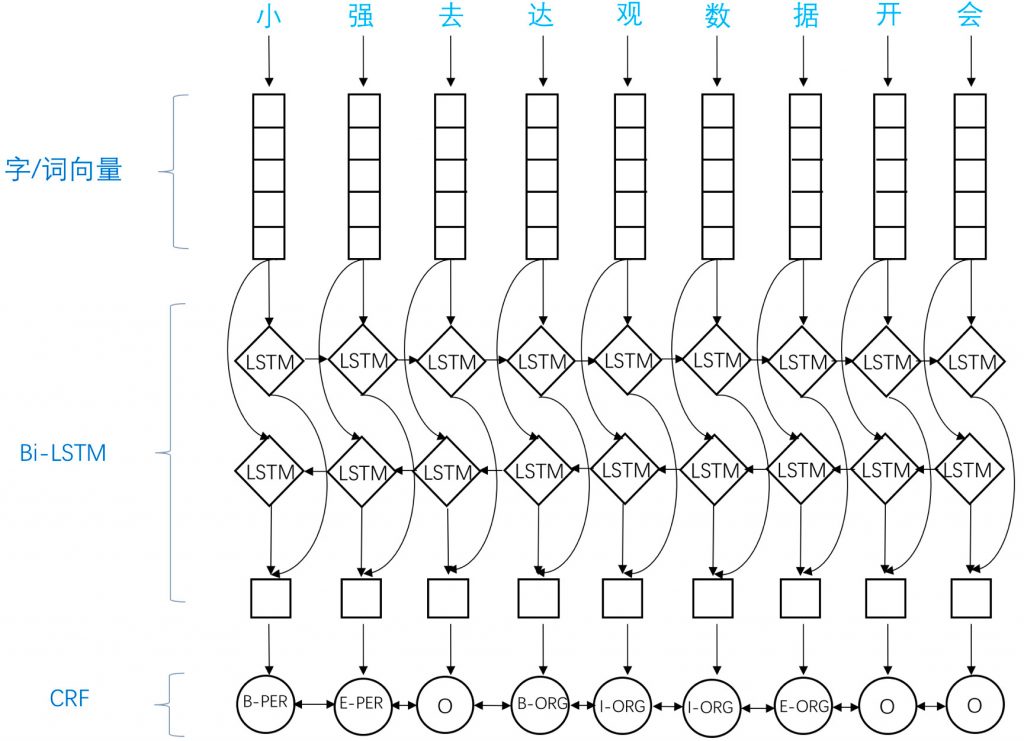
应用于NER中的biLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明biLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
2.2 IDCNN-CRF
对于序列标注来讲,普通CNN有一个不足,就是卷积之后,末层神经元可能只是得到了原始输入数据中一小块的信息。而对NER来讲,整个输入句子中每个字都有可能对当前位置的标注产生影响,即所谓的长距离依赖问题。为了覆盖到全部的输入信息就需要加入更多的卷积层,导致层数越来越深,参数越来越多。而为了防止过拟合又要加入更多的Dropout之类的正则化,带来更多的超参数,整个模型变得庞大且难以训练。因为CNN这样的劣势,对于大部分序列标注问题人们还是选择biLSTM之类的网络结构,尽可能利用网络的记忆力记住全句的信息来对当前字做标注。
但这又带来另外一个问题,biLSTM本质是一个序列模型,在对GPU并行计算的利用上不如CNN那么强大。如何能够像CNN那样给GPU提供一个火力全开的战场,而又像LSTM这样用简单的结构记住尽可能多的输入信息呢?
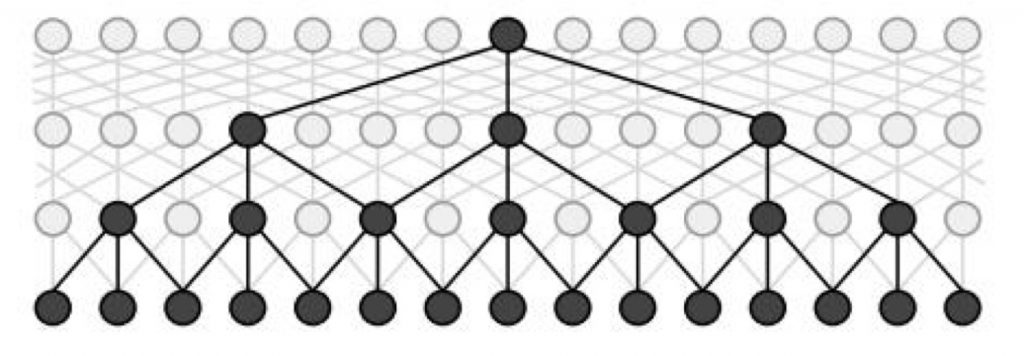
Fisher Yu and Vladlen Koltun 2015 提出了dilated CNN模型,意思是“膨胀的”CNN。其想法并不复杂:正常CNN的filter,都是作用在输入矩阵一片连续的区域上,不断sliding做卷积。dilated CNN为这个filter增加了一个dilation width,作用在输入矩阵的时候,会skip所有dilation width中间的输入数据;而filter本身的大小保持不变,这样filter获取到了更广阔的输入矩阵上的数据,看上去就像是“膨胀”了一般。
具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而receptive field却是指数增加的,可以很快覆盖到全部的输入数据。
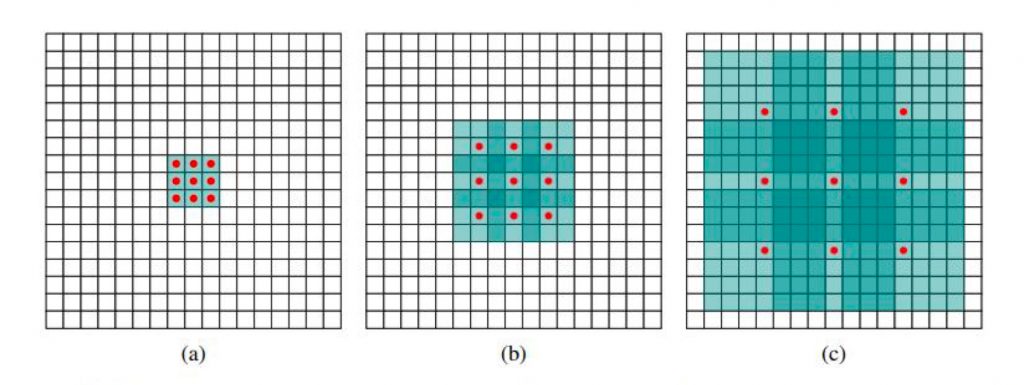
图7中可见感受域是以指数速率扩大的。原始感受域是位于中心点的1x1区域:
(a)图中经由原始感受域按步长为1向外扩散,得到8个1x1的区域构成新的感受域,大小为3x3;
(b)图中经过步长为2的扩散,上一步3x3的感受域扩展为为7x7;
(c)图中经步长为4的扩散,原7x7的感受域扩大为15x15的感受域。每一层的参数数量是相互独立的。感受域呈指数扩大,但参数数量呈线性增加。
对应在文本上,输入是一个一维的向量,每个元素是一个character embedding:
IDCNN对输入句子的每一个字生成一个logits,这里就和biLSTM模型输出logits完全一样,加入CRF层,用Viterbi算法解码出标注结果。
在biLSTM或者IDCNN这样的网络模型末端接上CRF层是序列标注的一个很常见的方法。biLSTM或者IDCNN计算出的是每个词的各标签概率,而CRF层引入序列的转移概率,最终计算出loss反馈回网络。
3. 实战应用
3.1 语料准备
Embedding:我们选择中文维基百科语料来训练字向量和词向量。
基础语料:选择人民日报1998年标注语料作为基础训练语料。
附加语料:98语料作为官方语料,其权威性与标注正确率是有保障的。但由于其完全取自人民日报,而且时间久远,所以对实体类型覆盖度比较低。比如新的公司名,外国人名,外国地名。为了提升对新类型实体的识别能力,我们收集了一批标注的新闻语料。主要包括财经、娱乐、体育,而这些正是98语料中比较缺少的。由于标注质量问题,额外语料不能加太多,约98语料的1/4。
3.2 数据增强
对于深度学习方法,一般需要大量标注语料,否则极易出现过拟合,无法达到预期的泛化能力。我们在实验中发现,通过数据增强可以明显提升模型性能。具体地,我们对原语料进行分句,然后随机地对各个句子进行bigram、trigram拼接,最后与原始句子一起作为训练语料。
另外,我们利用收集到的命名实体词典,采用随机替换的方式,用其替换语料中同类型的实体,得到增强语料。
下图给出了BiLSTM-CRF模型的训练曲线,可以看出收敛是很缓慢的。相对而言,IDCNN-CRF模型的收敛则快很多。
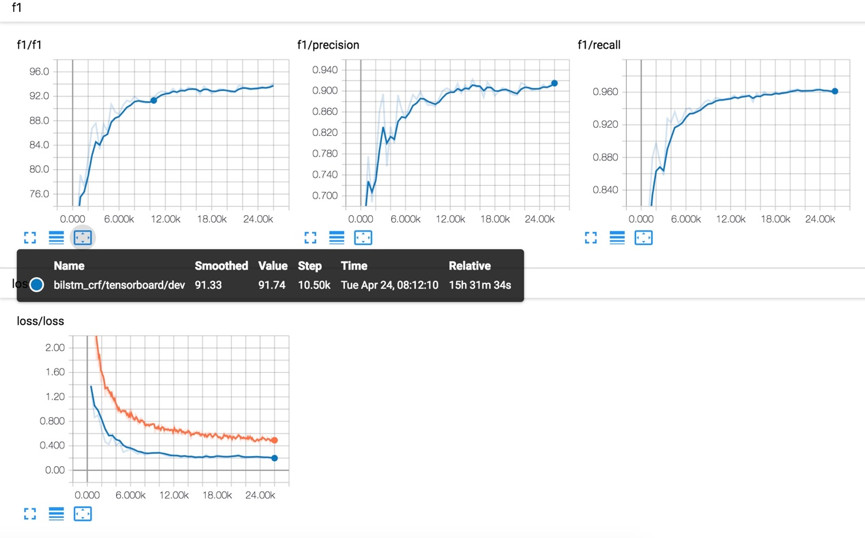
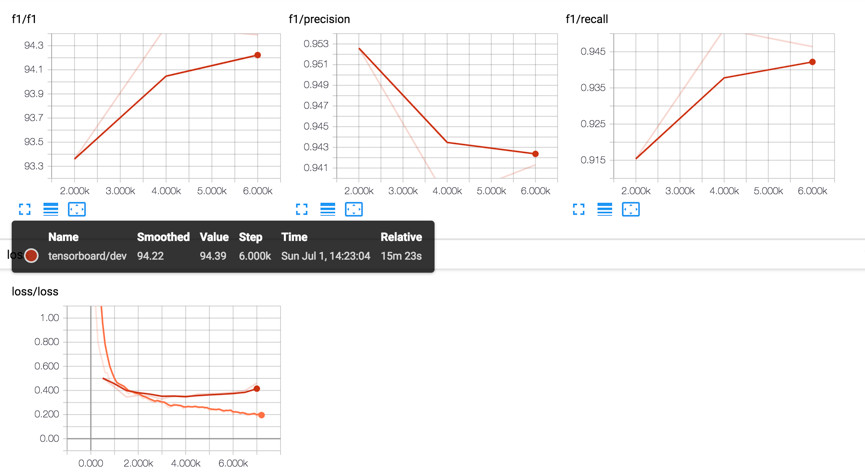
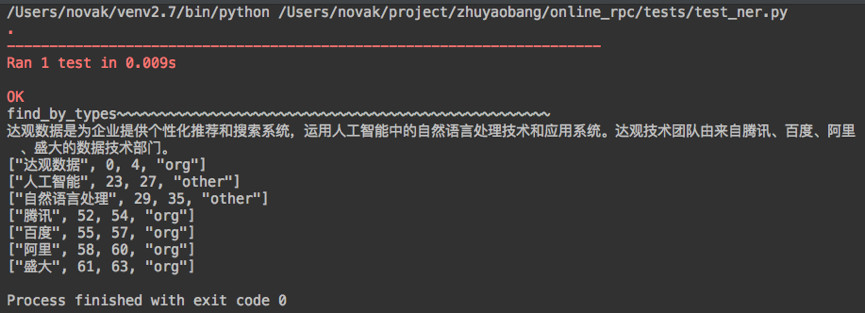
3.3 实例
以下是用BiLSTM-CRF模型的一个实例预测结果。
4. 总结
最后进行一下总结,将神经网络与CRF模型相结合的CNN/RNN-CRF成为了目前NER的主流模型。对于CNN与RNN,并没有谁占据绝对优势,各有各的优点。由于RNN有天然的序列结构,所以RNN-CRF使用更为广泛。基于神经网络结构的NER方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。对于少量标注训练集问题,迁移学习,半监督学习应该是未来研究的重点。
ABOUT
关于作者
朱耀邦:达观数据NLP算法工程师,负责达观数据NLP基础模块的研究、优化,以及NLP算法在文本挖掘系统中的具体应用。对深度学习、序列标注、实体及关系抽取有浓厚兴趣。
http://credit-n.ru/zaymyi-next.html
有对应的项目或者源码可以看吗
[回复]
同求项目代码
[回复]
求项目代码
[回复]
Alex 回复:
26 11 月, 2018 at 09:58
https://github.com/crownpku/Information-Extraction-Chinese/tree/master/NER_IDCNN_CRF
[回复]
何强 回复:
2 1 月, 2019 at 09:39
thankyou
[回复]
求数据
[回复]